 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Regularized Actor-Critic Algorithm for Bi-Level Reinforcement Learning
Jan 26, 2026We study a structured bi-level optimization problem where the upper-level objective is a smooth function and the lower-level problem is policy optimization in a Markov decision process (MDP). The upper-level decision variable parameterizes the reward of the lower-level MDP, and the upper-level objective depends on the optimal induced policy. Existing methods for bi-level optimization and RL often require second-order information, impose strong regularization at the lower level, or inefficiently use samples through nested-loop procedures. In this work, we propose a single-loop, first-order actor-critic algorithm that optimizes the bi-level objective via a penalty-based reformulation. We introduce into the lower-level RL objective an attenuating entropy regularization, which enables asymptotically unbiased upper-level hyper-gradient estimation without solving the unregularized RL problem exactly. We establish the finite-time and finite-sample convergence of the proposed algorithm to a stationary point of the original, unregularized bi-level optimization problem through a novel lower-level residual analysis under a special type of Polyak-Lojasiewicz condition. We validate the performance of our method through experiments on a GridWorld goal position problem and on happy tweet generation through reinforcement learning from human feedback (RLHF).
Learning in Stackelberg Mean Field Games: A Non-Asymptotic Analysis
Sep 18, 2025We study policy optimization in Stackelberg mean field games (MFGs), a hierarchical framework for modeling the strategic interaction between a single leader and an infinitely large population of homogeneous followers. The objective can be formulated as a structured bi-level optimization problem, in which the leader needs to learn a policy maximizing its reward, anticipating the response of the followers. Existing methods for solving these (and related) problems often rely on restrictive independence assumptions between the leader's and followers' objectives, use samples inefficiently due to nested-loop algorithm structure, and lack finite-time convergence guarantees. To address these limitations, we propose AC-SMFG, a single-loop actor-critic algorithm that operates on continuously generated Markovian samples. The algorithm alternates between (semi-)gradient updates for the leader, a representative follower, and the mean field, and is simple to implement in practice. We establish the finite-time and finite-sample convergence of the algorithm to a stationary point of the Stackelberg objective. To our knowledge, this is the first Stackelberg MFG algorithm with non-asymptotic convergence guarantees. Our key assumption is a "gradient alignment" condition, which requires that the full policy gradient of the leader can be approximated by a partial component of it, relaxing the existing leader-follower independence assumption. Simulation results in a range of well-established economics environments demonstrate that AC-SMFG outperforms existing multi-agent and MFG learning baselines in policy quality and convergence speed.
Catoni-Style Change Point Detection for Regret Minimization in Non-Stationary Heavy-Tailed Bandits
May 26, 2025Regret minimization in stochastic non-stationary bandits gained popularity over the last decade, as it can model a broad class of real-world problems, from advertising to recommendation systems. Existing literature relies on various assumptions about the reward-generating process, such as Bernoulli or subgaussian rewards. However, in settings such as finance and telecommunications, heavy-tailed distributions naturally arise. In this work, we tackle the heavy-tailed piecewise-stationary bandit problem. Heavy-tailed bandits, introduced by Bubeck et al., 2013, operate on the minimal assumption that the finite absolute centered moments of maximum order $1+\epsilon$ are uniformly bounded by a constant $v<+\infty$, for some $\epsilon \in (0,1]$. We focus on the most popular non-stationary bandit setting, i.e., the piecewise-stationary setting, in which the mean of reward-generating distributions may change at unknown time steps. We provide a novel Catoni-style change-point detection strategy tailored for heavy-tailed distributions that relies on recent advancements in the theory of sequential estimation, which is of independent interest. We introduce Robust-CPD-UCB, which combines this change-point detection strategy with optimistic algorithms for bandits, providing its regret upper bound and an impossibility result on the minimum attainable regret for any policy. Finally, we validate our approach through numerical experiments on synthetic and real-world datasets.
Collab: Controlled Decoding using Mixture of Agents for LLM Alignment
Mar 27, 2025Alignment of Large Language models (LLMs) is crucial for safe and trustworthy deployment in applications. Reinforcement learning from human feedback (RLHF) has emerged as an effective technique to align LLMs to human preferences and broader utilities, but it requires updating billions of model parameters, which is computationally expensive. Controlled Decoding, by contrast, provides a mechanism for aligning a model at inference time without retraining. However, single-agent decoding approaches often struggle to adapt to diverse tasks due to the complexity and variability inherent in these tasks. To strengthen the test-time performance w.r.t the target task, we propose a mixture of agent-based decoding strategies leveraging the existing off-the-shelf aligned LLM policies. Treating each prior policy as an agent in the spirit of mixture of agent collaboration, we develop a decoding method that allows for inference-time alignment through a token-level selection strategy among multiple agents. For each token, the most suitable LLM is dynamically chosen from a pool of models based on a long-term utility metric. This policy-switching mechanism ensures optimal model selection at each step, enabling efficient collaboration and alignment among LLMs during decoding. Theoretical analysis of our proposed algorithm establishes optimal performance with respect to the target task represented via a target reward for the given off-the-shelf models. We conduct comprehensive empirical evaluations with open-source aligned models on diverse tasks and preferences, which demonstrates the merits of this approach over single-agent decoding baselines. Notably, Collab surpasses the current SoTA decoding strategy, achieving an improvement of up to 1.56x in average reward and 71.89% in GPT-4 based win-tie rate.
Regularized Proportional Fairness Mechanism for Resource Allocation Without Money
Jan 02, 2025



Mechanism design in resource allocation studies dividing limited resources among self-interested agents whose satisfaction with the allocation depends on privately held utilities. We consider the problem in a payment-free setting, with the aim of maximizing social welfare while enforcing incentive compatibility (IC), i.e., agents cannot inflate allocations by misreporting their utilities. The well-known proportional fairness (PF) mechanism achieves the maximum possible social welfare but incurs an undesirably high exploitability (the maximum unilateral inflation in utility from misreport and a measure of deviation from IC). In fact, it is known that no mechanism can achieve the maximum social welfare and exact incentive compatibility (IC) simultaneously without the use of monetary incentives (Cole et al., 2013). Motivated by this fact, we propose learning an approximate mechanism that desirably trades off the competing objectives. Our main contribution is to design an innovative neural network architecture tailored to the resource allocation problem, which we name Regularized Proportional Fairness Network (RPF-Net). RPF-Net regularizes the output of the PF mechanism by a learned function approximator of the most exploitable allocation, with the aim of reducing the incentive for any agent to misreport. We derive generalization bounds that guarantee the mechanism performance when trained under finite and out-of-distribution samples and experimentally demonstrate the merits of the proposed mechanism compared to the state-of-the-art.
Approximate Equivariance in Reinforcement Learning
Nov 06, 2024Equivariant neural networks have shown great success in reinforcement learning, improving sample efficiency and generalization when there is symmetry in the task. However, in many problems, only approximate symmetry is present, which makes imposing exact symmetry inappropriate. Recently, approximately equivariant networks have been proposed for supervised classification and modeling physical systems. In this work, we develop approximately equivariant algorithms in reinforcement learning (RL). We define approximately equivariant MDPs and theoretically characterize the effect of approximate equivariance on the optimal Q function. We propose novel RL architectures using relaxed group convolutions and experiment on several continuous control domains and stock trading with real financial data. Our results demonstrate that approximate equivariance matches prior work when exact symmetries are present, and outperforms them when domains exhibit approximate symmetry. As an added byproduct of these techniques, we observe increased robustness to noise at test time.
Partially Observable Contextual Bandits with Linear Payoffs
Sep 17, 2024The standard contextual bandit framework assumes fully observable and actionable contexts. In this work, we consider a new bandit setting with partially observable, correlated contexts and linear payoffs, motivated by the applications in finance where decision making is based on market information that typically displays temporal correlation and is not fully observed. We make the following contributions marrying ideas from statistical signal processing with bandits: (i) We propose an algorithmic pipeline named EMKF-Bandit, which integrates system identification, filtering, and classic contextual bandit algorithms into an iterative method alternating between latent parameter estimation and decision making. (ii) We analyze EMKF-Bandit when we select Thompson sampling as the bandit algorithm and show that it incurs a sub-linear regret under conditions on filtering. (iii) We conduct numerical simulations that demonstrate the benefits and practical applicability of the proposed pipeline.
Near-Optimal Fair Resource Allocation for Strategic Agents without Money: A Data-Driven Approach
Nov 18, 2023



We study learning-based design of fair allocation mechanisms for divisible resources, using proportional fairness (PF) as a benchmark. The learning setting is a significant departure from the classic mechanism design literature, in that, we need to learn fair mechanisms solely from data. In particular, we consider the challenging problem of learning one-shot allocation mechanisms -- without the use of money -- that incentivize strategic agents to be truthful when reporting their valuations. It is well-known that the mechanism that directly seeks to optimize PF is not incentive compatible, meaning that the agents can potentially misreport their preferences to gain increased allocations. We introduce the notion of "exploitability" of a mechanism to measure the relative gain in utility from misreport, and make the following important contributions in the paper: (i) Using sophisticated techniques inspired by differentiable convex programming literature, we design a numerically efficient approach for computing the exploitability of the PF mechanism. This novel contribution enables us to quantify the gap that needs to be bridged to approximate PF via incentive compatible mechanisms. (ii) Next, we modify the PF mechanism to introduce a trade-off between fairness and exploitability. By properly controlling this trade-off using data, we show that our proposed mechanism, ExPF-Net, provides a strong approximation to the PF mechanism while maintaining low exploitability. This mechanism, however, comes with a high computational cost. (iii) To address the computational challenges, we propose another mechanism ExS-Net, which is end-to-end parameterized by a neural network. ExS-Net enjoys similar (slightly inferior) performance and significantly accelerated training and inference time performance. (iv) Extensive numerical simulations demonstrate the robustness and efficacy of the proposed mechanisms.
Oracle-free Reinforcement Learning in Mean-Field Games along a Single Sample Path
Aug 26, 2022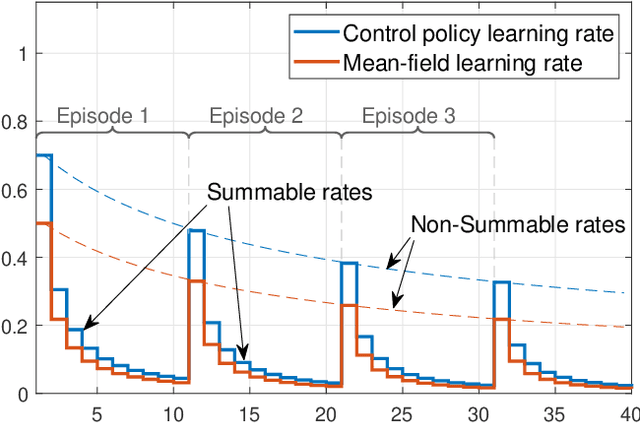
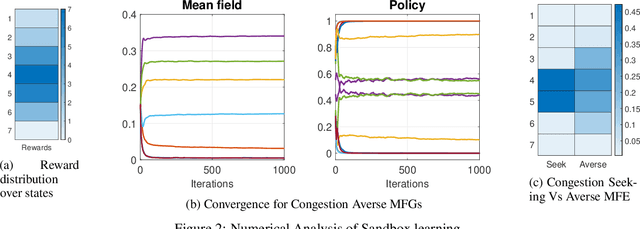
We consider online reinforcement learning in Mean-Field Games. In contrast to the existing works, we alleviate the need for a mean-field oracle by developing an algorithm that estimates the mean-field and the optimal policy using a single sample path of the generic agent. We call this Sandbox Learning, as it can be used as a warm-start for any agent operating in a multi-agent non-cooperative setting. We adopt a two timescale approach in which an online fixed-point recursion for the mean-field operates on a slower timescale and in tandem with a control policy update on a faster timescale for the generic agent. Under a sufficient exploration condition, we provide finite sample convergence guarantees in terms of convergence of the mean-field and control policy to the mean-field equilibrium. The sample complexity of the Sandbox learning algorithm is $\mathcal{O}(\epsilon^{-4})$. Finally, we empirically demonstrate effectiveness of the sandbox learning algorithm in a congestion game.
Catoni-style Confidence Sequences under Infinite Variance
Aug 05, 2022In this paper, we provide an extension of confidence sequences for settings where the variance of the data-generating distribution does not exist or is infinite. Confidence sequences furnish confidence intervals that are valid at arbitrary data-dependent stopping times, naturally having a wide range of applications. We first establish a lower bound for the width of the Catoni-style confidence sequences for the finite variance case to highlight the looseness of the existing results. Next, we derive tight Catoni-style confidence sequences for data distributions having a relaxed bounded~$p^{th}-$moment, where~$p \in (1,2]$, and strengthen the results for the finite variance case of~$p =2$. The derived results are shown to better than confidence sequences obtained using Dubins-Savage inequality.