 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Pose Forecasting
Human pose forecasting is the process of predicting the future poses or movements of people based on historical pose data.
Papers and Code
RAM: Recover Any 3D Human Motion in-the-Wild
Mar 20, 2026RAM incorporates a motion-aware semantic tracker with adaptive Kalman filtering to achieve robust identity association under severe occlusions and dynamic interactions. A memory-augmented Temporal HMR module further enhances human motion reconstruction by injecting spatio-temporal priors for consistent and smooth motion estimation. Moreover, a lightweight Predictor module forecasts future poses to maintain reconstruction continuity, while a gated combiner adaptively fuses reconstructed and predicted features to ensure coherence and robustness. Experiments on in-the-wild multi-person benchmarks such as PoseTrack and 3DPW, demonstrate that RAM substantially outperforms previous state-of-the-art in both Zero-shot tracking stability and 3D accuracy, offering a generalizable paradigm for markerless 3D human motion capture in-the-wild.
SimpliHuMoN: Simplifying Human Motion Prediction
Mar 04, 2026Human motion prediction combines the tasks of trajectory forecasting and human pose prediction. For each of the two tasks, specialized models have been developed. Combining these models for holistic human motion prediction is non-trivial, and recent methods have struggled to compete on established benchmarks for individual tasks. To address this, we propose a simple yet effective transformer-based model for human motion prediction. The model employs a stack of self-attention modules to effectively capture both spatial dependencies within a pose and temporal relationships across a motion sequence. This simple, streamlined, end-to-end model is sufficiently versatile to handle pose-only, trajectory-only, and combined prediction tasks without task-specific modifications. We demonstrate that this approach achieves state-of-the-art results across all tasks through extensive experiments on a wide range of benchmark datasets, including Human3.6M, AMASS, ETH-UCY, and 3DPW.
Legs Over Arms: On the Predictive Value of Lower-Body Pose for Human Trajectory Prediction from Egocentric Robot Perception
Feb 09, 2026Predicting human trajectory is crucial for social robot navigation in crowded environments. While most existing approaches treat human as point mass, we present a study on multi-agent trajectory prediction that leverages different human skeletal features for improved forecast accuracy. In particular, we systematically evaluate the predictive utility of 2D and 3D skeletal keypoints and derived biomechanical cues as additional inputs. Through a comprehensive study on the JRDB dataset and another new dataset for social navigation with 360-degree panoramic videos, we find that focusing on lower-body 3D keypoints yields a 13% reduction in Average Displacement Error and augmenting 3D keypoint inputs with corresponding biomechanical cues provides a further 1-4% improvement. Notably, the performance gain persists when using 2D keypoint inputs extracted from equirectangular panoramic images, indicating that monocular surround vision can capture informative cues for motion forecasting. Our finding that robots can forecast human movement efficiently by watching their legs provides actionable insights for designing sensing capabilities for social robot navigation.
Mining Citywide Dengue Spread Patterns in Singapore Through Hotspot Dynamics from Open Web Data
Jan 19, 2026Dengue, a mosquito-borne disease, continues to pose a persistent public health challenge in urban areas, particularly in tropical regions such as Singapore. Effective and affordable control requires anticipating where transmission risks are likely to emerge so that interventions can be deployed proactively rather than reactively. This study introduces a novel framework that uncovers and exploits latent transmission links between urban regions, mined directly from publicly available dengue case data. Instead of treating cases as isolated reports, we model how hotspot formation in one area is influenced by epidemic dynamics in neighboring regions. While mosquito movement is highly localized, long-distance transmission is often driven by human mobility, and in our case study, the learned network aligns closely with commuting flows, providing an interpretable explanation for citywide spread. These hidden links are optimized through gradient descent and used not only to forecast hotspot status but also to verify the consistency of spreading patterns, by examining the stability of the inferred network across consecutive weeks. Case studies on Singapore during 2013-2018 and 2020 show that four weeks of hotspot history are sufficient to achieve an average F-score of 0.79. Importantly, the learned transmission links align with commuting flows, highlighting the interpretable interplay between hidden epidemic spread and human mobility. By shifting from simply reporting dengue cases to mining and validating hidden spreading dynamics, this work transforms open web-based case data into a predictive and explanatory resource. The proposed framework advances epidemic modeling while providing a scalable, low-cost tool for public health planning, early intervention, and urban resilience.
* 9 pages, 9 figures. It's accepted by WWW 2026 Web4Good Track. To make accessible earlier, authors would like to put it on arxiv before the conference
Scriboora: Rethinking Human Pose Forecasting
Nov 19, 2025



Human pose forecasting predicts future poses based on past observations, and has many significant applications in areas such as action recognition, autonomous driving or human-robot interaction. This paper evaluates a wide range of pose forecasting algorithms in the task of absolute pose forecasting, revealing many reproducibility issues, and provides a unified training and evaluation pipeline. After drawing a high-level analogy to the task of speech understanding, it is shown that recent speech models can be efficiently adapted to the task of pose forecasting, and improve current state-of-the-art performance. At last the robustness of the models is evaluated, using noisy joint coordinates obtained from a pose estimator model, to reflect a realistic type of noise, which is more close to real-world applications. For this a new dataset variation is introduced, and it is shown that estimated poses result in a substantial performance degradation, and how much of it can be recovered again by unsupervised finetuning.
Supporting Migration Policies with Forecasts: Illegal Border Crossings in Europe through a Mixed Approach
Dec 16, 2025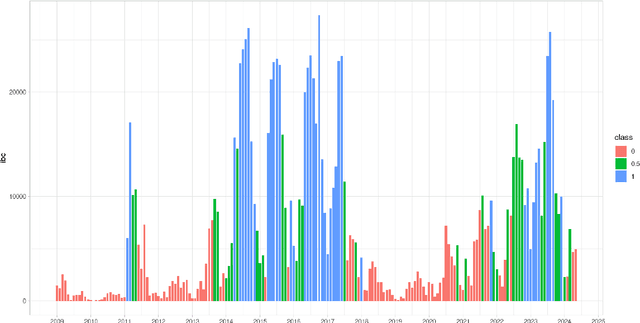
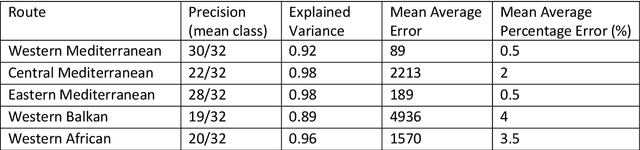
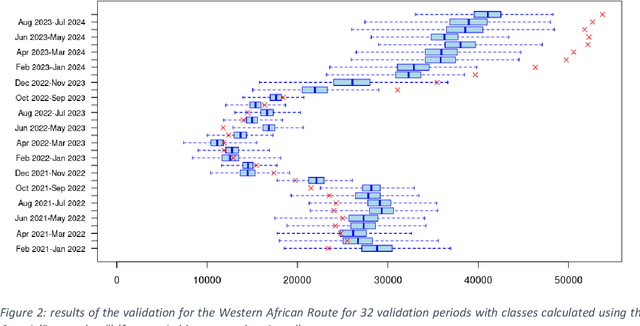
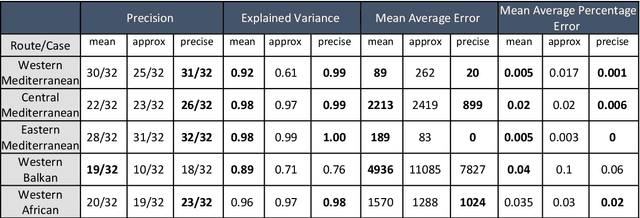
This paper presents a mixed-methodology to forecast illegal border crossings in Europe across five key migratory routes, with a one-year time horizon. The methodology integrates machine learning techniques with qualitative insights from migration experts. This approach aims at improving the predictive capacity of data-driven models through the inclusion of a human-assessed covariate, an innovation that addresses challenges posed by sudden shifts in migration patterns and limitations in traditional datasets. The proposed methodology responds directly to the forecasting needs outlined in the EU Pact on Migration and Asylum, supporting the Asylum and Migration Management Regulation (AMMR). It is designed to provide policy-relevant forecasts that inform strategic decisions, early warning systems, and solidarity mechanisms among EU Member States. By joining data-driven modeling with expert judgment, this work aligns with existing academic recommendations and introduces a novel operational tool tailored for EU migration governance. The methodology is tested and validated with known data to demonstrate its applicability and reliability in migration-related policy context.
MiVLA: Towards Generalizable Vision-Language-Action Model with Human-Robot Mutual Imitation Pre-training
Dec 19, 2025While leveraging abundant human videos and simulated robot data poses a scalable solution to the scarcity of real-world robot data, the generalization capability of existing vision-language-action models (VLAs) remains limited by mismatches in camera views, visual appearance, and embodiment morphologies. To overcome this limitation, we propose MiVLA, a generalizable VLA empowered by human-robot mutual imitation pre-training, which leverages inherent behavioral similarity between human hands and robotic arms to build a foundation of strong behavioral priors for both human actions and robotic control. Specifically, our method utilizes kinematic rules with left/right hand coordinate systems for bidirectional alignment between human and robot action spaces. Given human or simulated robot demonstrations, MiVLA is trained to forecast behavior trajectories for one embodiment, and imitate behaviors for another one unseen in the demonstration. Based on this mutual imitation, it integrates the behavioral fidelity of real-world human data with the manipulative diversity of simulated robot data into a unified model, thereby enhancing the generalization capability for downstream tasks. Extensive experiments conducted on both simulation and real-world platforms with three robots (ARX, PiPer and LocoMan), demonstrate that MiVLA achieves strong improved generalization capability, outperforming state-of-the-art VLAs (e.g., $\boldsymbolπ_{0}$, $\boldsymbolπ_{0.5}$ and H-RDT) by 25% in simulation, and 14% in real-world robot control tasks.
Early Warning Index for Patient Deteriorations in Hospitals
Dec 16, 2025



Hospitals lack automated systems to harness the growing volume of heterogeneous clinical and operational data to effectively forecast critical events. Early identification of patients at risk for deterioration is essential not only for patient care quality monitoring but also for physician care management. However, translating varied data streams into accurate and interpretable risk assessments poses significant challenges due to inconsistent data formats. We develop a multimodal machine learning framework, the Early Warning Index (EWI), to predict the aggregate risk of ICU admission, emergency response team dispatch, and mortality. Key to EWI's design is a human-in-the-loop process: clinicians help determine alert thresholds and interpret model outputs, which are enhanced by explainable outputs using Shapley Additive exPlanations (SHAP) to highlight clinical and operational factors (e.g., scheduled surgeries, ward census) driving each patient's risk. We deploy EWI in a hospital dashboard that stratifies patients into three risk tiers. Using a dataset of 18,633 unique patients at a large U.S. hospital, our approach automatically extracts features from both structured and unstructured electronic health record (EHR) data and achieves C-statistics of 0.796. It is currently used as a triage tool for proactively managing at-risk patients. The proposed approach saves physicians valuable time by automatically sorting patients of varying risk levels, allowing them to concentrate on patient care rather than sifting through complex EHR data. By further pinpointing specific risk drivers, the proposed model provides data-informed adjustments to caregiver scheduling and allocation of critical resources. As a result, clinicians and administrators can avert downstream complications, including costly procedures or high readmission rates and improve overall patient flow.
MAT-MPNN: A Mobility-Aware Transformer-MPNN Model for Dynamic Spatiotemporal Prediction of HIV Diagnoses in California, Florida, and New England
Nov 17, 2025Human Immunodeficiency Virus (HIV) has posed a major global health challenge for decades, and forecasting HIV diagnoses continues to be a critical area of research. However, capturing the complex spatial and temporal dependencies of HIV transmission remains challenging. Conventional Message Passing Neural Network (MPNN) models rely on a fixed binary adjacency matrix that only encodes geographic adjacency, which is unable to represent interactions between non-contiguous counties. Our study proposes a deep learning architecture Mobility-Aware Transformer-Message Passing Neural Network (MAT-MPNN) framework to predict county-level HIV diagnosis rates across California, Florida, and the New England region. The model combines temporal features extracted by a Transformer encoder with spatial relationships captured through a Mobility Graph Generator (MGG). The MGG improves conventional adjacency matrices by combining geographic and demographic information. Compared with the best-performing hybrid baseline, the Transformer MPNN model, MAT-MPNN reduced the Mean Squared Prediction Error (MSPE) by 27.9% in Florida, 39.1% in California, and 12.5% in New England, and improved the Predictive Model Choice Criterion (PMCC) by 7.7%, 3.5%, and 3.9%, respectively. MAT-MPNN also achieved better results than the Spatially Varying Auto-Regressive (SVAR) model in Florida and New England, with comparable performance in California. These results demonstrate that applying mobility-aware dynamic spatial structures substantially enhances predictive accuracy and calibration in spatiotemporal epidemiological prediction.
Breaking the Passive Learning Trap: An Active Perception Strategy for Human Motion Prediction
Nov 18, 2025Forecasting 3D human motion is an important embodiment of fine-grained understanding and cognition of human behavior by artificial agents. Current approaches excessively rely on implicit network modeling of spatiotemporal relationships and motion characteristics, falling into the passive learning trap that results in redundant and monotonous 3D coordinate information acquisition while lacking actively guided explicit learning mechanisms. To overcome these issues, we propose an Active Perceptual Strategy (APS) for human motion prediction, leveraging quotient space representations to explicitly encode motion properties while introducing auxiliary learning objectives to strengthen spatio-temporal modeling. Specifically, we first design a data perception module that projects poses into the quotient space, decoupling motion geometry from coordinate redundancy. By jointly encoding tangent vectors and Grassmann projections, this module simultaneously achieves geometric dimension reduction, semantic decoupling, and dynamic constraint enforcement for effective motion pose characterization. Furthermore, we introduce a network perception module that actively learns spatio-temporal dependencies through restorative learning. This module deliberately masks specific joints or injects noise to construct auxiliary supervision signals. A dedicated auxiliary learning network is designed to actively adapt and learn from perturbed information. Notably, APS is model agnostic and can be integrated with different prediction models to enhance active perceptual. The experimental results demonstrate that our method achieves the new state-of-the-art, outperforming existing methods by large margins: 16.3% on H3.6M, 13.9% on CMU Mocap, and 10.1% on 3DPW.