 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepmind Control Suite
Papers and Code
Reward Learning through Ranking Mean Squared Error
Jan 15, 2026Reward design remains a significant bottleneck in applying reinforcement learning (RL) to real-world problems. A popular alternative is reward learning, where reward functions are inferred from human feedback rather than manually specified. Recent work has proposed learning reward functions from human feedback in the form of ratings, rather than traditional binary preferences, enabling richer and potentially less cognitively demanding supervision. Building on this paradigm, we introduce a new rating-based RL method, Ranked Return Regression for RL (R4). At its core, R4 employs a novel ranking mean squared error (rMSE) loss, which treats teacher-provided ratings as ordinal targets. Our approach learns from a dataset of trajectory-rating pairs, where each trajectory is labeled with a discrete rating (e.g., "bad," "neutral," "good"). At each training step, we sample a set of trajectories, predict their returns, and rank them using a differentiable sorting operator (soft ranks). We then optimize a mean squared error loss between the resulting soft ranks and the teacher's ratings. Unlike prior rating-based approaches, R4 offers formal guarantees: its solution set is provably minimal and complete under mild assumptions. Empirically, using simulated human feedback, we demonstrate that R4 consistently matches or outperforms existing rating and preference-based RL methods on robotic locomotion benchmarks from OpenAI Gym and the DeepMind Control Suite, while requiring significantly less feedback.
Spectral Representation-based Reinforcement Learning
Dec 17, 2025In real-world applications with large state and action spaces, reinforcement learning (RL) typically employs function approximations to represent core components like the policies, value functions, and dynamics models. Although powerful approximations such as neural networks offer great expressiveness, they often present theoretical ambiguities, suffer from optimization instability and exploration difficulty, and incur substantial computational costs in practice. In this paper, we introduce the perspective of spectral representations as a solution to address these difficulties in RL. Stemming from the spectral decomposition of the transition operator, this framework yields an effective abstraction of the system dynamics for subsequent policy optimization while also providing a clear theoretical characterization. We reveal how to construct spectral representations for transition operators that possess latent variable structures or energy-based structures, which implies different learning methods to extract spectral representations from data. Notably, each of these learning methods realizes an effective RL algorithm under this framework. We also provably extend this spectral view to partially observable MDPs. Finally, we validate these algorithms on over 20 challenging tasks from the DeepMind Control Suite, where they achieve performances comparable or superior to current state-of-the-art model-free and model-based baselines.
Latent Action World Models for Control with Unlabeled Trajectories
Dec 10, 2025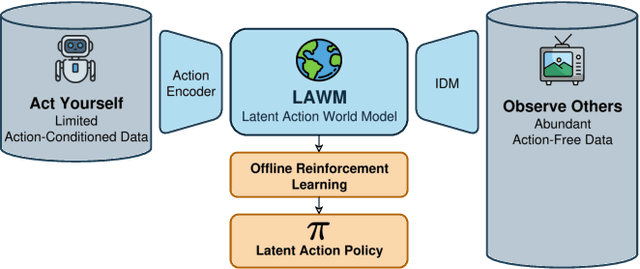
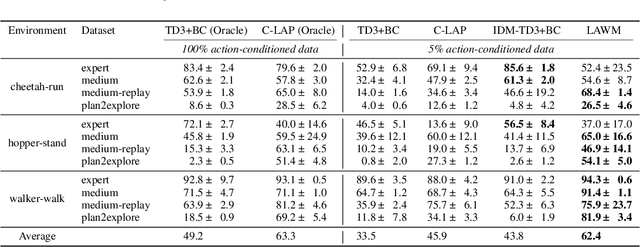
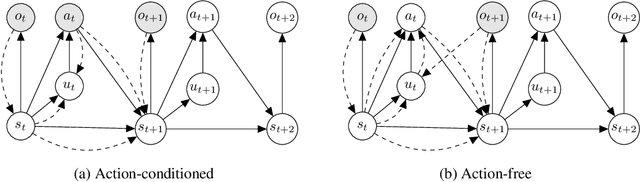

Inspired by how humans combine direct interaction with action-free experience (e.g., videos), we study world models that learn from heterogeneous data. Standard world models typically rely on action-conditioned trajectories, which limits effectiveness when action labels are scarce. We introduce a family of latent-action world models that jointly use action-conditioned and action-free data by learning a shared latent action representation. This latent space aligns observed control signals with actions inferred from passive observations, enabling a single dynamics model to train on large-scale unlabeled trajectories while requiring only a small set of action-labeled ones. We use the latent-action world model to learn a latent-action policy through offline reinforcement learning (RL), thereby bridging two traditionally separate domains: offline RL, which typically relies on action-conditioned data, and action-free training, which is rarely used with subsequent RL. On the DeepMind Control Suite, our approach achieves strong performance while using about an order of magnitude fewer action-labeled samples than purely action-conditioned baselines. These results show that latent actions enable training on both passive and interactive data, which makes world models learn more efficiently.
KAN-Dreamer: Benchmarking Kolmogorov-Arnold Networks as Function Approximators in World Models
Dec 08, 2025DreamerV3 is a state-of-the-art online model-based reinforcement learning (MBRL) algorithm known for remarkable sample efficiency. Concurrently, Kolmogorov-Arnold Networks (KANs) have emerged as a promising alternative to Multi-Layer Perceptrons (MLPs), offering superior parameter efficiency and interpretability. To mitigate KANs' computational overhead, variants like FastKAN leverage Radial Basis Functions (RBFs) to accelerate inference. In this work, we investigate integrating KAN architectures into the DreamerV3 framework. We introduce KAN-Dreamer, replacing specific MLP and convolutional components of DreamerV3 with KAN and FastKAN layers. To ensure efficiency within the JAX-based World Model, we implement a tailored, fully vectorized version with simplified grid management. We structure our investigation into three subsystems: Visual Perception, Latent Prediction, and Behavior Learning. Empirical evaluations on the DeepMind Control Suite (walker_walk) analyze sample efficiency, training time, and asymptotic performance. Experimental results demonstrate that utilizing our adapted FastKAN as a drop-in replacement for the Reward and Continue predictors yields performance on par with the original MLP-based architecture, maintaining parity in both sample efficiency and training speed. This report serves as a preliminary study for future developments in KAN-based world models.
Test-driven Reinforcement Learning
Nov 15, 2025



Reinforcement learning (RL) has been recognized as a powerful tool for robot control tasks. RL typically employs reward functions to define task objectives and guide agent learning. However, since the reward function serves the dual purpose of defining the optimal goal and guiding learning, it is challenging to design the reward function manually, which often results in a suboptimal task representation. To tackle the reward design challenge in RL, inspired by the satisficing theory, we propose a Test-driven Reinforcement Learning (TdRL) framework. In the TdRL framework, multiple test functions are used to represent the task objective rather than a single reward function. Test functions can be categorized as pass-fail tests and indicative tests, each dedicated to defining the optimal objective and guiding the learning process, respectively, thereby making defining tasks easier. Building upon such a task definition, we first prove that if a trajectory return function assigns higher returns to trajectories closer to the optimal trajectory set, maximum entropy policy optimization based on this return function will yield a policy that is closer to the optimal policy set. Then, we introduce a lexicographic heuristic approach to compare the relative distance relationship between trajectories and the optimal trajectory set for learning the trajectory return function. Furthermore, we develop an algorithm implementation of TdRL. Experimental results on the DeepMind Control Suite benchmark demonstrate that TdRL matches or outperforms handcrafted reward methods in policy training, with greater design simplicity and inherent support for multi-objective optimization. We argue that TdRL offers a novel perspective for representing task objectives, which could be helpful in addressing the reward design challenges in RL applications.
Fixing That Free Lunch: When, Where, and Why Synthetic Data Fails in Model-Based Policy Optimization
Oct 01, 2025Synthetic data is a core component of data-efficient Dyna-style model-based reinforcement learning, yet it can also degrade performance. We study when it helps, where it fails, and why, and we show that addressing the resulting failure modes enables policy improvement that was previously unattainable. We focus on Model-Based Policy Optimization (MBPO), which performs actor and critic updates using synthetic action counterfactuals. Despite reports of strong and generalizable sample-efficiency gains in OpenAI Gym, recent work shows that MBPO often underperforms its model-free counterpart, Soft Actor-Critic (SAC), in the DeepMind Control Suite (DMC). Although both suites involve continuous control with proprioceptive robots, this shift leads to sharp performance losses across seven challenging DMC tasks, with MBPO failing in cases where claims of generalization from Gym would imply success. This reveals how environment-specific assumptions can become implicitly encoded into algorithm design when evaluation is limited. We identify two coupled issues behind these failures: scale mismatches between dynamics and reward models that induce critic underestimation and hinder policy improvement during model-policy coevolution, and a poor choice of target representation that inflates model variance and produces error-prone rollouts. Addressing these failure modes enables policy improvement where none was previously possible, allowing MBPO to outperform SAC in five of seven tasks while preserving the strong performance previously reported in OpenAI Gym. Rather than aiming only for incremental average gains, we hope our findings motivate the community to develop taxonomies that tie MDP task- and environment-level structure to algorithmic failure modes, pursue unified solutions where possible, and clarify how benchmark choices ultimately shape the conditions under which algorithms generalize.
The Courage to Stop: Overcoming Sunk Cost Fallacy in Deep Reinforcement Learning
Jun 16, 2025



Off-policy deep reinforcement learning (RL) typically leverages replay buffers for reusing past experiences during learning. This can help improve sample efficiency when the collected data is informative and aligned with the learning objectives; when that is not the case, it can have the effect of "polluting" the replay buffer with data which can exacerbate optimization challenges in addition to wasting environment interactions due to wasteful sampling. We argue that sampling these uninformative and wasteful transitions can be avoided by addressing the sunk cost fallacy, which, in the context of deep RL, is the tendency towards continuing an episode until termination. To address this, we propose learn to stop (LEAST), a lightweight mechanism that enables strategic early episode termination based on Q-value and gradient statistics, which helps agents recognize when to terminate unproductive episodes early. We demonstrate that our method improves learning efficiency on a variety of RL algorithms, evaluated on both the MuJoCo and DeepMind Control Suite benchmarks.
Dream to Generalize: Zero-Shot Model-Based Reinforcement Learning for Unseen Visual Distractions
Jun 05, 2025



Model-based reinforcement learning (MBRL) has been used to efficiently solve vision-based control tasks in highdimensional image observations. Although recent MBRL algorithms perform well in trained observations, they fail when faced with visual distractions in observations. These task-irrelevant distractions (e.g., clouds, shadows, and light) may be constantly present in real-world scenarios. In this study, we propose a novel self-supervised method, Dream to Generalize (Dr. G), for zero-shot MBRL. Dr. G trains its encoder and world model with dual contrastive learning which efficiently captures task-relevant features among multi-view data augmentations. We also introduce a recurrent state inverse dynamics model that helps the world model to better understand the temporal structure. The proposed methods can enhance the robustness of the world model against visual distractions. To evaluate the generalization performance, we first train Dr. G on simple backgrounds and then test it on complex natural video backgrounds in the DeepMind Control suite, and the randomizing environments in Robosuite. Dr. G yields a performance improvement of 117% and 14% over prior works, respectively. Our code is open-sourced and available at https://github.com/JeongsooHa/DrG.git
MRSD: Multi-Resolution Skill Discovery for HRL Agents
May 27, 2025Hierarchical reinforcement learning (HRL) relies on abstract skills to solve long-horizon tasks efficiently. While existing skill discovery methods learns these skills automatically, they are limited to a single skill per task. In contrast, humans learn and use both fine-grained and coarse motor skills simultaneously. Inspired by human motor control, we propose Multi-Resolution Skill Discovery (MRSD), an HRL framework that learns multiple skill encoders at different temporal resolutions in parallel. A high-level manager dynamically selects among these skills, enabling adaptive control strategies over time. We evaluate MRSD on tasks from the DeepMind Control Suite and show that it outperforms prior state-of-the-art skill discovery and HRL methods, achieving faster convergence and higher final performance. Our findings highlight the benefits of integrating multi-resolution skills in HRL, paving the way for more versatile and efficient agents.
Measure gradients, not activations! Enhancing neuronal activity in deep reinforcement learning
May 29, 2025Deep reinforcement learning (RL) agents frequently suffer from neuronal activity loss, which impairs their ability to adapt to new data and learn continually. A common method to quantify and address this issue is the tau-dormant neuron ratio, which uses activation statistics to measure the expressive ability of neurons. While effective for simple MLP-based agents, this approach loses statistical power in more complex architectures. To address this, we argue that in advanced RL agents, maintaining a neuron's learning capacity, its ability to adapt via gradient updates, is more critical than preserving its expressive ability. Based on this insight, we shift the statistical objective from activations to gradients, and introduce GraMa (Gradient Magnitude Neural Activity Metric), a lightweight, architecture-agnostic metric for quantifying neuron-level learning capacity. We show that GraMa effectively reveals persistent neuron inactivity across diverse architectures, including residual networks, diffusion models, and agents with varied activation functions. Moreover, resetting neurons guided by GraMa (ReGraMa) consistently improves learning performance across multiple deep RL algorithms and benchmarks, such as MuJoCo and the DeepMind Control Suite.