 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOLLM: Options-based Large Language Models
Apr 21, 2026We introduce Options LLM (OLLM), a simple, general method that replaces the single next-token prediction of standard LLMs with a \textit{set of learned options} for the next token, indexed by a discrete latent variable. Instead of relying on temperature or sampling heuristics to induce diversity, OLLM models variation explicitly: a small latent space parametrizes multiple plausible next-token options which can be selected or searched by a downstream policy. Architecturally, OLLM is a lightweight "plug-in" that inserts two layers: an encoder and a decoder, before the output head, allowing almost any pretrained LLM to be converted with minimal additional parameters. We apply OLLM to a 1.7B-parameter backbone (only $1.56\%$ of parameters trainable) trained on OpenMathReasoning and evaluated on OmniMath. The SOTA LoRA-adapted baselines peak at $51\%$ final answer correctness, while OLLM's option set allows up to $\sim 70\%$ under optimal latent selection. We then train a compact policy in the latent space that emits latents to control generation. Operating in a low-dimensional option space makes reward optimization far more sample-efficient and substantially reduces common misalignments (e.g., language switching or degenerate reasoning), as the policy is constrained to options learned during SFT. Crucially, this alignment arises from model structure rather than additional KL or handcrafted alignment losses. Our results demonstrate that optionized next-token modeling enhances controllability, robustness, and efficiency in math reasoning, and highlight latent-space policy learning as a promising direction for reinforcement learning in LLMs.
MRSD: Multi-Resolution Skill Discovery for HRL Agents
May 27, 2025Hierarchical reinforcement learning (HRL) relies on abstract skills to solve long-horizon tasks efficiently. While existing skill discovery methods learns these skills automatically, they are limited to a single skill per task. In contrast, humans learn and use both fine-grained and coarse motor skills simultaneously. Inspired by human motor control, we propose Multi-Resolution Skill Discovery (MRSD), an HRL framework that learns multiple skill encoders at different temporal resolutions in parallel. A high-level manager dynamically selects among these skills, enabling adaptive control strategies over time. We evaluate MRSD on tasks from the DeepMind Control Suite and show that it outperforms prior state-of-the-art skill discovery and HRL methods, achieving faster convergence and higher final performance. Our findings highlight the benefits of integrating multi-resolution skills in HRL, paving the way for more versatile and efficient agents.
3D Characterization of Smoke Plume Dispersion Using Multi-View Drone Swarm
May 10, 2025



This study presents an advanced multi-view drone swarm imaging system for the three-dimensional characterization of smoke plume dispersion dynamics. The system comprises a manager drone and four worker drones, each equipped with high-resolution cameras and precise GPS modules. The manager drone uses image feedback to autonomously detect and position itself above the plume, then commands the worker drones to orbit the area in a synchronized circular flight pattern, capturing multi-angle images. The camera poses of these images are first estimated, then the images are grouped in batches and processed using Neural Radiance Fields (NeRF) to generate high-resolution 3D reconstructions of plume dynamics over time. Field tests demonstrated the ability of the system to capture critical plume characteristics including volume dynamics, wind-driven directional shifts, and lofting behavior at a temporal resolution of about 1 s. The 3D reconstructions generated by this system provide unique field data for enhancing the predictive models of smoke plume dispersion and fire spread. Broadly, the drone swarm system offers a versatile platform for high resolution measurements of pollutant emissions and transport in wildfires, volcanic eruptions, prescribed burns, and industrial processes, ultimately supporting more effective fire control decisions and mitigating wildfire risks.
Autonomous Drone for Dynamic Smoke Plume Tracking
Apr 17, 2025This paper presents a novel autonomous drone-based smoke plume tracking system capable of navigating and tracking plumes in highly unsteady atmospheric conditions. The system integrates advanced hardware and software and a comprehensive simulation environment to ensure robust performance in controlled and real-world settings. The quadrotor, equipped with a high-resolution imaging system and an advanced onboard computing unit, performs precise maneuvers while accurately detecting and tracking dynamic smoke plumes under fluctuating conditions. Our software implements a two-phase flight operation, i.e., descending into the smoke plume upon detection and continuously monitoring the smoke movement during in-plume tracking. Leveraging Proportional Integral-Derivative (PID) control and a Proximal Policy Optimization based Deep Reinforcement Learning (DRL) controller enables adaptation to plume dynamics. Unreal Engine simulation evaluates performance under various smoke-wind scenarios, from steady flow to complex, unsteady fluctuations, showing that while the PID controller performs adequately in simpler scenarios, the DRL-based controller excels in more challenging environments. Field tests corroborate these findings. This system opens new possibilities for drone-based monitoring in areas like wildfire management and air quality assessment. The successful integration of DRL for real-time decision-making advances autonomous drone control for dynamic environments.
DHP: Discrete Hierarchical Planning for Hierarchical Reinforcement Learning Agents
Feb 04, 2025In this paper, we address the challenge of long-horizon visual planning tasks using Hierarchical Reinforcement Learning (HRL). Our key contribution is a Discrete Hierarchical Planning (DHP) method, an alternative to traditional distance-based approaches. We provide theoretical foundations for the method and demonstrate its effectiveness through extensive empirical evaluations. Our agent recursively predicts subgoals in the context of a long-term goal and receives discrete rewards for constructing plans as compositions of abstract actions. The method introduces a novel advantage estimation strategy for tree trajectories, which inherently encourages shorter plans and enables generalization beyond the maximum tree depth. The learned policy function allows the agent to plan efficiently, requiring only $\log N$ computational steps, making re-planning highly efficient. The agent, based on a soft-actor critic (SAC) framework, is trained using on-policy imagination data. Additionally, we propose a novel exploration strategy that enables the agent to generate relevant training examples for the planning modules. We evaluate our method on long-horizon visual planning tasks in a 25-room environment, where it significantly outperforms previous benchmarks at success rate and average episode length. Furthermore, an ablation study highlights the individual contributions of key modules to the overall performance.
Advanced Smart City Monitoring: Real-Time Identification of Indian Citizen Attributes
Jul 05, 2024This project focuses on creating a smart surveillance system for Indian cities that can identify and analyze people's attributes in real time. Using advanced technologies like artificial intelligence and machine learning, the system can recognize attributes such as upper body color, what the person is wearing, accessories they are wearing, headgear, etc., and analyze behavior through cameras installed around the city.
Smart City Surveillance Unveiling Indian Person Attributes in Real Time
Jul 03, 2024This project focuses on creating a smart surveillance system for Indian cities that can identify and analyze people's attributes in real time. Using advanced technologies like artificial intelligence and machine learning, the system can recognize attributes such as upper body color, what the person is wearing, accessories they are wearing, headgear, etc., and analyze behavior through cameras installed around the city.
Evaluating Self and Semi-Supervised Methods for Remote Sensing Segmentation Tasks
Nov 19, 2021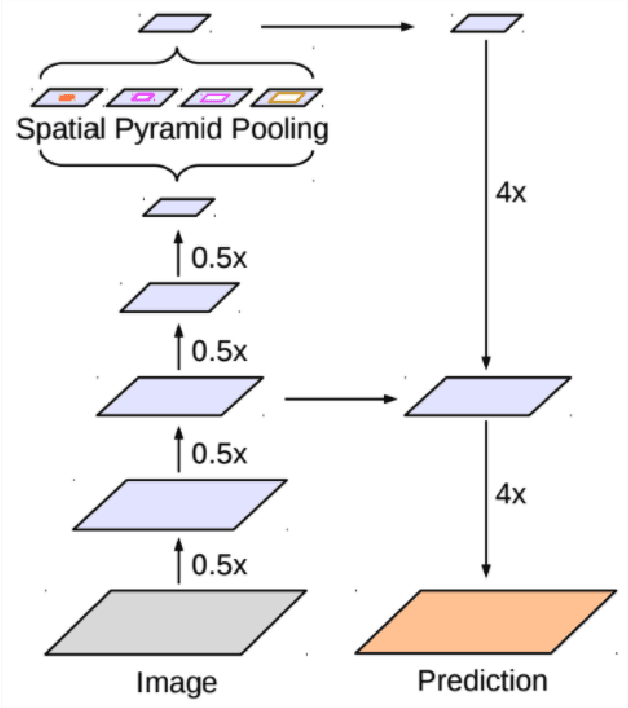
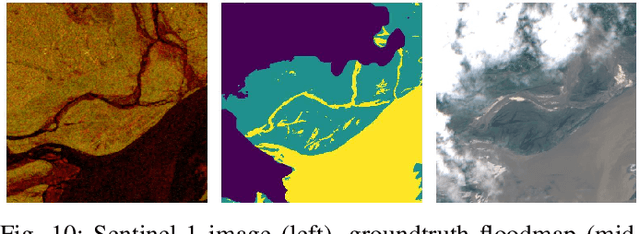


We perform a rigorous evaluation of recent self and semi-supervised ML techniques that leverage unlabeled data for improving downstream task performance, on three remote sensing tasks of riverbed segmentation, land cover mapping and flood mapping. These methods are especially valuable for remote sensing tasks since there is easy access to unlabeled imagery and getting ground truth labels can often be expensive. We quantify performance improvements one can expect on these remote sensing segmentation tasks when unlabeled imagery (outside of the labeled dataset) is made available for training. We also design experiments to test the effectiveness of these techniques when the test set has a domain shift relative to the training and validation sets.
No Modes left behind: Capturing the data distribution effectively using GANs
Feb 02, 2018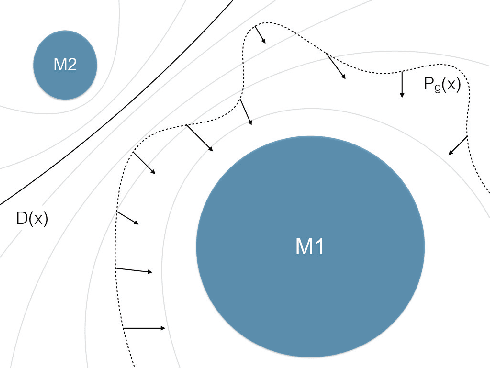
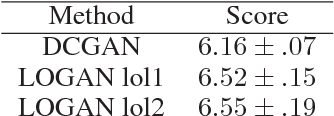
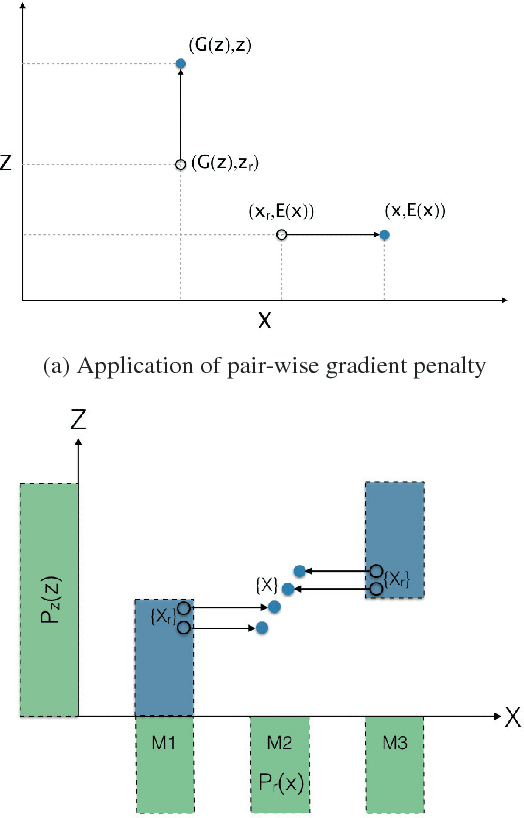
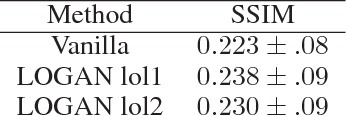
Generative adversarial networks (GANs) while being very versatile in realistic image synthesis, still are sensitive to the input distribution. Given a set of data that has an imbalance in the distribution, the networks are susceptible to missing modes and not capturing the data distribution. While various methods have been tried to improve training of GANs, these have not addressed the challenges of covering the full data distribution. Specifically, a generator is not penalized for missing a mode. We show that these are therefore still susceptible to not capturing the full data distribution. In this paper, we propose a simple approach that combines an encoder based objective with novel loss functions for generator and discriminator that improves the solution in terms of capturing missing modes. We validate that the proposed method results in substantial improvements through its detailed analysis on toy and real datasets. The quantitative and qualitative results demonstrate that the proposed method improves the solution for the problem of missing modes and improves training of GANs.