 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Action World Models for Control with Unlabeled Trajectories
Dec 10, 2025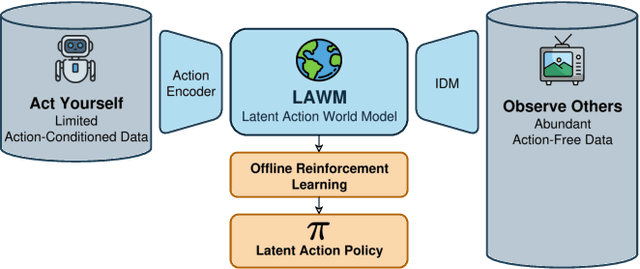
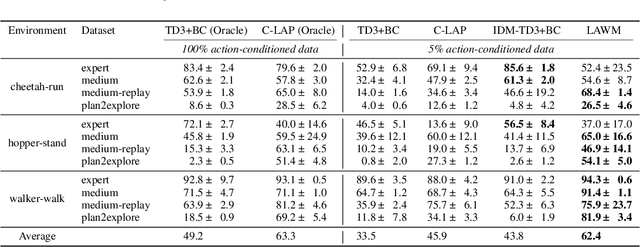
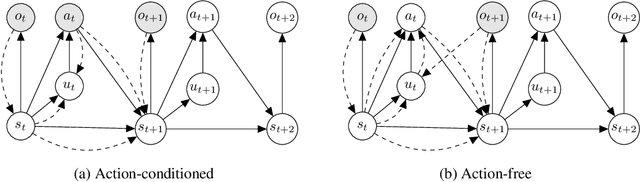

Inspired by how humans combine direct interaction with action-free experience (e.g., videos), we study world models that learn from heterogeneous data. Standard world models typically rely on action-conditioned trajectories, which limits effectiveness when action labels are scarce. We introduce a family of latent-action world models that jointly use action-conditioned and action-free data by learning a shared latent action representation. This latent space aligns observed control signals with actions inferred from passive observations, enabling a single dynamics model to train on large-scale unlabeled trajectories while requiring only a small set of action-labeled ones. We use the latent-action world model to learn a latent-action policy through offline reinforcement learning (RL), thereby bridging two traditionally separate domains: offline RL, which typically relies on action-conditioned data, and action-free training, which is rarely used with subsequent RL. On the DeepMind Control Suite, our approach achieves strong performance while using about an order of magnitude fewer action-labeled samples than purely action-conditioned baselines. These results show that latent actions enable training on both passive and interactive data, which makes world models learn more efficiently.
FlowQ: Energy-Guided Flow Policies for Offline Reinforcement Learning
May 20, 2025The use of guidance to steer sampling toward desired outcomes has been widely explored within diffusion models, especially in applications such as image and trajectory generation. However, incorporating guidance during training remains relatively underexplored. In this work, we introduce energy-guided flow matching, a novel approach that enhances the training of flow models and eliminates the need for guidance at inference time. We learn a conditional velocity field corresponding to the flow policy by approximating an energy-guided probability path as a Gaussian path. Learning guided trajectories is appealing for tasks where the target distribution is defined by a combination of data and an energy function, as in reinforcement learning. Diffusion-based policies have recently attracted attention for their expressive power and ability to capture multi-modal action distributions. Typically, these policies are optimized using weighted objectives or by back-propagating gradients through actions sampled by the policy. As an alternative, we propose FlowQ, an offline reinforcement learning algorithm based on energy-guided flow matching. Our method achieves competitive performance while the policy training time is constant in the number of flow sampling steps.
Constrained Latent Action Policies for Model-Based Offline Reinforcement Learning
Nov 07, 2024



In offline reinforcement learning, a policy is learned using a static dataset in the absence of costly feedback from the environment. In contrast to the online setting, only using static datasets poses additional challenges, such as policies generating out-of-distribution samples. Model-based offline reinforcement learning methods try to overcome these by learning a model of the underlying dynamics of the environment and using it to guide policy search. It is beneficial but, with limited datasets, errors in the model and the issue of value overestimation among out-of-distribution states can worsen performance. Current model-based methods apply some notion of conservatism to the Bellman update, often implemented using uncertainty estimation derived from model ensembles. In this paper, we propose Constrained Latent Action Policies (C-LAP) which learns a generative model of the joint distribution of observations and actions. We cast policy learning as a constrained objective to always stay within the support of the latent action distribution, and use the generative capabilities of the model to impose an implicit constraint on the generated actions. Thereby eliminating the need to use additional uncertainty penalties on the Bellman update and significantly decreasing the number of gradient steps required to learn a policy. We empirically evaluate C-LAP on the D4RL and V-D4RL benchmark, and show that C-LAP is competitive to state-of-the-art methods, especially outperforming on datasets with visual observations.
Learning to Centralize Dual-Arm Assembly
Oct 08, 2021



Even though industrial manipulators are widely used in modern manufacturing processes, deployment in unstructured environments remains an open problem. To deal with variety, complexity and uncertainty of real world manipulation tasks a general framework is essential. In this work we want to focus on assembly with humanoid robots by providing a framework for dual-arm peg-in-hole manipulation. As we aim to contribute towards an approach which is not limited to dual-arm peg-in-hole, but dual-arm manipulation in general, we keep modeling effort at a minimum. While reinforcement learning has shown great results for single-arm robotic manipulation in recent years, research focusing on dual-arm manipulation is still rare. Solving such tasks often involves complex modeling of interaction between two manipulators and their coupling at a control level. In this paper, we explore the applicability of model-free reinforcement learning to dual-arm manipulation based on a modular approach with two decentralized single-arm controllers and a single centralized policy. We reduce modeling effort to a minimum by using sparse rewards only. We demonstrate the effectiveness of the framework on dual-arm peg-in-hole and analyze sample efficiency and success rates for different action spaces. Moreover, we compare results on different clearances and showcase disturbance recovery and robustness, when dealing with position uncertainties. Finally we zero-shot transfer policies trained in simulation to the real-world and evaluate their performance.