 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Modal Visuo-Tactile Object Perception
Apr 02, 2026Estimating physical properties is critical for safe and efficient autonomous robotic manipulation, particularly during contact-rich interactions. In such settings, vision and tactile sensing provide complementary information about object geometry, pose, inertia, stiffness, and contact dynamics, such as stick-slip behavior. However, these properties are only indirectly observable and cannot always be modeled precisely (e.g., deformation in non-rigid objects coupled with nonlinear contact friction), making the estimation problem inherently complex and requiring sustained exploitation of visuo-tactile sensory information during action. Existing visuo-tactile perception frameworks have primarily emphasized forceful sensor fusion or static cross-modal alignment, with limited consideration of how uncertainty and beliefs about object properties evolve over time. Inspired by human multi-sensory perception and active inference, we propose the Cross-Modal Latent Filter (CMLF) to learn a structured, causal latent state-space of physical object properties. CMLF supports bidirectional transfer of cross-modal priors between vision and touch and integrates sensory evidence through a Bayesian inference process that evolves over time. Real-world robotic experiments demonstrate that CMLF improves the efficiency and robustness of latent physical properties estimation under uncertainty compared to baseline approaches. Beyond performance gains, the model exhibits perceptual coupling phenomena analogous to those observed in humans, including susceptibility to cross-modal illusions and similar trajectories in learning cross-sensory associations. Together, these results constitutes a significant step toward generalizable, robust and physically consistent cross-modal integration for robotic multi-sensory perception.
Latent Matters: Learning Deep State-Space Models
Feb 26, 2026Deep state-space models (DSSMs) enable temporal predictions by learning the underlying dynamics of observed sequence data. They are often trained by maximising the evidence lower bound. However, as we show, this does not ensure the model actually learns the underlying dynamics. We therefore propose a constrained optimisation framework as a general approach for training DSSMs. Building upon this, we introduce the extended Kalman VAE (EKVAE), which combines amortised variational inference with classic Bayesian filtering/smoothing to model dynamics more accurately than RNN-based DSSMs. Our results show that the constrained optimisation framework significantly improves system identification and prediction accuracy on the example of established state-of-the-art DSSMs. The EKVAE outperforms previous models w.r.t. prediction accuracy, achieves remarkable results in identifying dynamical systems, and can furthermore successfully learn state-space representations where static and dynamic features are disentangled.
Latent Action World Models for Control with Unlabeled Trajectories
Dec 10, 2025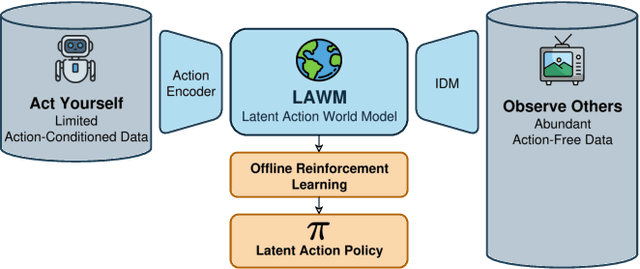
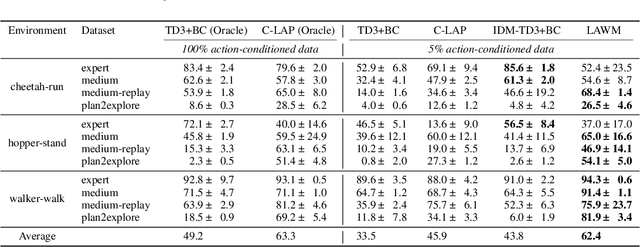
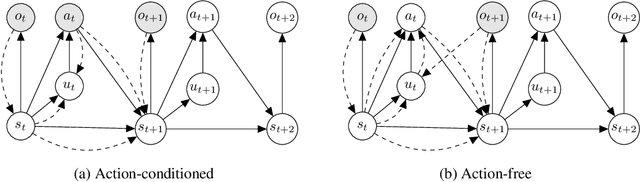

Inspired by how humans combine direct interaction with action-free experience (e.g., videos), we study world models that learn from heterogeneous data. Standard world models typically rely on action-conditioned trajectories, which limits effectiveness when action labels are scarce. We introduce a family of latent-action world models that jointly use action-conditioned and action-free data by learning a shared latent action representation. This latent space aligns observed control signals with actions inferred from passive observations, enabling a single dynamics model to train on large-scale unlabeled trajectories while requiring only a small set of action-labeled ones. We use the latent-action world model to learn a latent-action policy through offline reinforcement learning (RL), thereby bridging two traditionally separate domains: offline RL, which typically relies on action-conditioned data, and action-free training, which is rarely used with subsequent RL. On the DeepMind Control Suite, our approach achieves strong performance while using about an order of magnitude fewer action-labeled samples than purely action-conditioned baselines. These results show that latent actions enable training on both passive and interactive data, which makes world models learn more efficiently.
TechOps: Technical Documentation Templates for the AI Act
Aug 12, 2025Operationalizing the EU AI Act requires clear technical documentation to ensure AI systems are transparent, traceable, and accountable. Existing documentation templates for AI systems do not fully cover the entire AI lifecycle while meeting the technical documentation requirements of the AI Act. This paper addresses those shortcomings by introducing open-source templates and examples for documenting data, models, and applications to provide sufficient documentation for certifying compliance with the AI Act. These templates track the system status over the entire AI lifecycle, ensuring traceability, reproducibility, and compliance with the AI Act. They also promote discoverability and collaboration, reduce risks, and align with best practices in AI documentation and governance. The templates are evaluated and refined based on user feedback to enable insights into their usability and implementability. We then validate the approach on real-world scenarios, providing examples that further guide their implementation: the data template is followed to document a skin tones dataset created to support fairness evaluations of downstream computer vision models and human-centric applications; the model template is followed to document a neural network for segmenting human silhouettes in photos. The application template is tested on a system deployed for construction site safety using real-time video analytics and sensor data. Our results show that TechOps can serve as a practical tool to enable oversight for regulatory compliance and responsible AI development.
FlowQ: Energy-Guided Flow Policies for Offline Reinforcement Learning
May 20, 2025The use of guidance to steer sampling toward desired outcomes has been widely explored within diffusion models, especially in applications such as image and trajectory generation. However, incorporating guidance during training remains relatively underexplored. In this work, we introduce energy-guided flow matching, a novel approach that enhances the training of flow models and eliminates the need for guidance at inference time. We learn a conditional velocity field corresponding to the flow policy by approximating an energy-guided probability path as a Gaussian path. Learning guided trajectories is appealing for tasks where the target distribution is defined by a combination of data and an energy function, as in reinforcement learning. Diffusion-based policies have recently attracted attention for their expressive power and ability to capture multi-modal action distributions. Typically, these policies are optimized using weighted objectives or by back-propagating gradients through actions sampled by the policy. As an alternative, we propose FlowQ, an offline reinforcement learning algorithm based on energy-guided flow matching. Our method achieves competitive performance while the policy training time is constant in the number of flow sampling steps.
Constrained Latent Action Policies for Model-Based Offline Reinforcement Learning
Nov 07, 2024



In offline reinforcement learning, a policy is learned using a static dataset in the absence of costly feedback from the environment. In contrast to the online setting, only using static datasets poses additional challenges, such as policies generating out-of-distribution samples. Model-based offline reinforcement learning methods try to overcome these by learning a model of the underlying dynamics of the environment and using it to guide policy search. It is beneficial but, with limited datasets, errors in the model and the issue of value overestimation among out-of-distribution states can worsen performance. Current model-based methods apply some notion of conservatism to the Bellman update, often implemented using uncertainty estimation derived from model ensembles. In this paper, we propose Constrained Latent Action Policies (C-LAP) which learns a generative model of the joint distribution of observations and actions. We cast policy learning as a constrained objective to always stay within the support of the latent action distribution, and use the generative capabilities of the model to impose an implicit constraint on the generated actions. Thereby eliminating the need to use additional uncertainty penalties on the Bellman update and significantly decreasing the number of gradient steps required to learn a policy. We empirically evaluate C-LAP on the D4RL and V-D4RL benchmark, and show that C-LAP is competitive to state-of-the-art methods, especially outperforming on datasets with visual observations.
Assistive AI for Augmenting Human Decision-making
Oct 18, 2024Regulatory frameworks for the use of AI are emerging. However, they trail behind the fast-evolving malicious AI technologies that can quickly cause lasting societal damage. In response, we introduce a pioneering Assistive AI framework designed to enhance human decision-making capabilities. This framework aims to establish a trust network across various fields, especially within legal contexts, serving as a proactive complement to ongoing regulatory efforts. Central to our framework are the principles of privacy, accountability, and credibility. In our methodology, the foundation of reliability of information and information sources is built upon the ability to uphold accountability, enhance security, and protect privacy. This approach supports, filters, and potentially guides communication, thereby empowering individuals and communities to make well-informed decisions based on cutting-edge advancements in AI. Our framework uses the concept of Boards as proxies to collectively ensure that AI-assisted decisions are reliable, accountable, and in alignment with societal values and legal standards. Through a detailed exploration of our framework, including its main components, operations, and sample use cases, the paper shows how AI can assist in the complex process of decision-making while maintaining human oversight. The proposed framework not only extends regulatory landscapes but also highlights the synergy between AI technology and human judgement, underscoring the potential of AI to serve as a vital instrument in discerning reality from fiction and thus enhancing the decision-making process. Furthermore, we provide domain-specific use cases to highlight the applicability of our framework.
LIMT: Language-Informed Multi-Task Visual World Models
Jul 18, 2024



Most recent successes in robot reinforcement learning involve learning a specialized single-task agent. However, robots capable of performing multiple tasks can be much more valuable in real-world applications. Multi-task reinforcement learning can be very challenging due to the increased sample complexity and the potentially conflicting task objectives. Previous work on this topic is dominated by model-free approaches. The latter can be very sample inefficient even when learning specialized single-task agents. In this work, we focus on model-based multi-task reinforcement learning. We propose a method for learning multi-task visual world models, leveraging pre-trained language models to extract semantically meaningful task representations. These representations are used by the world model and policy to reason about task similarity in dynamics and behavior. Our results highlight the benefits of using language-driven task representations for world models and a clear advantage of model-based multi-task learning over the more common model-free paradigm.
The Shortcomings of Force-from-Motion in Robot Learning
Jul 03, 2024
Robotic manipulation requires accurate motion and physical interaction control. However, current robot learning approaches focus on motion-centric action spaces that do not explicitly give the policy control over the interaction. In this paper, we discuss the repercussions of this choice and argue for more interaction-explicit action spaces in robot learning.
Pragmatic auditing: a pilot-driven approach for auditing Machine Learning systems
May 21, 2024



The growing adoption and deployment of Machine Learning (ML) systems came with its share of ethical incidents and societal concerns. It also unveiled the necessity to properly audit these systems in light of ethical principles. For such a novel type of algorithmic auditing to become standard practice, two main prerequisites need to be available: A lifecycle model that is tailored towards transparency and accountability, and a principled risk assessment procedure that allows the proper scoping of the audit. Aiming to make a pragmatic step towards a wider adoption of ML auditing, we present a respective procedure that extends the AI-HLEG guidelines published by the European Commission. Our audit procedure is based on an ML lifecycle model that explicitly focuses on documentation, accountability, and quality assurance; and serves as a common ground for alignment between the auditors and the audited organisation. We describe two pilots conducted on real-world use cases from two different organisations and discuss the shortcomings of ML algorithmic auditing as well as future directions thereof.