 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnxiety Detection
Papers and Code
Multi-stage Bridge Inspection System: Integrating Foundation Models with Location Anonymization
Jan 24, 2026In Japan, civil infrastructure condition monitoring is mandated through visual inspection every five years. Field-captured damage images frequently contain concrete cracks and rebar exposure, often accompanied by construction signs revealing regional information. To enable safe infrastructure use without causing public anxiety, it is essential to protect regional information while accurately extracting damage features and visualizing key indicators for repair decision-making. This paper presents an open-source bridge damage detection system with regional privacy protection capabilities. We employ Segment Anything Model (SAM) 3 for rebar corrosion detection and utilize DBSCAN for automatic completion of missed regions. Construction sign regions are detected and protected through Gaussian blur. Four preprocessing methods improve OCR accuracy, and GPU optimization enables 1.7-second processing per image. The technology stack includes SAM3, PyTorch, OpenCV, pytesseract, and scikit-learn, achieving efficient bridge inspection with regional information protection.
Student Mental Health Screening via Fitbit Data Collected During the COVID-19 Pandemic
Jan 22, 2026College students experience many stressors, resulting in high levels of anxiety and depression. Wearable technology provides unobtrusive sensor data that can be used for the early detection of mental illness. However, current research is limited concerning the variety of psychological instruments administered, physiological modalities, and time series parameters. In this research, we collect the Student Mental and Environmental Health (StudentMEH) Fitbit dataset from students at our institution during the pandemic. We provide a comprehensive assessment of the ability of predictive machine learning models to screen for depression, anxiety, and stress using different Fitbit modalities. Our findings indicate potential in physiological modalities such as heart rate and sleep to screen for mental illness with the F1 scores as high as 0.79 for anxiety, the former modality reaching 0.77 for stress screening, and the latter modality achieving 0.78 for depression. This research highlights the potential of wearable devices to support continuous mental health monitoring, the importance of identifying best data aggregation levels and appropriate modalities for screening for different mental ailments.
Early Linguistic Pattern of Anxiety from Social Media Using Interpretable Linguistic Features: A Multi-Faceted Validation Study with Author-Disjoint Evaluation
Jan 16, 2026Anxiety affects hundreds of millions of individuals globally, yet large-scale screening remains limited. Social media language provides an opportunity for scalable detection, but current models often lack interpretability, keyword-robustness validation, and rigorous user-level data integrity. This work presents a transparent approach to social media-based anxiety detection through linguistically interpretable feature-grounded modeling and cross-domain validation. Using a substantial dataset of Reddit posts, we trained a logistic regression classifier on carefully curated subreddits for training, validation, and test splits. Comprehensive evaluation included feature ablation, keyword masking experiments, and varying-density difference analyses comparing anxious and control groups, along with external validation using clinically interviewed participants with diagnosed anxiety disorders. The model achieved strong performance while maintaining high accuracy even after sentiment removal or keyword masking. Early detection using minimal post history significantly outperformed random classification, and cross-domain analysis demonstrated strong consistency with clinical interview data. Results indicate that transparent linguistic features can support reliable, generalizable, and keyword-robust anxiety detection. The proposed framework provides a reproducible baseline for interpretable mental health screening across diverse online contexts.
Designing KRIYA: An AI Companion for Wellbeing Self-Reflection
Jan 21, 2026Most personal wellbeing apps present summative dashboards of health and physical activity metrics, yet many users struggle to translate this information into meaningful understanding. These apps commonly support engagement through goals, reminders, and structured targets, which can reinforce comparison, judgment, and performance anxiety. To explore a complementary approach that prioritizes self-reflection, we design KRIYA, an AI wellbeing companion that supports co-interpretive engagement with personal wellbeing data. KRIYA aims to collaborate with users to explore questions, explanations, and future scenarios through features such as Comfort Zone, Detective Mode, and What-If Planning. We conducted semi-structured interviews with 18 college students interacting with a KRIYA prototype using hypothetical data. Our findings show that through KRIYA interaction, users framed engaging with wellbeing data as interpretation rather than performance, experienced reflection as supportive or pressuring depending on emotional framing, and developed trust through transparency. We discuss design implications for AI companions that support curiosity, self-compassion, and reflective sensemaking of personal health data.
A Comparative Study of Traditional Machine Learning, Deep Learning, and Large Language Models for Mental Health Forecasting using Smartphone Sensing Data
Jan 07, 2026Smartphone sensing offers an unobtrusive and scalable way to track daily behaviors linked to mental health, capturing changes in sleep, mobility, and phone use that often precede symptoms of stress, anxiety, or depression. While most prior studies focus on detection that responds to existing conditions, forecasting mental health enables proactive support through Just-in-Time Adaptive Interventions. In this paper, we present the first comprehensive benchmarking study comparing traditional machine learning (ML), deep learning (DL), and large language model (LLM) approaches for mental health forecasting using the College Experience Sensing (CES) dataset, the most extensive longitudinal dataset of college student mental health to date. We systematically evaluate models across temporal windows, feature granularities, personalization strategies, and class imbalance handling. Our results show that DL models, particularly Transformer (Macro-F1 = 0.58), achieve the best overall performance, while LLMs show strength in contextual reasoning but weaker temporal modeling. Personalization substantially improves forecasts of severe mental health states. By revealing how different modeling approaches interpret phone sensing behavioral data over time, this work lays the groundwork for next-generation, adaptive, and human-centered mental health technologies that can advance both research and real-world well-being.
StressRoBERTa: Cross-Condition Transfer Learning from Depression, Anxiety, and PTSD to Stress Detection
Dec 29, 2025The prevalence of chronic stress represents a significant public health concern, with social media platforms like Twitter serving as important venues for individuals to share their experiences. This paper introduces StressRoBERTa, a cross-condition transfer learning approach for automatic detection of self-reported chronic stress in English tweets. The investigation examines whether continual training on clinically related conditions (depression, anxiety, PTSD), disorders with high comorbidity with chronic stress, improves stress detection compared to general language models and broad mental health models. RoBERTa is continually trained on the Stress-SMHD corpus (108M words from users with self-reported diagnoses of depression, anxiety, and PTSD) and fine-tuned on the SMM4H 2022 Task 8 dataset. StressRoBERTa achieves 82% F1-score, outperforming the best shared task system (79% F1) by 3 percentage points. The results demonstrate that focused cross-condition transfer from stress-related disorders (+1% F1 over vanilla RoBERTa) provides stronger representations than general mental health training. Evaluation on Dreaddit (81% F1) further demonstrates transfer from clinical mental health contexts to situational stress discussions.
FBA$^2$D: Frequency-based Black-box Attack for AI-generated Image Detection
Dec 10, 2025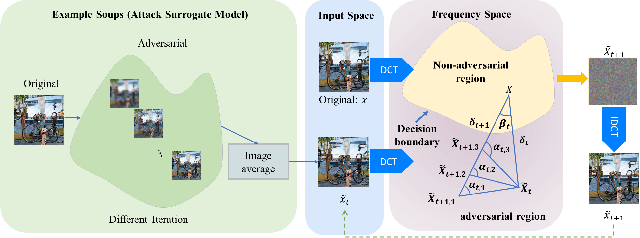
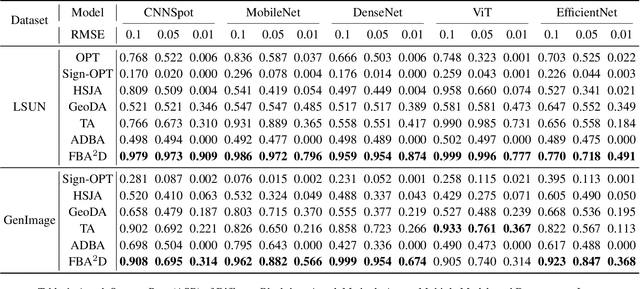
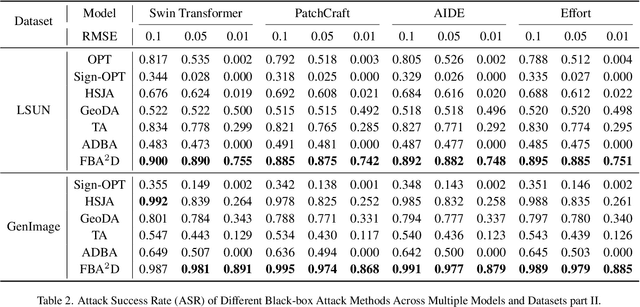

The prosperous development of Artificial Intelligence-Generated Content (AIGC) has brought people's anxiety about the spread of false information on social media. Designing detectors for filtering is an effective defense method, but most detectors will be compromised by adversarial samples. Currently, most studies exposing AIGC security issues assume information on model structure and data distribution. In real applications, attackers query and interfere with models that provide services in the form of application programming interfaces (APIs), which constitutes the black-box decision-based attack paradigm. However, to the best of our knowledge, decision-based attacks on AIGC detectors remain unexplored. In this study, we propose \textbf{FBA$^2$D}: a frequency-based black-box attack method for AIGC detection to fill the research gap. Motivated by frequency-domain discrepancies between generated and real images, we develop a decision-based attack that leverages the Discrete Cosine Transform (DCT) for fine-grained spectral partitioning and selects frequency bands as query subspaces, improving both query efficiency and image quality. Moreover, attacks on AIGC detectors should mitigate initialization failures, preserve image quality, and operate under strict query budgets. To address these issues, we adopt an ``adversarial example soup'' method, averaging candidates from successive surrogate iterations and using the result as the initialization to accelerate the query-based attack. The empirical study on the Synthetic LSUN dataset and GenImage dataset demonstrate the effectiveness of our prosed method. This study shows the urgency of addressing practical AIGC security problems.
HCFSLN: Adaptive Hyperbolic Few-Shot Learning for Multimodal Anxiety Detection
Nov 10, 2025Anxiety disorders impact millions globally, yet traditional diagnosis relies on clinical interviews, while machine learning models struggle with overfitting due to limited data. Large-scale data collection remains costly and time-consuming, restricting accessibility. To address this, we introduce the Hyperbolic Curvature Few-Shot Learning Network (HCFSLN), a novel Few-Shot Learning (FSL) framework for multimodal anxiety detection, integrating speech, physiological signals, and video data. HCFSLN enhances feature separability through hyperbolic embeddings, cross-modal attention, and an adaptive gating network, enabling robust classification with minimal data. We collected a multimodal anxiety dataset from 108 participants and benchmarked HCFSLN against six FSL baselines, achieving 88% accuracy, outperforming the best baseline by 14%. These results highlight the effectiveness of hyperbolic space for modeling anxiety-related speech patterns and demonstrate FSL's potential for anxiety classification.
Towards Affect-Adaptive Human-Robot Interaction: A Protocol for Multimodal Dataset Collection on Social Anxiety
Nov 17, 2025


Social anxiety is a prevalent condition that affects interpersonal interactions and social functioning. Recent advances in artificial intelligence and social robotics offer new opportunities to examine social anxiety in the human-robot interaction context. Accurate detection of affective states and behaviours associated with social anxiety requires multimodal datasets, where each signal modality provides complementary insights into its manifestations. However, such datasets remain scarce, limiting progress in both research and applications. To address this, this paper presents a protocol for multimodal dataset collection designed to reflect social anxiety in a human-robot interaction context. The dataset will consist of synchronised audio, video, and physiological recordings acquired from at least 70 participants, grouped according to their level of social anxiety, as they engage in approximately 10-minute interactive Wizard-of-Oz role-play scenarios with the Furhat social robot under controlled experimental conditions. In addition to multimodal data, the dataset will be enriched with contextual data providing deeper insight into individual variability in social anxiety responses. This work can contribute to research on affect-adaptive human-robot interaction by providing support for robust multimodal detection of social anxiety.
Evaluating LLMs for Anxiety, Depression, and Stress Detection Evaluating Large Language Models for Anxiety, Depression, and Stress Detection: Insights into Prompting Strategies and Synthetic Data
Nov 10, 2025Mental health disorders affect over one-fifth of adults globally, yet detecting such conditions from text remains challenging due to the subtle and varied nature of symptom expression. This study evaluates multiple approaches for mental health detection, comparing Large Language Models (LLMs) such as Llama and GPT with classical machine learning and transformer-based architectures including BERT, XLNet, and Distil-RoBERTa. Using the DAIC-WOZ dataset of clinical interviews, we fine-tuned models for anxiety, depression, and stress classification and applied synthetic data generation to mitigate class imbalance. Results show that Distil-RoBERTa achieved the highest F1 score (0.883) for GAD-2, while XLNet outperformed others on PHQ tasks (F1 up to 0.891). For stress detection, a zero-shot synthetic approach (SD+Zero-Shot-Basic) reached an F1 of 0.884 and ROC AUC of 0.886. Findings demonstrate the effectiveness of transformer-based models and highlight the value of synthetic data in improving recall and generalization. However, careful calibration is required to prevent precision loss. Overall, this work emphasizes the potential of combining advanced language models and data augmentation to enhance automated mental health assessment from text.