 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFBA$^2$D: Frequency-based Black-box Attack for AI-generated Image Detection
Dec 10, 2025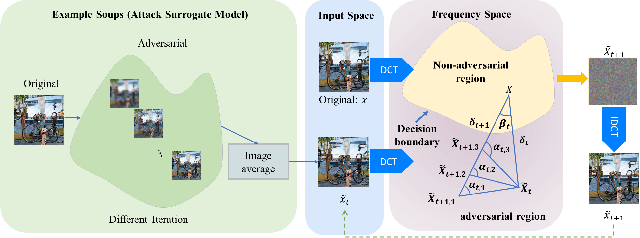
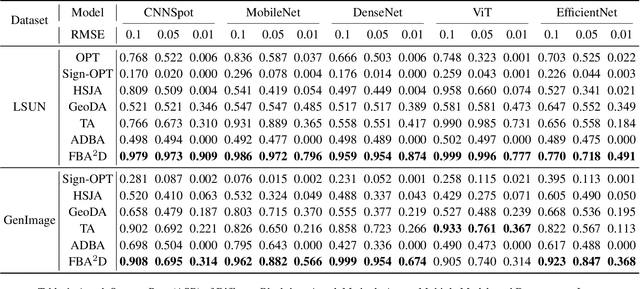
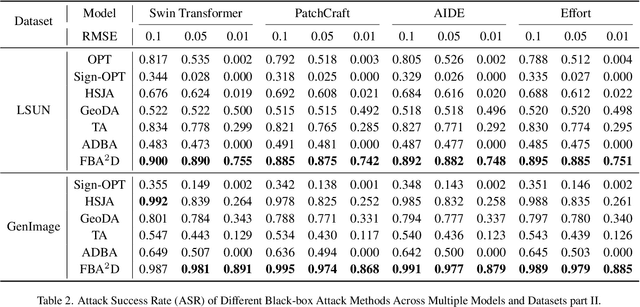

The prosperous development of Artificial Intelligence-Generated Content (AIGC) has brought people's anxiety about the spread of false information on social media. Designing detectors for filtering is an effective defense method, but most detectors will be compromised by adversarial samples. Currently, most studies exposing AIGC security issues assume information on model structure and data distribution. In real applications, attackers query and interfere with models that provide services in the form of application programming interfaces (APIs), which constitutes the black-box decision-based attack paradigm. However, to the best of our knowledge, decision-based attacks on AIGC detectors remain unexplored. In this study, we propose \textbf{FBA$^2$D}: a frequency-based black-box attack method for AIGC detection to fill the research gap. Motivated by frequency-domain discrepancies between generated and real images, we develop a decision-based attack that leverages the Discrete Cosine Transform (DCT) for fine-grained spectral partitioning and selects frequency bands as query subspaces, improving both query efficiency and image quality. Moreover, attacks on AIGC detectors should mitigate initialization failures, preserve image quality, and operate under strict query budgets. To address these issues, we adopt an ``adversarial example soup'' method, averaging candidates from successive surrogate iterations and using the result as the initialization to accelerate the query-based attack. The empirical study on the Synthetic LSUN dataset and GenImage dataset demonstrate the effectiveness of our prosed method. This study shows the urgency of addressing practical AIGC security problems.
Practice with Graph-based ANN Algorithms on Sparse Data: Chi-square Two-tower model, HNSW, Sign Cauchy Projections
Jun 13, 2023



Sparse data are common. The traditional ``handcrafted'' features are often sparse. Embedding vectors from trained models can also be very sparse, for example, embeddings trained via the ``ReLu'' activation function. In this paper, we report our exploration of efficient search in sparse data with graph-based ANN algorithms (e.g., HNSW, or SONG which is the GPU version of HNSW), which are popular in industrial practice, e.g., search and ads (advertising). We experiment with the proprietary ads targeting application, as well as benchmark public datasets. For ads targeting, we train embeddings with the standard ``cosine two-tower'' model and we also develop the ``chi-square two-tower'' model. Both models produce (highly) sparse embeddings when they are integrated with the ``ReLu'' activation function. In EBR (embedding-based retrieval) applications, after we the embeddings are trained, the next crucial task is the approximate near neighbor (ANN) search for serving. While there are many ANN algorithms we can choose from, in this study, we focus on the graph-based ANN algorithm (e.g., HNSW-type). Sparse embeddings should help improve the efficiency of EBR. One benefit is the reduced memory cost for the embeddings. The other obvious benefit is the reduced computational time for evaluating similarities, because, for graph-based ANN algorithms such as HNSW, computing similarities is often the dominating cost. In addition to the effort on leveraging data sparsity for storage and computation, we also integrate ``sign cauchy random projections'' (SignCRP) to hash vectors to bits, to further reduce the memory cost and speed up the ANN search. In NIPS'13, SignCRP was proposed to hash the chi-square similarity, which is a well-adopted nonlinear kernel in NLP and computer vision. Therefore, the chi-square two-tower model, SignCRP, and HNSW are now tightly integrated.