 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Sampling via De-randomization for Discrete Diffusion Models
Dec 14, 2023



Diffusion models have emerged as powerful tools for high-quality data generation, such as image generation. Despite its success in continuous spaces, discrete diffusion models, which apply to domains such as texts and natural languages, remain under-studied and often suffer from slow generation speed. In this paper, we propose a novel de-randomized diffusion process, which leads to an accelerated algorithm for discrete diffusion models. Our technique significantly reduces the number of function evaluations (i.e., calls to the neural network), making the sampling process much faster. Furthermore, we introduce a continuous-time (i.e., infinite-step) sampling algorithm that can provide even better sample qualities than its discrete-time (finite-step) counterpart. Extensive experiments on natural language generation and machine translation tasks demonstrate the superior performance of our method in terms of both generation speed and sample quality over existing methods for discrete diffusion models.
Rephrase and Respond: Let Large Language Models Ask Better Questions for Themselves
Nov 07, 2023



Misunderstandings arise not only in interpersonal communication but also between humans and Large Language Models (LLMs). Such discrepancies can make LLMs interpret seemingly unambiguous questions in unexpected ways, yielding incorrect responses. While it is widely acknowledged that the quality of a prompt, such as a question, significantly impacts the quality of the response provided by LLMs, a systematic method for crafting questions that LLMs can better comprehend is still underdeveloped. In this paper, we present a method named `Rephrase and Respond' (RaR), which allows LLMs to rephrase and expand questions posed by humans and provide responses in a single prompt. This approach serves as a simple yet effective prompting method for improving performance. We also introduce a two-step variant of RaR, where a rephrasing LLM first rephrases the question and then passes the original and rephrased questions together to a different responding LLM. This facilitates the effective utilization of rephrased questions generated by one LLM with another. Our experiments demonstrate that our methods significantly improve the performance of different models across a wide range to tasks. We further provide a comprehensive comparison between RaR and the popular Chain-of-Thought (CoT) methods, both theoretically and empirically. We show that RaR is complementary to CoT and can be combined with CoT to achieve even better performance. Our work not only contributes to enhancing LLM performance efficiently and effectively but also sheds light on a fair evaluation of LLM capabilities. Data and codes are available at https://github.com/uclaml/Rephrase-and-Respond.
Implicit Bias of Gradient Descent for Two-layer ReLU and Leaky ReLU Networks on Nearly-orthogonal Data
Oct 29, 2023



The implicit bias towards solutions with favorable properties is believed to be a key reason why neural networks trained by gradient-based optimization can generalize well. While the implicit bias of gradient flow has been widely studied for homogeneous neural networks (including ReLU and leaky ReLU networks), the implicit bias of gradient descent is currently only understood for smooth neural networks. Therefore, implicit bias in non-smooth neural networks trained by gradient descent remains an open question. In this paper, we aim to answer this question by studying the implicit bias of gradient descent for training two-layer fully connected (leaky) ReLU neural networks. We showed that when the training data are nearly-orthogonal, for leaky ReLU activation function, gradient descent will find a network with a stable rank that converges to $1$, whereas for ReLU activation function, gradient descent will find a neural network with a stable rank that is upper bounded by a constant. Additionally, we show that gradient descent will find a neural network such that all the training data points have the same normalized margin asymptotically. Experiments on both synthetic and real data backup our theoretical findings.
How Many Pretraining Tasks Are Needed for In-Context Learning of Linear Regression?
Oct 12, 2023Transformers pretrained on diverse tasks exhibit remarkable in-context learning (ICL) capabilities, enabling them to solve unseen tasks solely based on input contexts without adjusting model parameters. In this paper, we study ICL in one of its simplest setups: pretraining a linearly parameterized single-layer linear attention model for linear regression with a Gaussian prior. We establish a statistical task complexity bound for the attention model pretraining, showing that effective pretraining only requires a small number of independent tasks. Furthermore, we prove that the pretrained model closely matches the Bayes optimal algorithm, i.e., optimally tuned ridge regression, by achieving nearly Bayes optimal risk on unseen tasks under a fixed context length. These theoretical findings complement prior experimental research and shed light on the statistical foundations of ICL.
Why Does Sharpness-Aware Minimization Generalize Better Than SGD?
Oct 11, 2023



The challenge of overfitting, in which the model memorizes the training data and fails to generalize to test data, has become increasingly significant in the training of large neural networks. To tackle this challenge, Sharpness-Aware Minimization (SAM) has emerged as a promising training method, which can improve the generalization of neural networks even in the presence of label noise. However, a deep understanding of how SAM works, especially in the setting of nonlinear neural networks and classification tasks, remains largely missing. This paper fills this gap by demonstrating why SAM generalizes better than Stochastic Gradient Descent (SGD) for a certain data model and two-layer convolutional ReLU networks. The loss landscape of our studied problem is nonsmooth, thus current explanations for the success of SAM based on the Hessian information are insufficient. Our result explains the benefits of SAM, particularly its ability to prevent noise learning in the early stages, thereby facilitating more effective learning of features. Experiments on both synthetic and real data corroborate our theory.
Understanding Transferable Representation Learning and Zero-shot Transfer in CLIP
Oct 02, 2023Multi-modal learning has become increasingly popular due to its ability to leverage information from different data sources (e.g., text and images) to improve the model performance. Recently, CLIP has emerged as an effective approach that employs vision-language contrastive pretraining to learn joint image and text representations and exhibits remarkable performance in zero-shot learning and text-guided natural image generation. Despite the huge practical success of CLIP, its theoretical understanding remains elusive. In this paper, we formally study transferrable representation learning underlying CLIP and demonstrate how features from different modalities get aligned. We also analyze its zero-shot transfer performance on the downstream tasks. Inspired by our analysis, we propose a new CLIP-type approach, which achieves better performance than CLIP and other state-of-the-art methods on benchmark datasets.
Benign Overfitting for Two-layer ReLU Networks
Mar 07, 2023Modern deep learning models with great expressive power can be trained to overfit the training data but still generalize well. This phenomenon is referred to as benign overfitting. Recently, a few studies have attempted to theoretically understand benign overfitting in neural networks. However, these works are either limited to neural networks with smooth activation functions or to the neural tangent kernel regime. How and when benign overfitting can occur in ReLU neural networks remains an open problem. In this work, we seek to answer this question by establishing algorithm-dependent risk bounds for learning two-layer ReLU convolutional neural networks with label-flipping noise. We show that, under mild conditions, the neural network trained by gradient descent can achieve near-zero training loss and Bayes optimal test risk. Our result also reveals a sharp transition between benign and harmful overfitting under different conditions on data distribution in terms of test risk. Experiments on synthetic data back up our theory.
Learning High-Dimensional Single-Neuron ReLU Networks with Finite Samples
Mar 03, 2023This paper considers the problem of learning a single ReLU neuron with squared loss (a.k.a., ReLU regression) in the overparameterized regime, where the input dimension can exceed the number of samples. We analyze a Perceptron-type algorithm called GLM-tron (Kakade et al., 2011), and provide its dimension-free risk upper bounds for high-dimensional ReLU regression in both well-specified and misspecified settings. Our risk bounds recover several existing results as special cases. Moreover, in the well-specified setting, we also provide an instance-wise matching risk lower bound for GLM-tron. Our upper and lower risk bounds provide a sharp characterization of the high-dimensional ReLU regression problems that can be learned via GLM-tron. On the other hand, we provide some negative results for stochastic gradient descent (SGD) for ReLU regression with symmetric Bernoulli data: if the model is well-specified, the excess risk of SGD is provably no better than that of GLM-tron ignoring constant factors, for each problem instance; and in the noiseless case, GLM-tron can achieve a small risk while SGD unavoidably suffers from a constant risk in expectation. These results together suggest that GLM-tron might be preferable than SGD for high-dimensional ReLU regression.
ISA-Net: Improved spatial attention network for PET-CT tumor segmentation
Nov 04, 2022



Achieving accurate and automated tumor segmentation plays an important role in both clinical practice and radiomics research. Segmentation in medicine is now often performed manually by experts, which is a laborious, expensive and error-prone task. Manual annotation relies heavily on the experience and knowledge of these experts. In addition, there is much intra- and interobserver variation. Therefore, it is of great significance to develop a method that can automatically segment tumor target regions. In this paper, we propose a deep learning segmentation method based on multimodal positron emission tomography-computed tomography (PET-CT), which combines the high sensitivity of PET and the precise anatomical information of CT. We design an improved spatial attention network(ISA-Net) to increase the accuracy of PET or CT in detecting tumors, which uses multi-scale convolution operation to extract feature information and can highlight the tumor region location information and suppress the non-tumor region location information. In addition, our network uses dual-channel inputs in the coding stage and fuses them in the decoding stage, which can take advantage of the differences and complementarities between PET and CT. We validated the proposed ISA-Net method on two clinical datasets, a soft tissue sarcoma(STS) and a head and neck tumor(HECKTOR) dataset, and compared with other attention methods for tumor segmentation. The DSC score of 0.8378 on STS dataset and 0.8076 on HECKTOR dataset show that ISA-Net method achieves better segmentation performance and has better generalization. Conclusions: The method proposed in this paper is based on multi-modal medical image tumor segmentation, which can effectively utilize the difference and complementarity of different modes. The method can also be applied to other multi-modal data or single-modal data by proper adjustment.
A General Framework for Sample-Efficient Function Approximation in Reinforcement Learning
Sep 30, 2022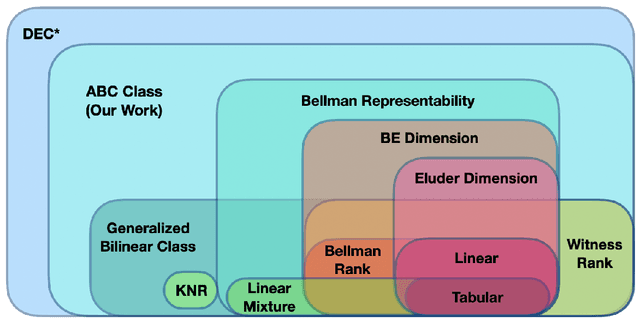
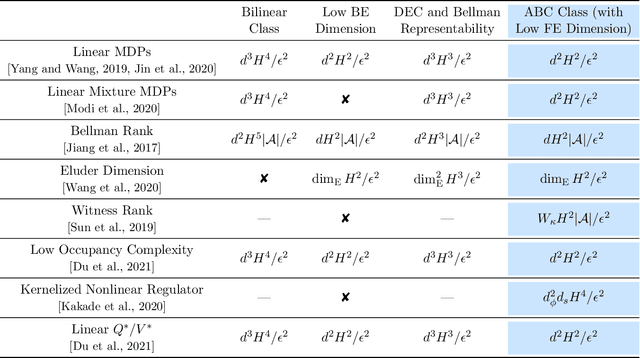
With the increasing need for handling large state and action spaces, general function approximation has become a key technique in reinforcement learning (RL). In this paper, we propose a general framework that unifies model-based and model-free RL, and an Admissible Bellman Characterization (ABC) class that subsumes nearly all Markov Decision Process (MDP) models in the literature for tractable RL. We propose a novel estimation function with decomposable structural properties for optimization-based exploration and the functional eluder dimension as a complexity measure of the ABC class. Under our framework, a new sample-efficient algorithm namely OPtimization-based ExploRation with Approximation (OPERA) is proposed, achieving regret bounds that match or improve over the best-known results for a variety of MDP models. In particular, for MDPs with low Witness rank, under a slightly stronger assumption, OPERA improves the state-of-the-art sample complexity results by a factor of $dH$. Our framework provides a generic interface to design and analyze new RL models and algorithms.