 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeakerCard-1M: An Evidence-Grounded Speaker Card Corpus for In-the-Wild Speaker Verification
Jun 03, 2026Modern speaker verification (SV) systems rely on speaker embeddings that are effective but difficult to interpret or query in natural language. Most existing speech-text corpora target controllable synthesis or utterance-level captioning, and provide limited speaker-level supervision for in-the-wild speaker recognition. This paper introduces SpeakerCard-1M, a bilingual speaker-centric resource for evidence-grounded SV, derived from VoxCeleb1/2 and CN-Celeb1/2, where the "-1M" suffix refers to the 1.78M utterance-level captions contained in the release. We adopt a tool-first, LLM-last approach: ten acoustic probes produce field-level evidence, the evidence is aggregated into speaker profiles under a schema that separates relatively stable traits from utterance-level states, and bilingual Speaker Cards are rendered by a constrained LLM that sees only the structured fields. The release includes 56.7K Speaker Card records over 10.2K speakers, 1.78M utterance-level captions, and speaker-ID-disjoint hard-negative triplets. We further define two SV-oriented cross-modal protocols, bidirectional Speaker-Text Retrieval (T2S-R / S2T-R) and Attribute-Conditioned Verification (AC-Verify), and compare a dual-encoder baseline against recent audio language models under a zero-shot forced-choice setting. Joint audio-text training increases VoxCeleb1-O EER by 0.31% absolute over the audio-only baseline. Under a style-symmetric LLM-generated counterfactual protocol, eight recent audio language models (7B-30B+ parameters, both open- and closed-source) score 49-77% on pitch-level AC-Verify under two-way forced choice, compared with 88.66% reached by our dual encoder.
Listening with Time: Precise Temporal Awareness for Long-Form Audio Understanding
Apr 24, 2026While Large Audio Language Models (LALMs) achieve strong performance on short audio, they degrade on long-form inputs. This degradation is more severe in temporal awareness tasks, where temporal alignment becomes increasingly inaccurate as audio duration grows. We attribute these limitations to the lack of data, benchmarks, and modeling approaches tailored for long-form temporal awareness. To bridge this gap, we first construct LAT-Chronicle, a 1.2k hour long-form audio dataset with temporal annotations across real-world scenarios. We further develop LAT-Bench, the first human-verified benchmark supporting audio up to 30 minutes while covering three core tasks: Dense Audio Caption, Temporal Audio Grounding, and Targeted Audio Caption. Leveraging these resources, we propose LAT-Audio, formulating temporal awareness as a progressive global-to-local reasoning paradigm. A global timeline is first constructed as an aligned temporal-semantic context,and the Think-With-Audio Chain-of-Thought (TWA-CoT) is then introduced to perform iterative reasoning by incorporating local audio information via tool use. Experiments show that LAT-Audio surpasses existing models on long-form audio temporal awareness tasks and improves robustness to input duration. We release the dataset, benchmark, and model to facilitate future research at https://github.com/alanshaoTT/LAT-Audio-Repo.
Borderless Long Speech Synthesis
Mar 20, 2026Most existing text-to-speech (TTS) systems either synthesize speech sentence by sentence and stitch the results together, or drive synthesis from plain-text dialogues alone. Both approaches leave models with little understanding of global context or paralinguistic cues, making it hard to capture real-world phenomena such as multi-speaker interactions (interruptions, overlapping speech), evolving emotional arcs, and varied acoustic environments. We introduce the Borderless Long Speech Synthesis framework for agent-centric, borderless long audio synthesis. Rather than targeting a single narrow task, the system is designed as a unified capability set spanning VoiceDesigner, multi-speaker synthesis, Instruct TTS, and long-form text synthesis. On the data side, we propose a "Labeling over filtering/cleaning" strategy and design a top-down, multi-level annotation schema we call Global-Sentence-Token. On the model side, we adopt a backbone with a continuous tokenizer and add Chain-of-Thought (CoT) reasoning together with Dimension Dropout, both of which markedly improve instruction following under complex conditions. We further show that the system is Native Agentic by design: the hierarchical annotation doubles as a Structured Semantic Interface between the LLM Agent and the synthesis engine, creating a layered control protocol stack that spans from scene semantics down to phonetic detail. Text thereby becomes an information-complete, wide-band control channel, enabling a front-end LLM to convert inputs of any modality into structured generation commands, extending the paradigm from Text2Speech to borderless long speech synthesis.
Thinking in cocktail party: Chain-of-Thought and reinforcement learning for target speaker automatic speech recognition
Sep 19, 2025Target Speaker Automatic Speech Recognition (TS-ASR) aims to transcribe the speech of a specified target speaker from multi-speaker mixtures in cocktail party scenarios. Recent advancement of Large Audio-Language Models (LALMs) has already brought some new insights to TS-ASR. However, significant room for optimization remains for the TS-ASR task within the LALMs architecture. While Chain of Thoughts (CoT) and Reinforcement Learning (RL) have proven effective in certain speech tasks, TS-ASR, which requires the model to deeply comprehend speech signals, differentiate various speakers, and handle overlapping utterances is particularly well-suited to a reasoning-guided approach. Therefore, we propose a novel framework that incorporates CoT and RL training into TS-ASR for performance improvement. A novel CoT dataset of TS-ASR is constructed, and the TS-ASR model is first trained on regular data and then fine-tuned on CoT data. Finally, the model is further trained with RL using selected data to enhance generalized reasoning capabilities. Experiment results demonstrate a significant improvement of TS-ASR performance with CoT and RL training, establishing a state-of-the-art performance compared with previous works of TS-ASR on comparable datasets.
Lightweight speech enhancement guided target speech extraction in noisy multi-speaker scenarios
Aug 27, 2025



Target speech extraction (TSE) has achieved strong performance in relatively simple conditions such as one-speaker-plus-noise and two-speaker mixtures, but its performance remains unsatisfactory in noisy multi-speaker scenarios. To address this issue, we introduce a lightweight speech enhancement model, GTCRN, to better guide TSE in noisy environments. Building on our competitive previous speaker embedding/encoder-free framework SEF-PNet, we propose two extensions: LGTSE and D-LGTSE. LGTSE incorporates noise-agnostic enrollment guidance by denoising the input noisy speech before context interaction with enrollment speech, thereby reducing noise interference. D-LGTSE further improves system robustness against speech distortion by leveraging denoised speech as an additional noisy input during training, expanding the dynamic range of noisy conditions and enabling the model to directly learn from distorted signals. Furthermore, we propose a two-stage training strategy, first with GTCRN enhancement-guided pre-training and then joint fine-tuning, to fully exploit model potential.Experiments on the Libri2Mix dataset demonstrate significant improvements of 0.89 dB in SISDR, 0.16 in PESQ, and 1.97% in STOI, validating the effectiveness of our approach. Our code is publicly available at https://github.com/isHuangZiling/D-LGTSE.
Multi-channel Speech Enhancement with 2-D Convolutional Time-frequency Domain Features and a Pre-trained Acoustic Model
Jul 26, 2021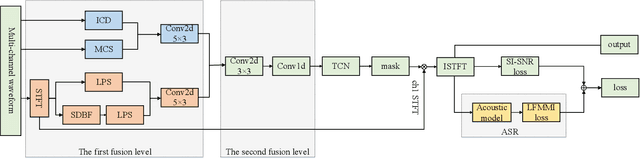
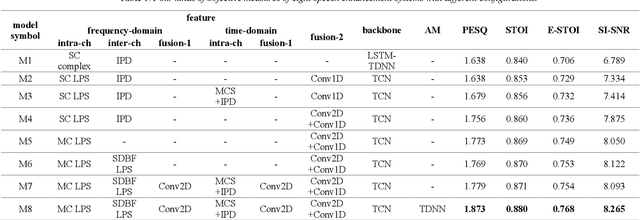
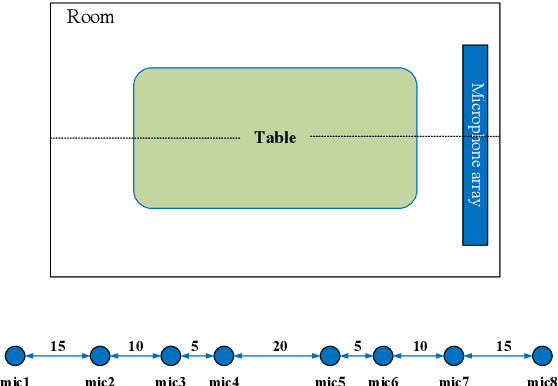

We propose a multi-channel speech enhancement approach with a novel two-stage feature fusion method and a pre-trained acoustic model in a multi-task learning paradigm. In the first fusion stage, the time-domain and frequency-domain features are extracted separately. In the time domain, the multi-channel convolution sum (MCS) and the inter-channel convolution differences (ICDs) features are computed and then integrated with a 2-D convolutional layer, while in the frequency domain, the log-power spectra (LPS) features from both original channels and super-directive beamforming outputs are combined with another 2-D convolutional layer. To fully integrate the rich information of multi-channel speech, i.e. time-frequency domain features and the array geometry, we apply a third 2-D convolutional layer in the second stage of fusion to obtain the final convolutional features. Furthermore, we propose to use a fixed clean acoustic model trained with the end-to-end lattice-free maximum mutual information criterion to enforce the enhanced output to have the same distribution as the clean waveform to alleviate the over-estimation problem of the enhancement task and constrain distortion. On the Task1 development dataset of the ConferencingSpeech 2021 challenge, a PESQ improvement of 0.24 and 0.19 is attained compared to the official baseline and a recently proposed multi-channel separation method.