 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Intelligence: Representation Learning, Information Fusion, and Applications
Nov 10, 2019Deep learning has revolutionized speech recognition, image recognition, and natural language processing since 2010, each involving a single modality in the input signal. However, many applications in artificial intelligence involve more than one modality. It is therefore of broad interest to study the more difficult and complex problem of modeling and learning across multiple modalities. In this paper, a technical review of the models and learning methods for multimodal intelligence is provided. The main focus is the combination of vision and natural language, which has become an important area in both computer vision and natural language processing research communities. This review provides a comprehensive analysis of recent work on multimodal deep learning from three new angles - learning multimodal representations, the fusion of multimodal signals at various levels, and multimodal applications. On multimodal representation learning, we review the key concept of embedding, which unifies the multimodal signals into the same vector space and thus enables cross-modality signal processing. We also review the properties of the many types of embedding constructed and learned for general downstream tasks. On multimodal fusion, this review focuses on special architectures for the integration of the representation of unimodal signals for a particular task. On applications, selected areas of a broad interest in current literature are covered, including caption generation, text-to-image generation, and visual question answering. We believe this review can facilitate future studies in the emerging field of multimodal intelligence for the community.
Toward Unsupervised Text Content Manipulation
Feb 08, 2019
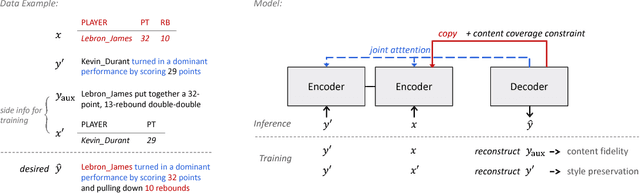
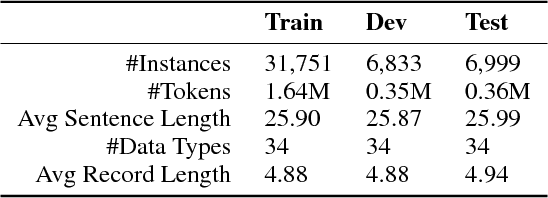
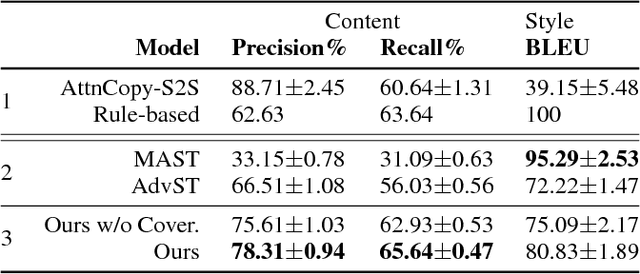
Controlled generation of text is of high practical use. Recent efforts have made impressive progress in generating or editing sentences with given textual attributes (e.g., sentiment). This work studies a new practical setting of text content manipulation. Given a structured record, such as `(PLAYER: Lebron, POINTS: 20, ASSISTS: 10)', and a reference sentence, such as `Kobe easily dropped 30 points', we aim to generate a sentence that accurately describes the full content in the record, with the same writing style (e.g., wording, transitions) of the reference. The problem is unsupervised due to lack of parallel data in practice, and is challenging to minimally yet effectively manipulate the text (by rewriting/adding/deleting text portions) to ensure fidelity to the structured content. We derive a dataset from a basketball game report corpus as our testbed, and develop a neural method with unsupervised competing objectives and explicit content coverage constraints. Automatic and human evaluations show superiority of our approach over competitive methods including a strong rule-based baseline and prior approaches designed for style transfer.
Connecting the Dots Between MLE and RL for Sequence Generation
Nov 24, 2018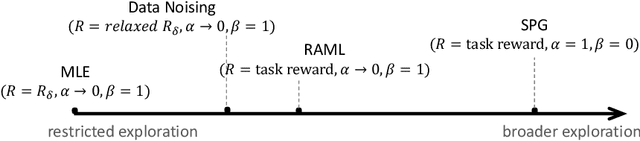
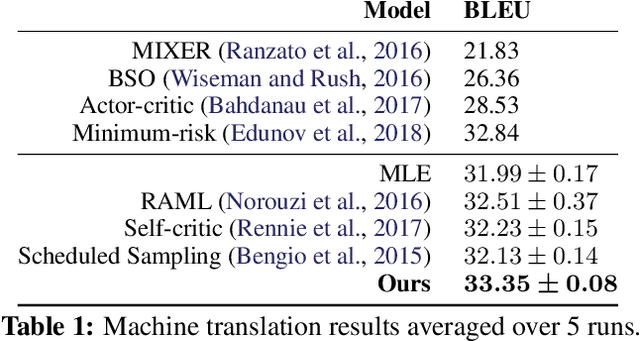
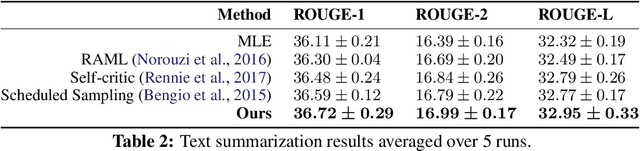
Sequence generation models such as recurrent networks can be trained with a diverse set of learning algorithms. For example, maximum likelihood learning is simple and efficient, yet suffers from the exposure bias problem. Reinforcement learning like policy gradient addresses the problem but can have prohibitively poor exploration efficiency. A variety of other algorithms such as RAML, SPG, and data noising, have also been developed from different perspectives. This paper establishes a formal connection between these algorithms. We present a generalized entropy regularized policy optimization formulation, and show that the apparently divergent algorithms can all be reformulated as special instances of the framework, with the only difference being the configurations of reward function and a couple of hyperparameters. The unified interpretation offers a systematic view of the varying properties of exploration and learning efficiency. Besides, based on the framework, we present a new algorithm that dynamically interpolates among the existing algorithms for improved learning. Experiments on machine translation and text summarization demonstrate the superiority of the proposed algorithm.
Toward Controlled Generation of Text
Sep 13, 2018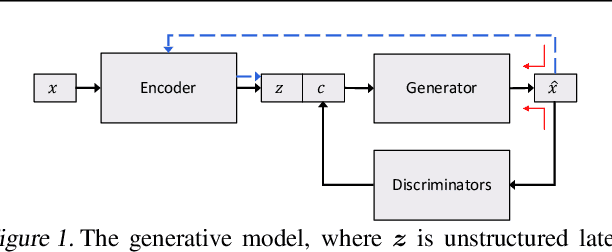
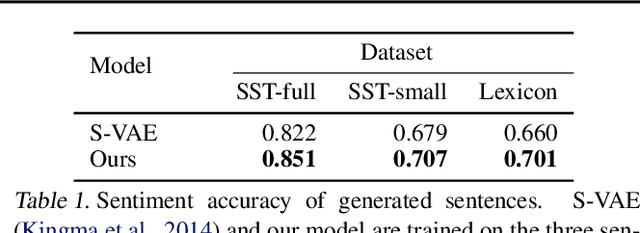
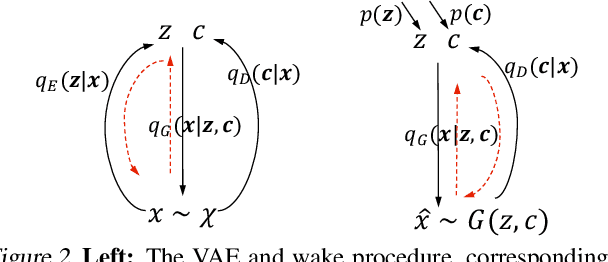
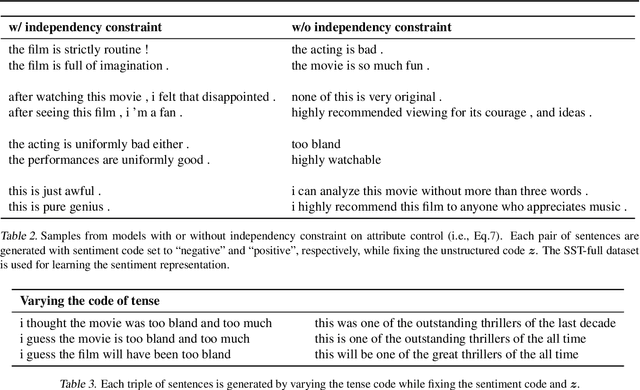
Generic generation and manipulation of text is challenging and has limited success compared to recent deep generative modeling in visual domain. This paper aims at generating plausible natural language sentences, whose attributes are dynamically controlled by learning disentangled latent representations with designated semantics. We propose a new neural generative model which combines variational auto-encoders and holistic attribute discriminators for effective imposition of semantic structures. With differentiable approximation to discrete text samples, explicit constraints on independent attribute controls, and efficient collaborative learning of generator and discriminators, our model learns highly interpretable representations from even only word annotations, and produces realistic sentences with desired attributes. Quantitative evaluation validates the accuracy of sentence and attribute generation.
Texar: A Modularized, Versatile, and Extensible Toolkit for Text Generation
Sep 04, 2018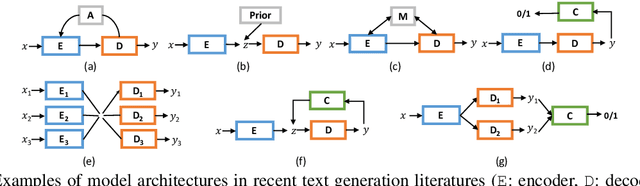
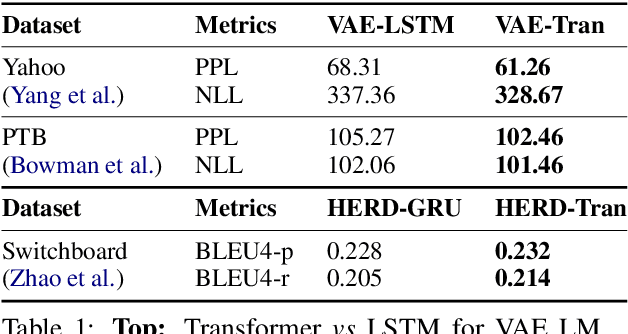
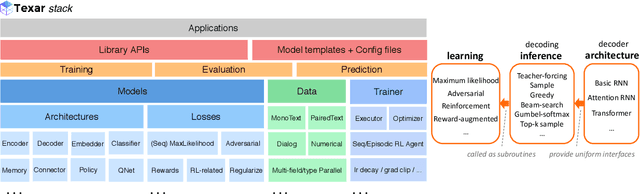

We introduce Texar, an open-source toolkit aiming to support the broad set of text generation tasks that transforms any inputs into natural language, such as machine translation, summarization, dialog, content manipulation, and so forth. With the design goals of modularity, versatility, and extensibility in mind, Texar extracts common patterns underlying the diverse tasks and methodologies, creates a library of highly reusable modules and functionalities, and allows arbitrary model architectures and algorithmic paradigms. In Texar, model architecture, losses, and learning processes are fully decomposed. Modules at high concept level can be freely assembled or plugged in/swapped out. These features make Texar particularly suitable for researchers and practitioners to do fast prototyping and experimentation, as well as foster technique sharing across different text generation tasks. We provide case studies to demonstrate the use and advantage of the toolkit. Texar is released under Apache license 2.0 at https://github.com/asyml/texar.
On Unifying Deep Generative Models
Jul 11, 2018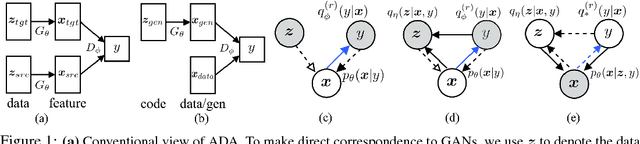

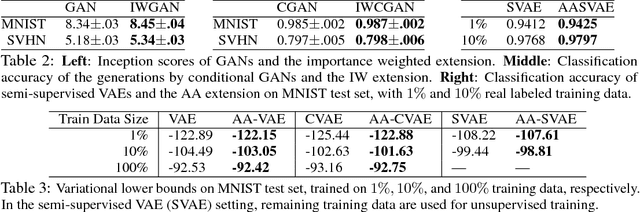
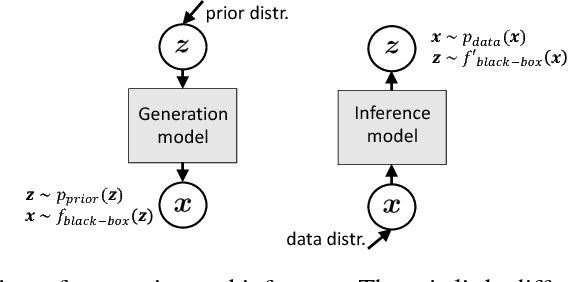
Deep generative models have achieved impressive success in recent years. Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs), as emerging families for generative model learning, have largely been considered as two distinct paradigms and received extensive independent studies respectively. This paper aims to establish formal connections between GANs and VAEs through a new formulation of them. We interpret sample generation in GANs as performing posterior inference, and show that GANs and VAEs involve minimizing KL divergences of respective posterior and inference distributions with opposite directions, extending the two learning phases of classic wake-sleep algorithm, respectively. The unified view provides a powerful tool to analyze a diverse set of existing model variants, and enables to transfer techniques across research lines in a principled way. For example, we apply the importance weighting method in VAE literatures for improved GAN learning, and enhance VAEs with an adversarial mechanism that leverages generated samples. Experiments show generality and effectiveness of the transferred techniques.
Deep Generative Models with Learnable Knowledge Constraints
Jun 26, 2018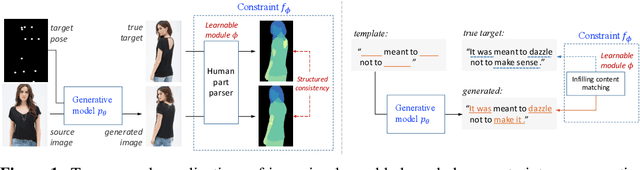

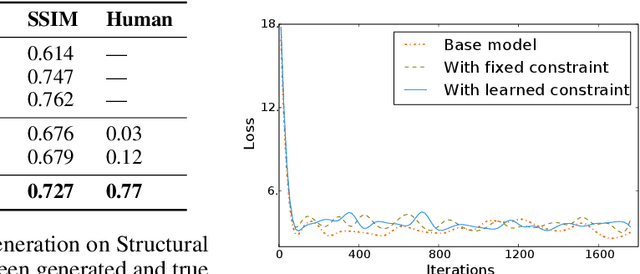
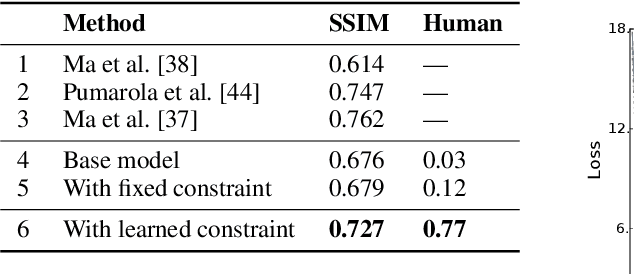
The broad set of deep generative models (DGMs) has achieved remarkable advances. However, it is often difficult to incorporate rich structured domain knowledge with the end-to-end DGMs. Posterior regularization (PR) offers a principled framework to impose structured constraints on probabilistic models, but has limited applicability to the diverse DGMs that can lack a Bayesian formulation or even explicit density evaluation. PR also requires constraints to be fully specified {\it a priori}, which is impractical or suboptimal for complex knowledge with learnable uncertain parts. In this paper, we establish mathematical correspondence between PR and reinforcement learning (RL), and, based on the connection, expand PR to learn constraints as the extrinsic reward in RL. The resulting algorithm is model-agnostic to apply to any DGMs, and is flexible to adapt arbitrary constraints with the model jointly. Experiments on human image generation and templated sentence generation show models with learned knowledge constraints by our algorithm greatly improve over base generative models.
Unsupervised Text Style Transfer using Language Models as Discriminators
May 31, 2018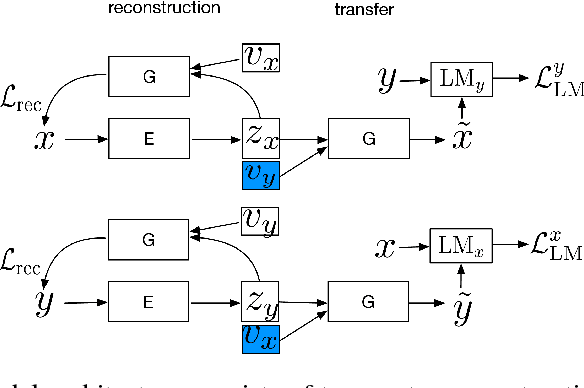
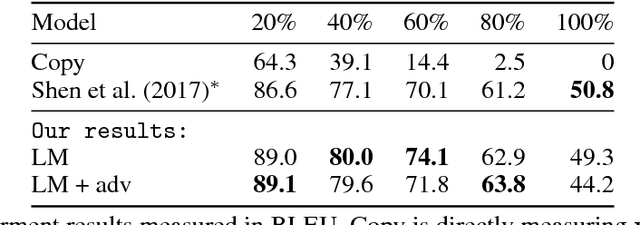
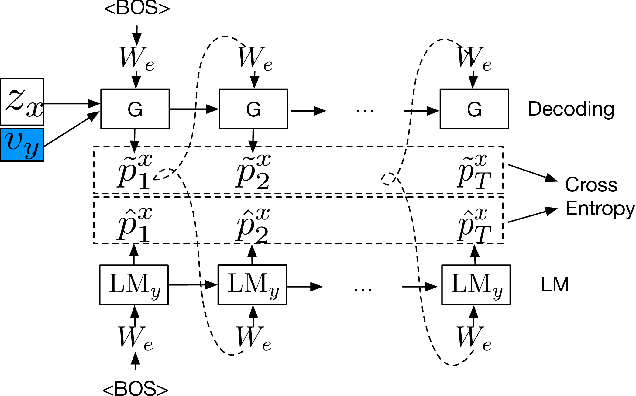
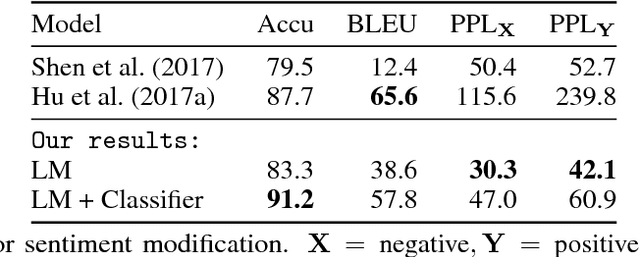
Binary classifiers are often employed as discriminators in GAN-based unsupervised style transfer systems to ensure that transferred sentences are similar to sentences in the target domain. One difficulty with this approach is that the error signal provided by the discriminator can be unstable and is sometimes insufficient to train the generator to produce fluent language. In this paper, we propose a new technique that uses a target domain language model as the discriminator, providing richer and more stable token-level feedback during the learning process. We train the generator to minimize the negative log likelihood (NLL) of generated sentences, evaluated by the language model. By using a continuous approximation of discrete sampling under the generator, our model can be trained using back-propagation in an end- to-end fashion. Moreover, our empirical results show that when using a language model as a structured discriminator, it is possible to forgoe adversarial steps during training, making the process more stable. We compare our model with previous work using convolutional neural networks (CNNs) as discriminators and show that our approach leads to improved performance on three tasks: word substitution decipherment, sentiment modification, and related language translation.
Reference-Aware Language Models
Aug 09, 2017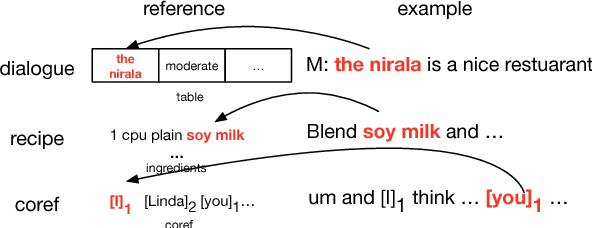

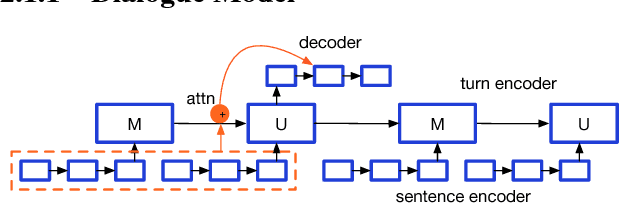
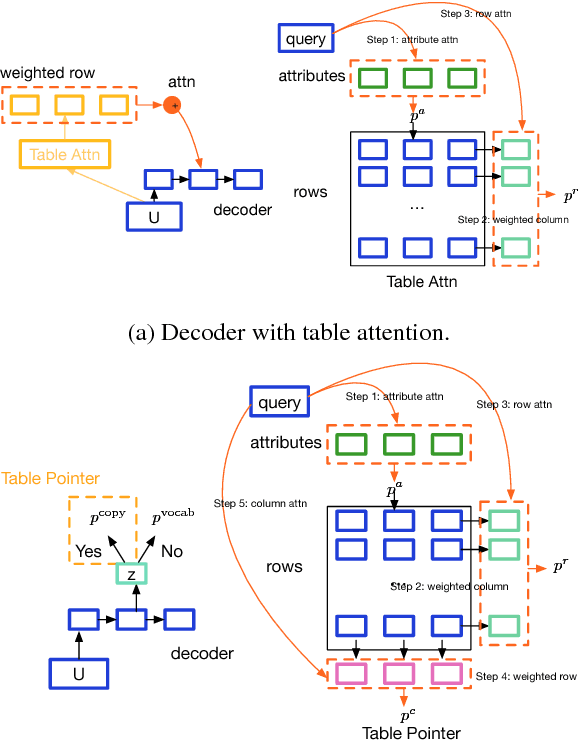
We propose a general class of language models that treat reference as an explicit stochastic latent variable. This architecture allows models to create mentions of entities and their attributes by accessing external databases (required by, e.g., dialogue generation and recipe generation) and internal state (required by, e.g. language models which are aware of coreference). This facilitates the incorporation of information that can be accessed in predictable locations in databases or discourse context, even when the targets of the reference may be rare words. Experiments on three tasks shows our model variants based on deterministic attention.
Improved Variational Autoencoders for Text Modeling using Dilated Convolutions
Jun 18, 2017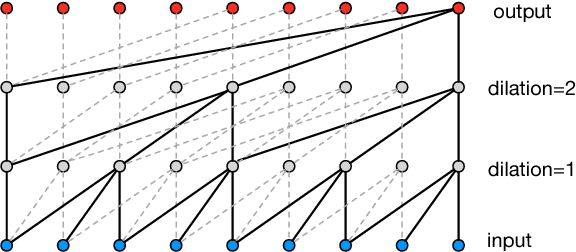
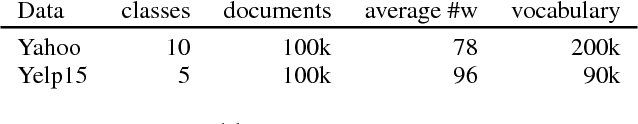
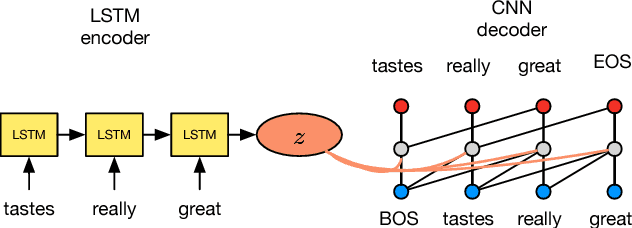
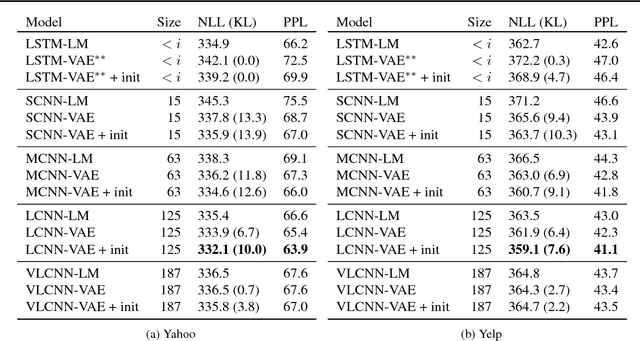
Recent work on generative modeling of text has found that variational auto-encoders (VAE) incorporating LSTM decoders perform worse than simpler LSTM language models (Bowman et al., 2015). This negative result is so far poorly understood, but has been attributed to the propensity of LSTM decoders to ignore conditioning information from the encoder. In this paper, we experiment with a new type of decoder for VAE: a dilated CNN. By changing the decoder's dilation architecture, we control the effective context from previously generated words. In experiments, we find that there is a trade off between the contextual capacity of the decoder and the amount of encoding information used. We show that with the right decoder, VAE can outperform LSTM language models. We demonstrate perplexity gains on two datasets, representing the first positive experimental result on the use VAE for generative modeling of text. Further, we conduct an in-depth investigation of the use of VAE (with our new decoding architecture) for semi-supervised and unsupervised labeling tasks, demonstrating gains over several strong baselines.