 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSources of Noise in Dialogue and How to Deal with Them
Dec 06, 2022



Training dialogue systems often entails dealing with noisy training examples and unexpected user inputs. Despite their prevalence, there currently lacks an accurate survey of dialogue noise, nor is there a clear sense of the impact of each noise type on task performance. This paper addresses this gap by first constructing a taxonomy of noise encountered by dialogue systems. In addition, we run a series of experiments to show how different models behave when subjected to varying levels of noise and types of noise. Our results reveal that models are quite robust to label errors commonly tackled by existing denoising algorithms, but that performance suffers from dialogue-specific noise. Driven by these observations, we design a data cleaning algorithm specialized for conversational settings and apply it as a proof-of-concept for targeted dialogue denoising.
Focus! Relevant and Sufficient Context Selection for News Image Captioning
Dec 01, 2022



News Image Captioning requires describing an image by leveraging additional context from a news article. Previous works only coarsely leverage the article to extract the necessary context, which makes it challenging for models to identify relevant events and named entities. In our paper, we first demonstrate that by combining more fine-grained context that captures the key named entities (obtained via an oracle) and the global context that summarizes the news, we can dramatically improve the model's ability to generate accurate news captions. This begs the question, how to automatically extract such key entities from an image? We propose to use the pre-trained vision and language retrieval model CLIP to localize the visually grounded entities in the news article and then capture the non-visual entities via an open relation extraction model. Our experiments demonstrate that by simply selecting a better context from the article, we can significantly improve the performance of existing models and achieve new state-of-the-art performance on multiple benchmarks.
AutoReply: Detecting Nonsense in Dialogue Introspectively with Discriminative Replies
Nov 22, 2022



Existing approaches built separate classifiers to detect nonsense in dialogues. In this paper, we show that without external classifiers, dialogue models can detect errors in their own messages introspectively, by calculating the likelihood of replies that are indicative of poor messages. For example, if an agent believes its partner is likely to respond "I don't understand" to a candidate message, that message may not make sense, so an alternative message should be chosen. We evaluate our approach on a dataset from the game Diplomacy, which contains long dialogues richly grounded in the game state, on which existing models make many errors. We first show that hand-crafted replies can be effective for the task of detecting nonsense in applications as complex as Diplomacy. We then design AutoReply, an algorithm to search for such discriminative replies automatically, given a small number of annotated dialogue examples. We find that AutoReply-generated replies outperform handcrafted replies and perform on par with carefully fine-tuned large supervised models. Results also show that one single reply without much computation overheads can also detect dialogue nonsense reasonably well.
Weakly Supervised Data Augmentation Through Prompting for Dialogue Understanding
Nov 02, 2022



Dialogue understanding tasks often necessitate abundant annotated data to achieve good performance and that presents challenges in low-resource settings. To alleviate this barrier, we explore few-shot data augmentation for dialogue understanding by prompting large pre-trained language models and present a novel approach that iterates on augmentation quality by applying weakly-supervised filters. We evaluate our methods on the emotion and act classification tasks in DailyDialog and the intent classification task in Facebook Multilingual Task-Oriented Dialogue. Models fine-tuned on our augmented data mixed with few-shot ground truth data are able to approach or surpass existing state-of-the-art performance on both datasets. For DailyDialog specifically, using 10% of the ground truth data we outperform the current state-of-the-art model which uses 100% of the data.
Affective Idiosyncratic Responses to Music
Oct 17, 2022
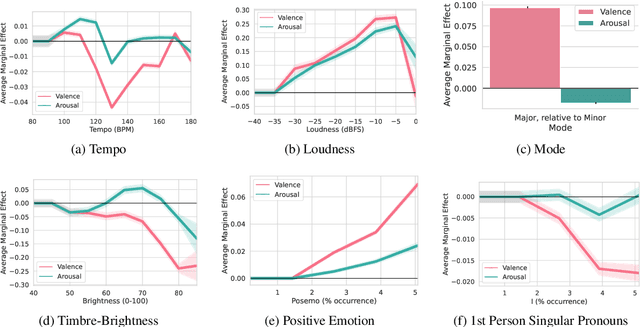
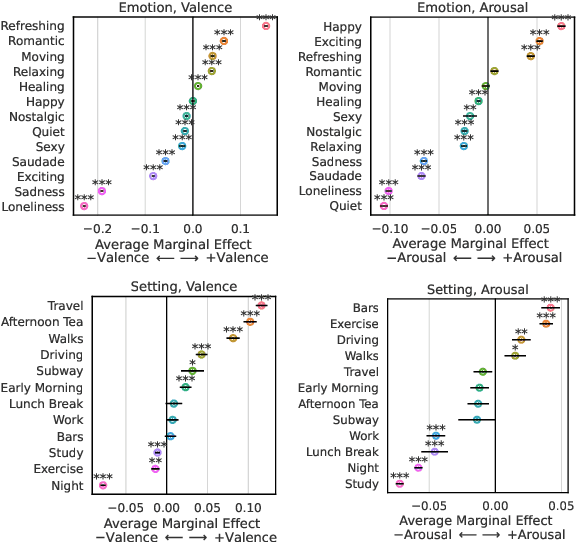
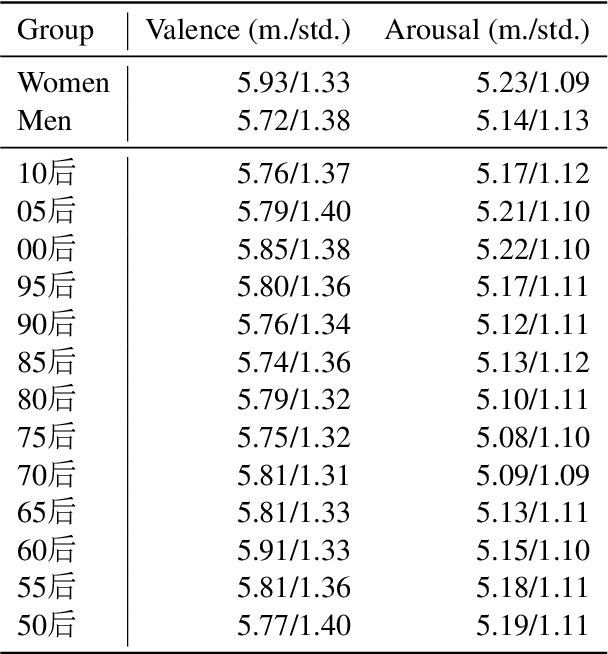
Affective responses to music are highly personal. Despite consensus that idiosyncratic factors play a key role in regulating how listeners emotionally respond to music, precisely measuring the marginal effects of these variables has proved challenging. To address this gap, we develop computational methods to measure affective responses to music from over 403M listener comments on a Chinese social music platform. Building on studies from music psychology in systematic and quasi-causal analyses, we test for musical, lyrical, contextual, demographic, and mental health effects that drive listener affective responses. Finally, motivated by the social phenomenon known as w\v{a}ng-y\`i-y\'un, we identify influencing factors of platform user self-disclosures, the social support they receive, and notable differences in discloser user activity.
Social Influence Dialogue Systems: A Scoping Survey of the Efforts Towards Influence Capabilities of Dialogue Systems
Oct 11, 2022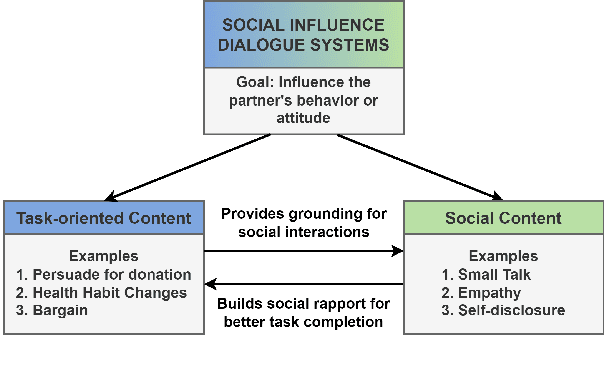
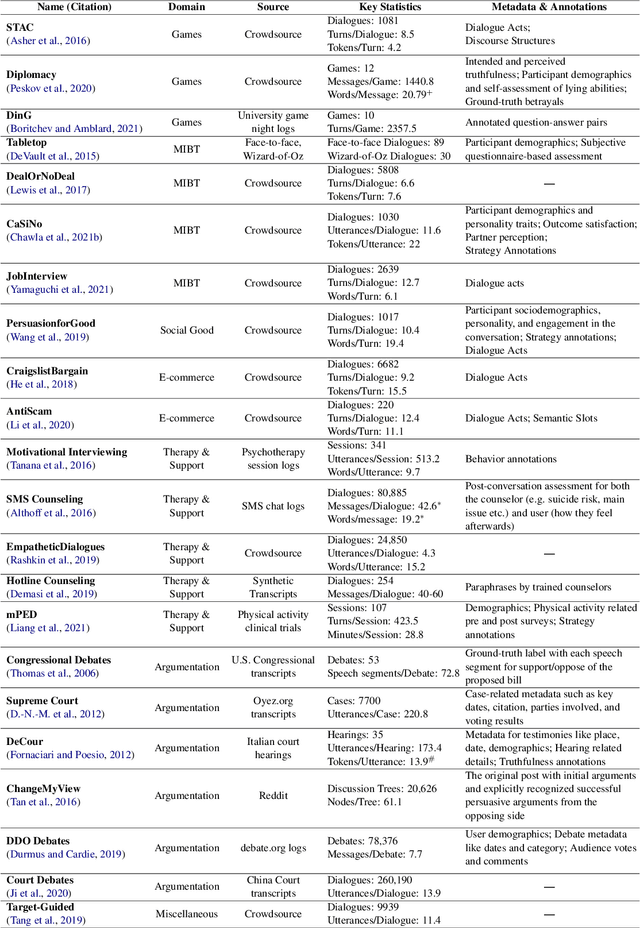
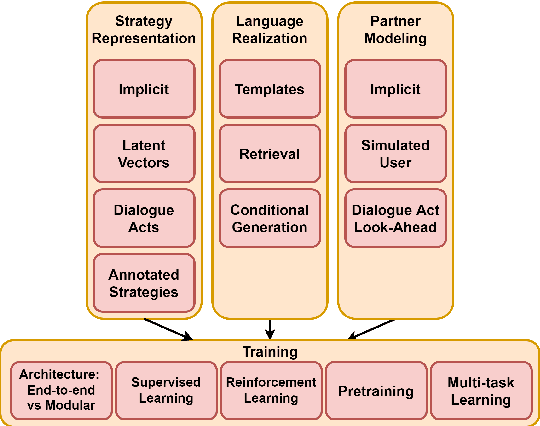
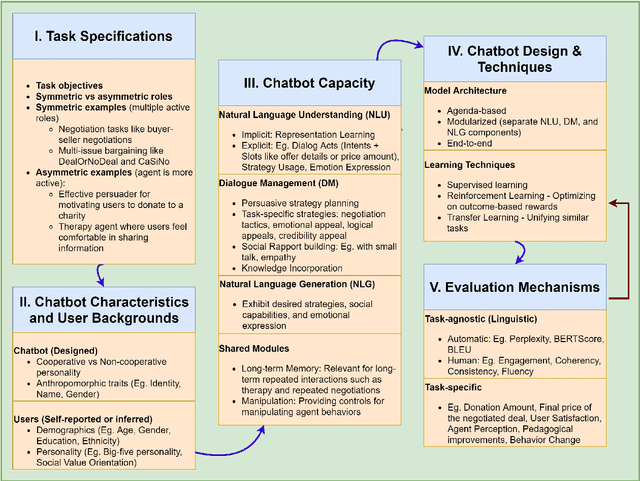
Dialogue systems capable of social influence such as persuasion, negotiation, and therapy, are essential for extending the use of technology to numerous realistic scenarios. However, existing research primarily focuses on either task-oriented or open-domain scenarios, a categorization that has been inadequate for capturing influence skills systematically. There exists no formal definition or category for dialogue systems with these skills and data-driven efforts in this direction are highly limited. In this work, we formally define and introduce the category of \emph{social influence dialogue systems} that influence users' cognitive and emotional responses, leading to changes in thoughts, opinions, and behaviors through natural conversations. We present a survey of various tasks, datasets, and methods, compiling the progress across seven diverse domains. We discuss the commonalities and differences between the examined systems, identify limitations, and recommend future directions. This study serves as a comprehensive reference for social influence dialogue systems to inspire more dedicated research and discussion in this emerging area.
On the Relation between Sensitivity and Accuracy in In-context Learning
Sep 16, 2022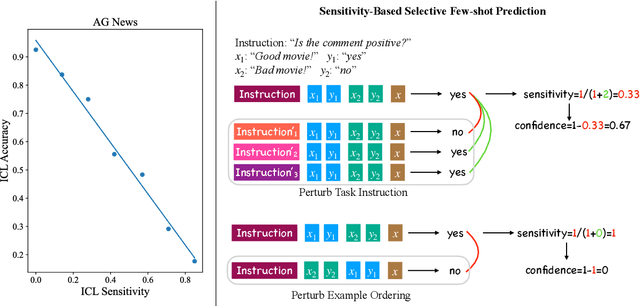
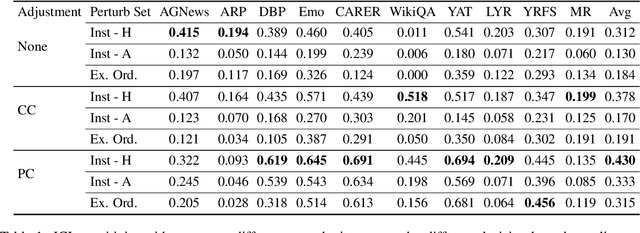
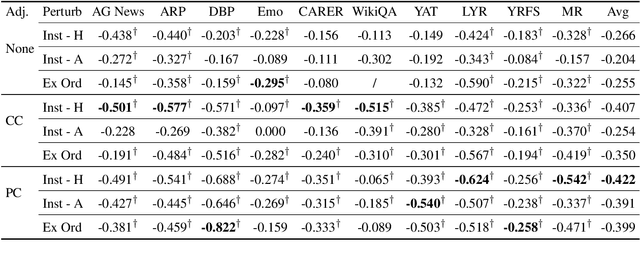
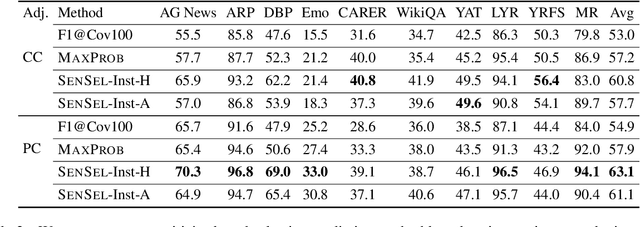
In-context learning (ICL) suffers from oversensitivity to the prompt, which makes it unreliable in real-world scenarios. We study the sensitivity of ICL with respect to multiple types of perturbations. First, we find that label bias obscures true ICL sensitivity, and hence prior work may have significantly underestimated the true ICL sensitivity. Second, we observe a strong negative correlation between ICL sensitivity and accuracy, with sensitive predictions less likely to be correct. Motivated by these observations, we propose \textsc{SenSel}, a few-shot selective prediction method based on ICL sensitivity. Experiments on ten classification benchmarks show that \textsc{SenSel} consistently outperforms a commonly used confidence-based selective prediction baseline.
Stateful Memory-Augmented Transformers for Dialogue Modeling
Sep 15, 2022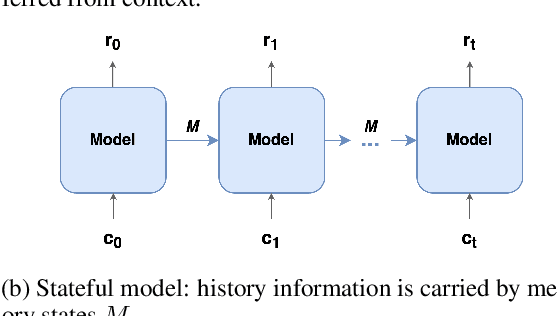
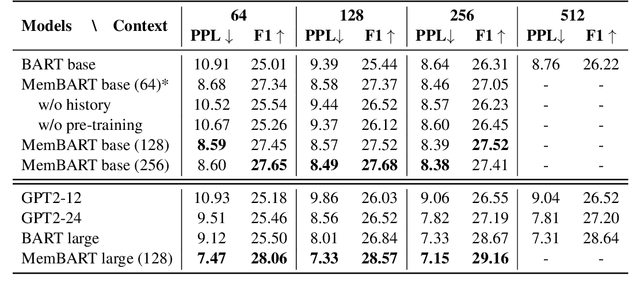
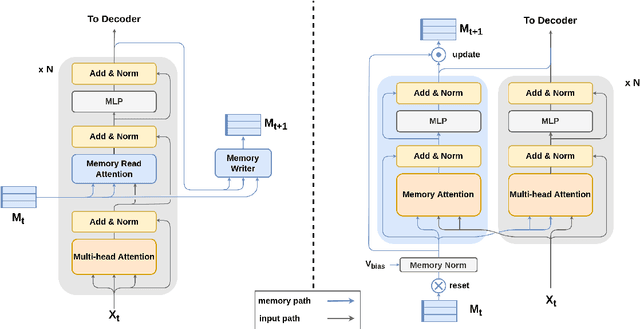
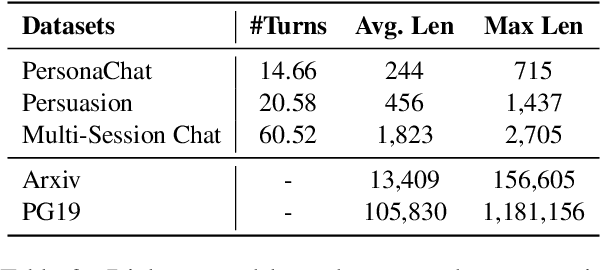
Transformer encoder-decoder models have shown impressive performance in dialogue modeling. However, as Transformers are inefficient in processing long sequences, dialogue history length often needs to be truncated. To address this problem, we propose a new memory-augmented Transformer that is compatible with existing pre-trained encoder-decoder models and enables efficient preservation of history information. It incorporates a separate memory module alongside the pre-trained Transformer to effectively interchange information between the memory states and the current input context. We evaluate our model on three dialogue datasets and two language modeling datasets. Experimental results show that our method has achieved superior efficiency and performance compared to other pre-trained Transformer baselines.
Using Chatbots to Teach Languages
Jul 31, 2022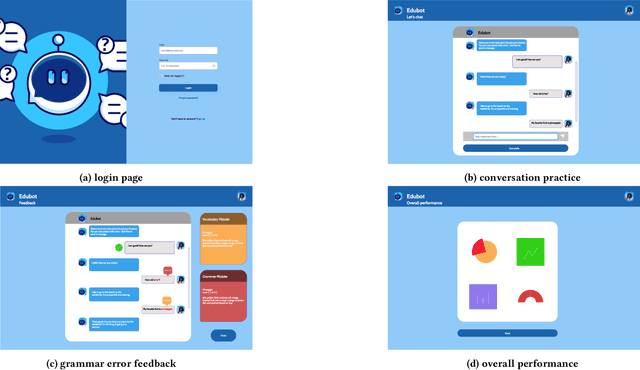

This paper reports on progress towards building an online language learning tool to provide learners with conversational experience by using dialog systems as conversation practice partners. Our system can adapt to users' language proficiency on the fly. We also provide automatic grammar error feedback to help users learn from their mistakes. According to our first adopters, our system is entertaining and useful. Furthermore, we will provide the learning technology community a large-scale conversation dataset on language learning and grammar correction. Our next step is to make our system more adaptive to user profile information by using reinforcement learning algorithms.
GODEL: Large-Scale Pre-Training for Goal-Directed Dialog
Jun 22, 2022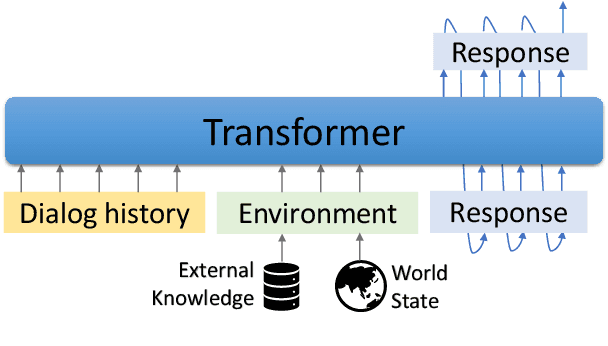
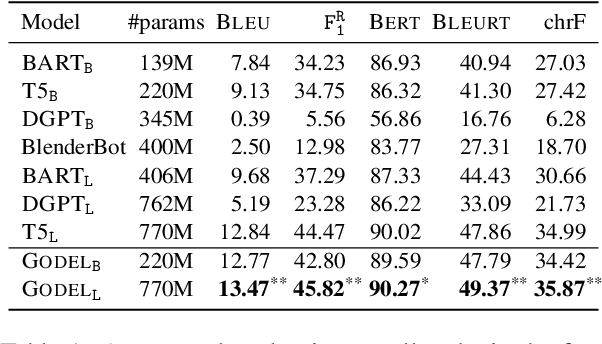

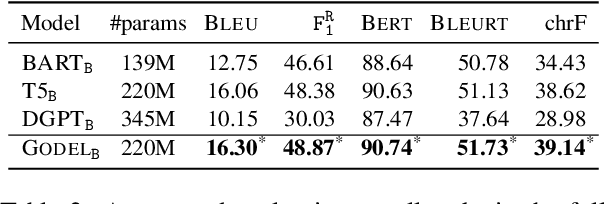
We introduce GODEL (Grounded Open Dialogue Language Model), a large pre-trained language model for dialog. In contrast with earlier models such as DialoGPT, GODEL leverages a new phase of grounded pre-training designed to better support adapting GODEL to a wide range of downstream dialog tasks that require information external to the current conversation (e.g., a database or document) to produce good responses. Experiments against an array of benchmarks that encompass task-oriented dialog, conversational QA, and grounded open-domain dialog show that GODEL outperforms state-of-the-art pre-trained dialog models in few-shot fine-tuning setups, in terms of both human and automatic evaluation. A novel feature of our evaluation methodology is the introduction of a notion of utility that assesses the usefulness of responses (extrinsic evaluation) in addition to their communicative features (intrinsic evaluation). We show that extrinsic evaluation offers improved inter-annotator agreement and correlation with automated metrics. Code and data processing scripts are publicly available.