 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnotation Inconsistency and Entity Bias in MultiWOZ
Paper and Code

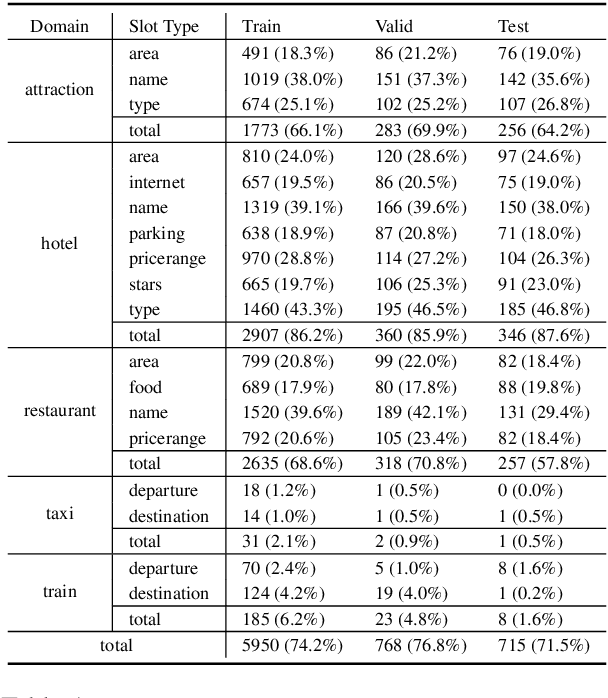
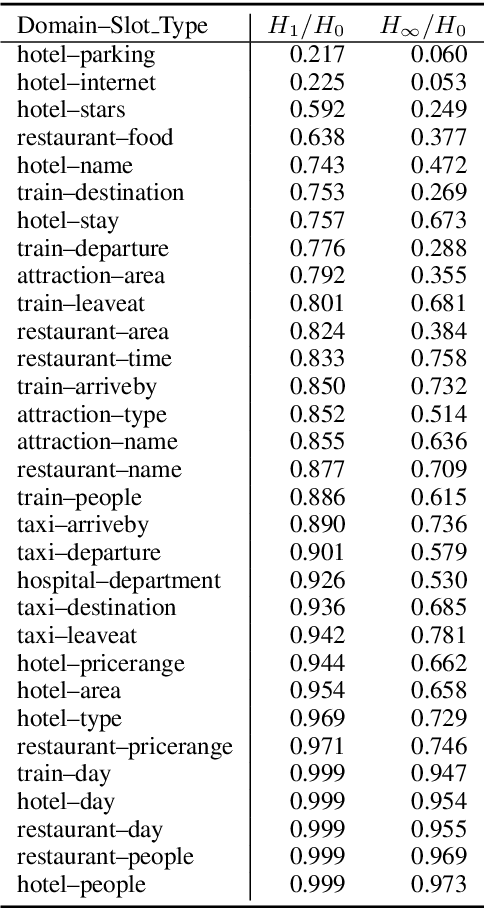

MultiWOZ is one of the most popular multi-domain task-oriented dialog datasets, containing 10K+ annotated dialogs covering eight domains. It has been widely accepted as a benchmark for various dialog tasks, e.g., dialog state tracking (DST), natural language generation (NLG), and end-to-end (E2E) dialog modeling. In this work, we identify an overlooked issue with dialog state annotation inconsistencies in the dataset, where a slot type is tagged inconsistently across similar dialogs leading to confusion for DST modeling. We propose an automated correction for this issue, which is present in a whopping 70% of the dialogs. Additionally, we notice that there is significant entity bias in the dataset (e.g., "cambridge" appears in 50% of the destination cities in the train domain). The entity bias can potentially lead to named entity memorization in generative models, which may go unnoticed as the test set suffers from a similar entity bias as well. We release a new test set with all entities replaced with unseen entities. Finally, we benchmark joint goal accuracy (JGA) of the state-of-the-art DST baselines on these modified versions of the data. Our experiments show that the annotation inconsistency corrections lead to 7-10% improvement in JGA. On the other hand, we observe a 29% drop in JGA when models are evaluated on the new test set with unseen entities.