 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Regionlets for Object Detection
Aug 23, 2018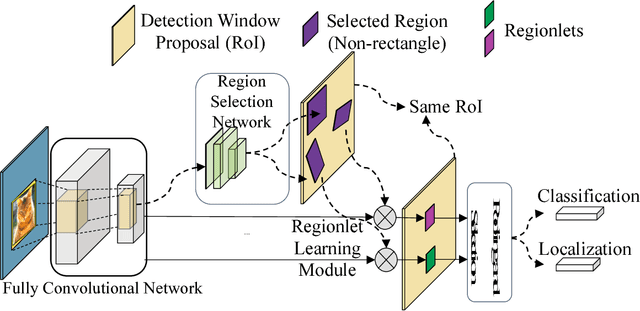
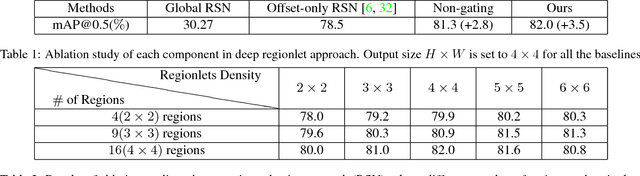
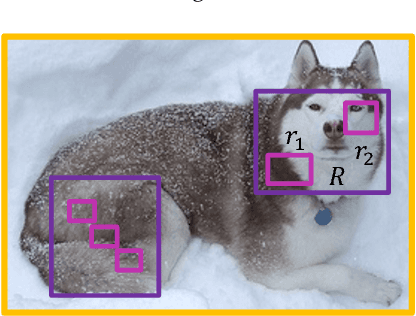
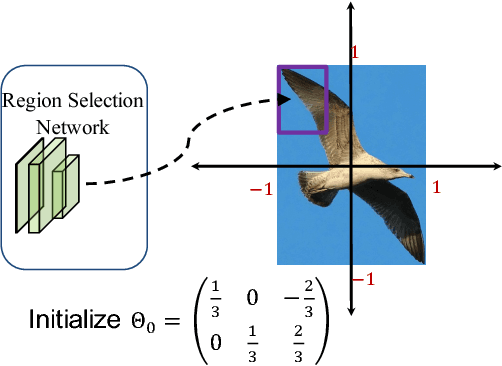
In this paper, we propose a novel object detection framework named "Deep Regionlets" by establishing a bridge between deep neural networks and conventional detection schema for accurate generic object detection. Motivated by the abilities of regionlets for modeling object deformation and multiple aspect ratios, we incorporate regionlets into an end-to-end trainable deep learning framework. The deep regionlets framework consists of a region selection network and a deep regionlet learning module. Specifically, given a detection bounding box proposal, the region selection network provides guidance on where to select regions to learn the features from. The regionlet learning module focuses on local feature selection and transformation to alleviate local variations. To this end, we first realize non-rectangular region selection within the detection framework to accommodate variations in object appearance. Moreover, we design a "gating network" within the regionlet leaning module to enable soft regionlet selection and pooling. The Deep Regionlets framework is trained end-to-end without additional efforts. We perform ablation studies and conduct extensive experiments on the PASCAL VOC and Microsoft COCO datasets. The proposed framework outperforms state-of-the-art algorithms, such as RetinaNet and Mask R-CNN, even without additional segmentation labels.
Improving Transferability of Adversarial Examples with Input Diversity
Jun 11, 2018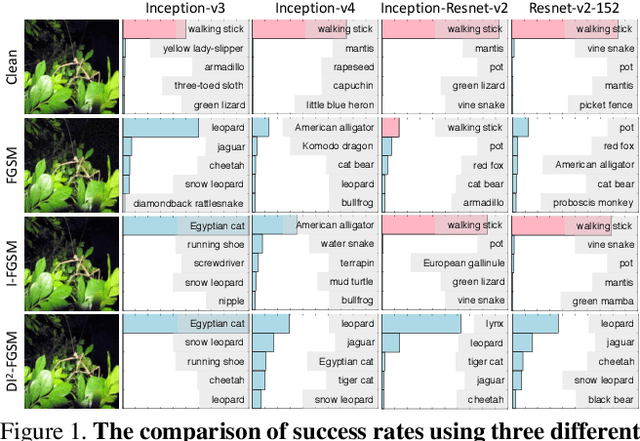
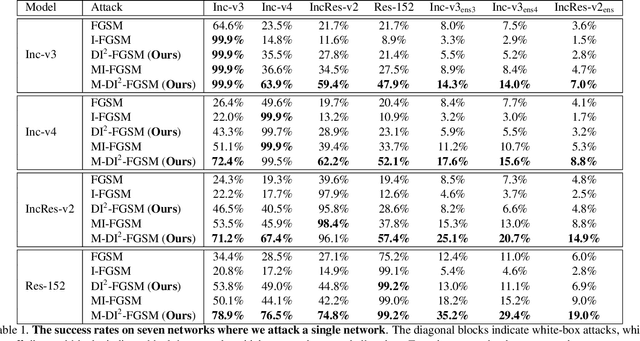
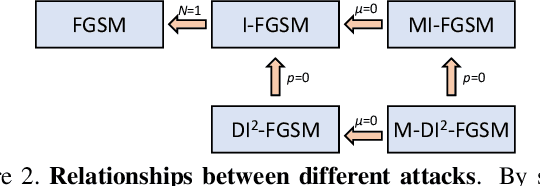

Though convolutional neural networks have achieved state-of-the-art performance on various vision tasks, they are extremely vulnerable to adversarial examples, which are obtained by adding human-imperceptible perturbations to the original images. Adversarial examples can thus be used as an useful tool to evaluate and select the most robust models in safety-critical applications. However, most of the existing adversarial attacks only achieve relatively low success rates under the challenging black-box setting, where the attackers have no knowledge of the model structure and parameters. To this end, we propose to improve the transferability of adversarial examples by creating diverse input patterns. Instead of only using the original images to generate adversarial examples, our method applies random transformations to the input images at each iteration. Extensive experiments on ImageNet show that the proposed attack method can generate adversarial examples that transfer much better to different networks than existing baselines. To further improve the transferability, we (1) integrate the recently proposed momentum method into the attack process; and (2) attack an ensemble of networks simultaneously. By evaluating our method against top defense submissions and official baselines from NIPS 2017 adversarial competition, this enhanced attack reaches an average success rate of 73.0%, which outperforms the top 1 attack submission in the NIPS competition by a large margin of 6.6%. We hope that our proposed attack strategy can serve as a benchmark for evaluating the robustness of networks to adversaries and the effectiveness of different defense methods in future. The code is public available at https://github.com/cihangxie/DI-2-FGSM.
An Aggressive Genetic Programming Approach for Searching Neural Network Structure Under Computational Constraints
Jun 03, 2018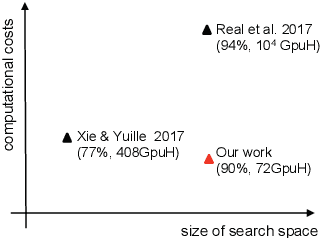
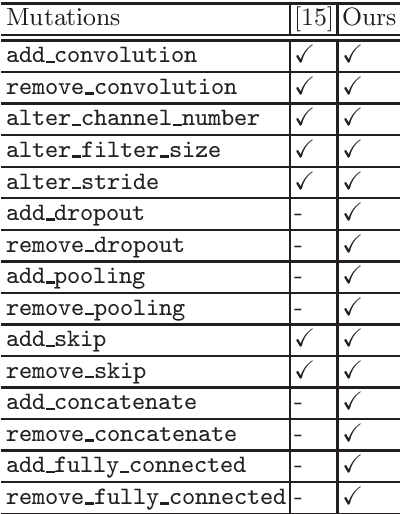
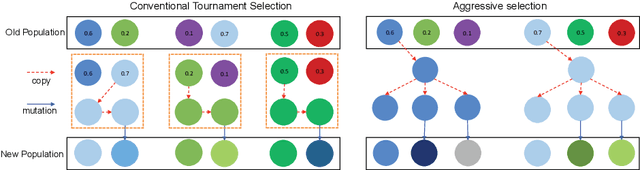
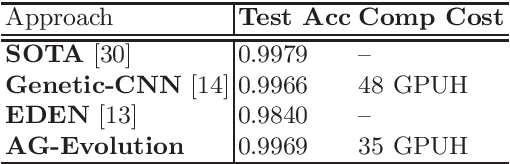
Recently, there emerged revived interests of designing automatic programs (e.g., using genetic/evolutionary algorithms) to optimize the structure of Convolutional Neural Networks (CNNs) for a specific task. The challenge in designing such programs lies in how to balance between large search space of the network structures and high computational costs. Existing works either impose strong restrictions on the search space or use enormous computing resources. In this paper, we study how to design a genetic programming approach for optimizing the structure of a CNN for a given task under limited computational resources yet without imposing strong restrictions on the search space. To reduce the computational costs, we propose two general strategies that are observed to be helpful: (i) aggressively selecting strongest individuals for survival and reproduction, and killing weaker individuals at a very early age; (ii) increasing mutation frequency to encourage diversity and faster evolution. The combined strategy with additional optimization techniques allows us to explore a large search space but with affordable computational costs. Our results on standard benchmark datasets (MNIST, SVHN, CIFAR-10, CIFAR-100) are competitive to similar approaches with significantly reduced computational costs.
Adversarial Attacks and Defences Competition
Mar 31, 2018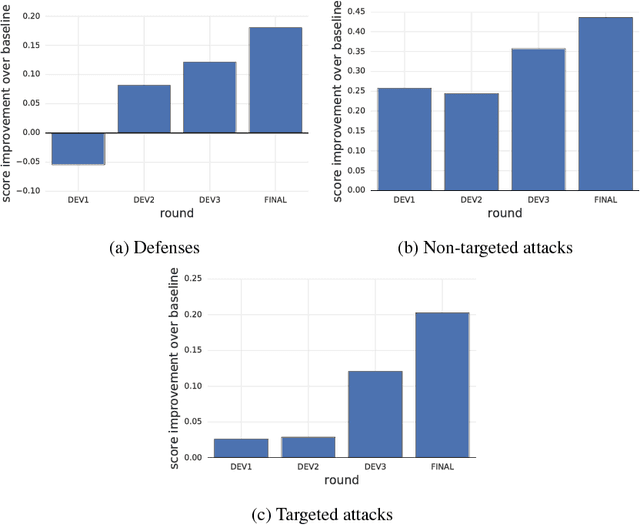
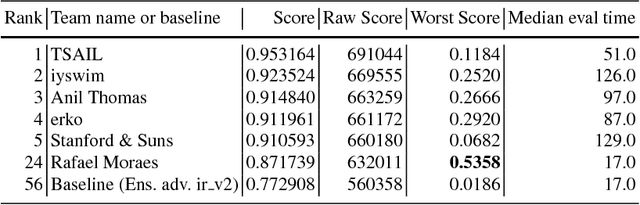
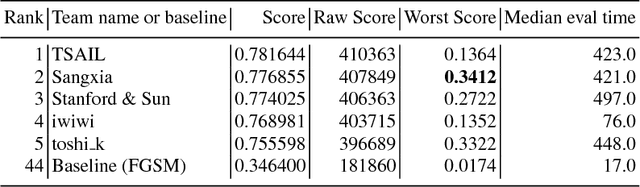
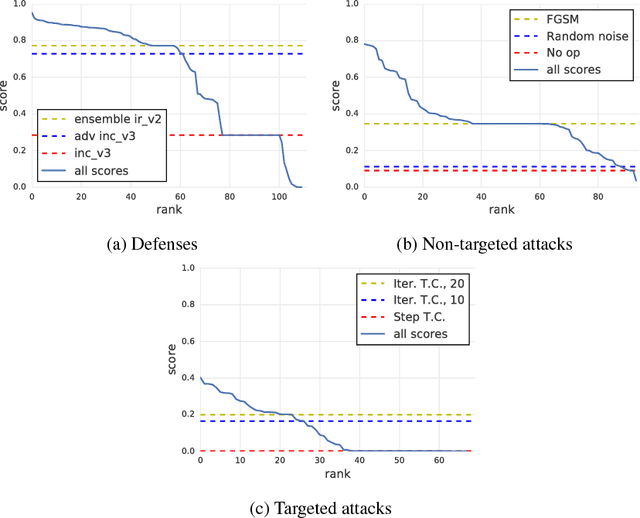
To accelerate research on adversarial examples and robustness of machine learning classifiers, Google Brain organized a NIPS 2017 competition that encouraged researchers to develop new methods to generate adversarial examples as well as to develop new ways to defend against them. In this chapter, we describe the structure and organization of the competition and the solutions developed by several of the top-placing teams.
Mitigating Adversarial Effects Through Randomization
Feb 28, 2018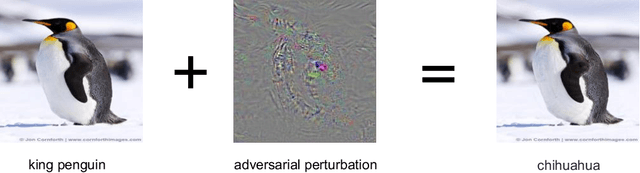

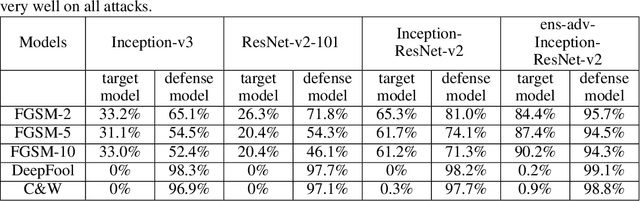
Convolutional neural networks have demonstrated high accuracy on various tasks in recent years. However, they are extremely vulnerable to adversarial examples. For example, imperceptible perturbations added to clean images can cause convolutional neural networks to fail. In this paper, we propose to utilize randomization at inference time to mitigate adversarial effects. Specifically, we use two randomization operations: random resizing, which resizes the input images to a random size, and random padding, which pads zeros around the input images in a random manner. Extensive experiments demonstrate that the proposed randomization method is very effective at defending against both single-step and iterative attacks. Our method provides the following advantages: 1) no additional training or fine-tuning, 2) very few additional computations, 3) compatible with other adversarial defense methods. By combining the proposed randomization method with an adversarially trained model, it achieves a normalized score of 0.924 (ranked No.2 among 107 defense teams) in the NIPS 2017 adversarial examples defense challenge, which is far better than using adversarial training alone with a normalized score of 0.773 (ranked No.56). The code is public available at https://github.com/cihangxie/NIPS2017_adv_challenge_defense.
Deep Reinforcement Learning-based Image Captioning with Embedding Reward
Apr 12, 2017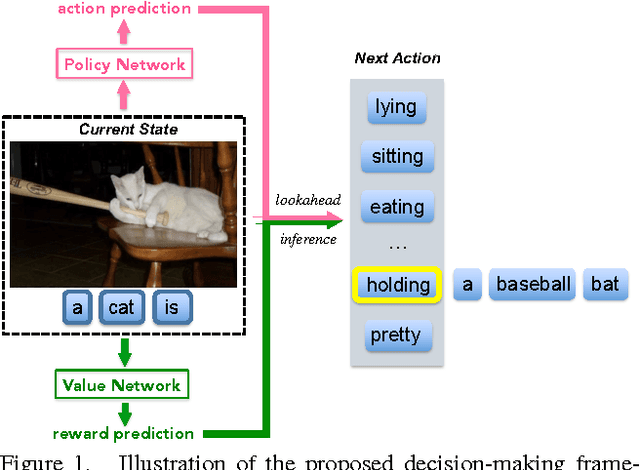
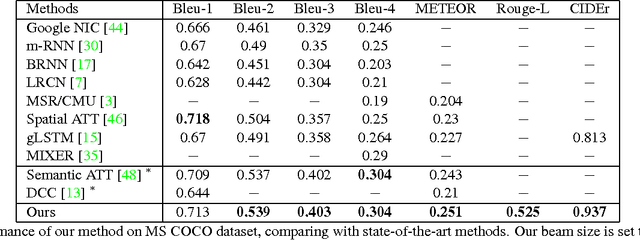
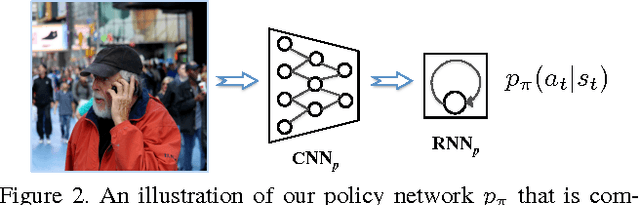
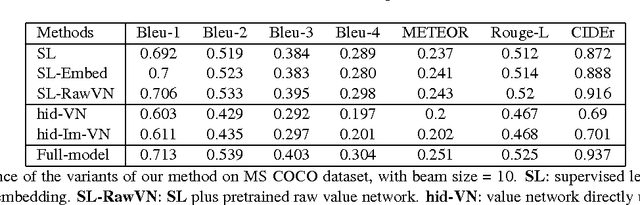
Image captioning is a challenging problem owing to the complexity in understanding the image content and diverse ways of describing it in natural language. Recent advances in deep neural networks have substantially improved the performance of this task. Most state-of-the-art approaches follow an encoder-decoder framework, which generates captions using a sequential recurrent prediction model. However, in this paper, we introduce a novel decision-making framework for image captioning. We utilize a "policy network" and a "value network" to collaboratively generate captions. The policy network serves as a local guidance by providing the confidence of predicting the next word according to the current state. Additionally, the value network serves as a global and lookahead guidance by evaluating all possible extensions of the current state. In essence, it adjusts the goal of predicting the correct words towards the goal of generating captions similar to the ground truth captions. We train both networks using an actor-critic reinforcement learning model, with a novel reward defined by visual-semantic embedding. Extensive experiments and analyses on the Microsoft COCO dataset show that the proposed framework outperforms state-of-the-art approaches across different evaluation metrics.
Multi-Instance Visual-Semantic Embedding
Dec 22, 2015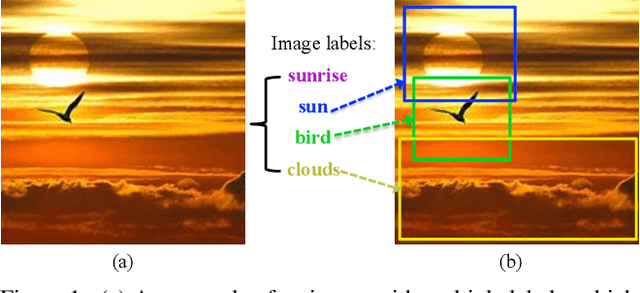
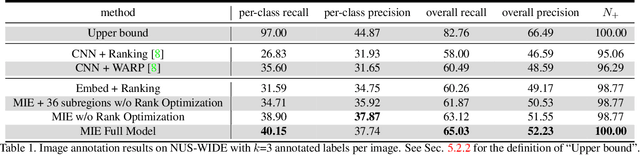
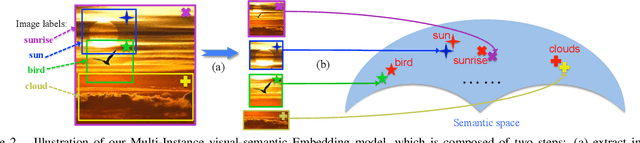
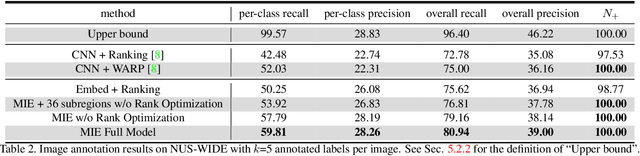
Visual-semantic embedding models have been recently proposed and shown to be effective for image classification and zero-shot learning, by mapping images into a continuous semantic label space. Although several approaches have been proposed for single-label embedding tasks, handling images with multiple labels (which is a more general setting) still remains an open problem, mainly due to the complex underlying corresponding relationship between image and its labels. In this work, we present Multi-Instance visual-semantic Embedding model (MIE) for embedding images associated with either single or multiple labels. Our model discovers and maps semantically-meaningful image subregions to their corresponding labels. And we demonstrate the superiority of our method over the state-of-the-art on two tasks, including multi-label image annotation and zero-shot learning.