 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Model-based Safety and Model-free Reinforcement Learning through System Identification of Low Dimensional Linear Models
May 11, 2022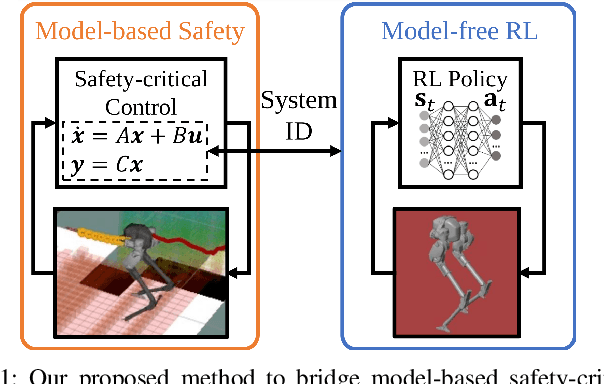
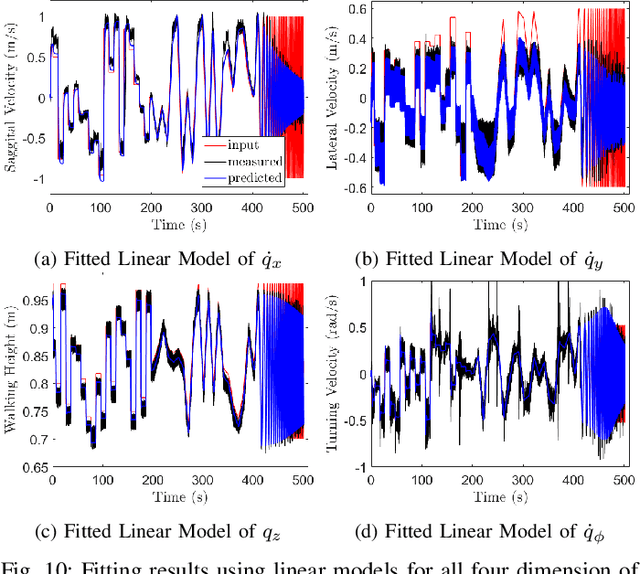
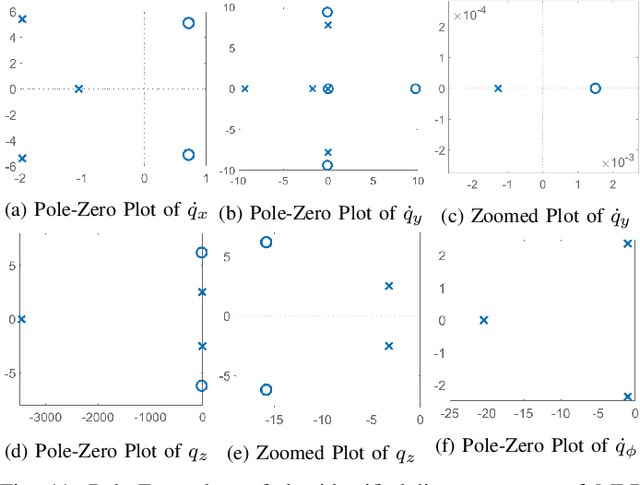
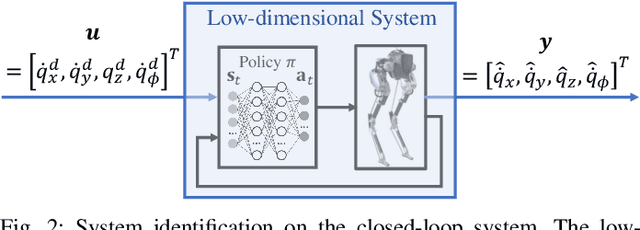
Bridging model-based safety and model-free reinforcement learning (RL) for dynamic robots is appealing since model-based methods are able to provide formal safety guarantees, while RL-based methods are able to exploit the robot agility by learning from the full-order system dynamics. However, current approaches to tackle this problem are mostly restricted to simple systems. In this paper, we propose a new method to combine model-based safety with model-free reinforcement learning by explicitly finding a low-dimensional model of the system controlled by a RL policy and applying stability and safety guarantees on that simple model. We use a complex bipedal robot Cassie, which is a high dimensional nonlinear system with hybrid dynamics and underactuation, and its RL-based walking controller as an example. We show that a low-dimensional dynamical model is sufficient to capture the dynamics of the closed-loop system. We demonstrate that this model is linear, asymptotically stable, and is decoupled across control input in all dimensions. We further exemplify that such linearity exists even when using different RL control policies. Such results point out an interesting direction to understand the relationship between RL and optimal control: whether RL tends to linearize the nonlinear system during training in some cases. Furthermore, we illustrate that the found linear model is able to provide guarantees by safety-critical optimal control framework, e.g., Model Predictive Control with Control Barrier Functions, on an example of autonomous navigation using Cassie while taking advantage of the agility provided by the RL-based controller.
Bayesian Optimization Meets Hybrid Zero Dynamics: Safe Parameter Learning for Bipedal Locomotion Control
Mar 04, 2022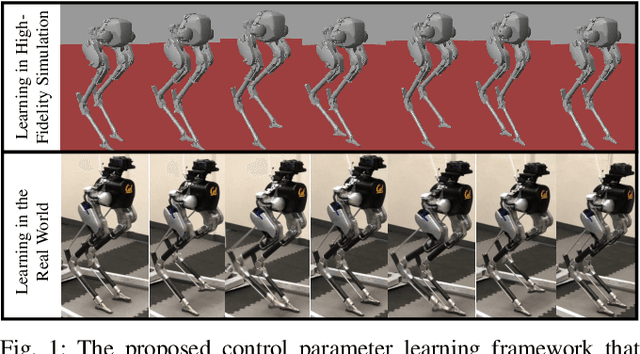
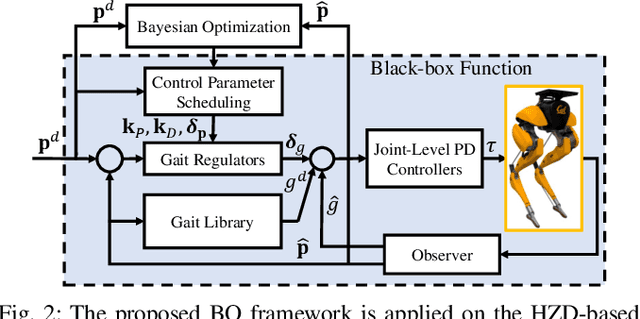
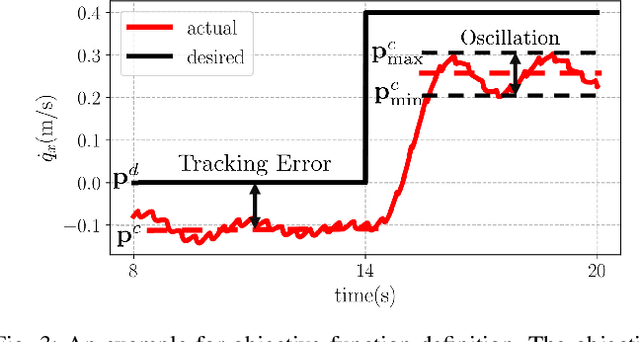
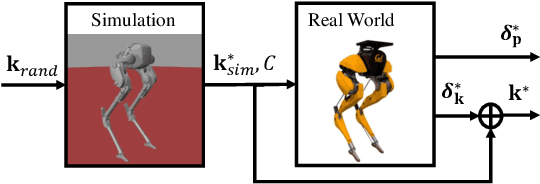
In this paper, we propose a multi-domain control parameter learning framework that combines Bayesian Optimization (BO) and Hybrid Zero Dynamics (HZD) for locomotion control of bipedal robots. We leverage BO to learn the control parameters used in the HZD-based controller. The learning process is firstly deployed in simulation to optimize different control parameters for a large repertoire of gaits. Next, to tackle the discrepancy between the simulation and the real world, the learning process is applied on the physical robot to learn for corrections to the control parameters learned in simulation while also respecting a safety constraint for gait stability. This method empowers an efficient sim-to-real transition with a small number of samples in the real world, and does not require a valid controller to initialize the training in simulation. Our proposed learning framework is experimentally deployed and validated on a bipedal robot Cassie to perform versatile locomotion skills with improved performance on smoothness of walking gaits and reduction of steady-state tracking errors.
Teaching Robots to Span the Space of Functional Expressive Motion
Mar 04, 2022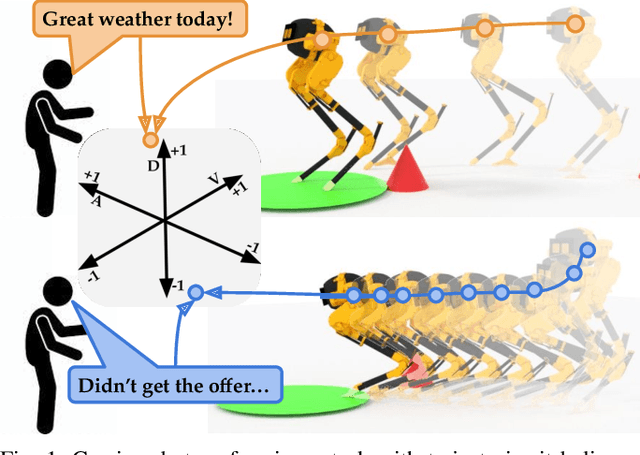
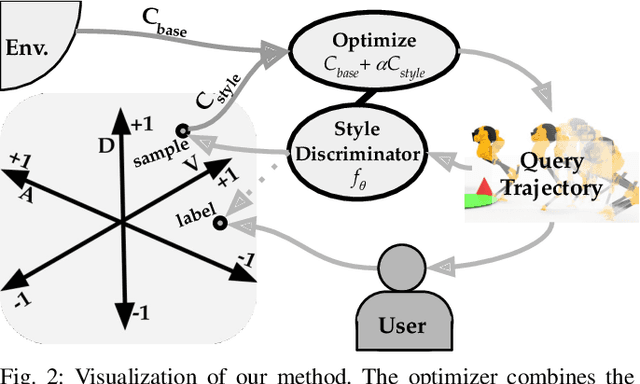
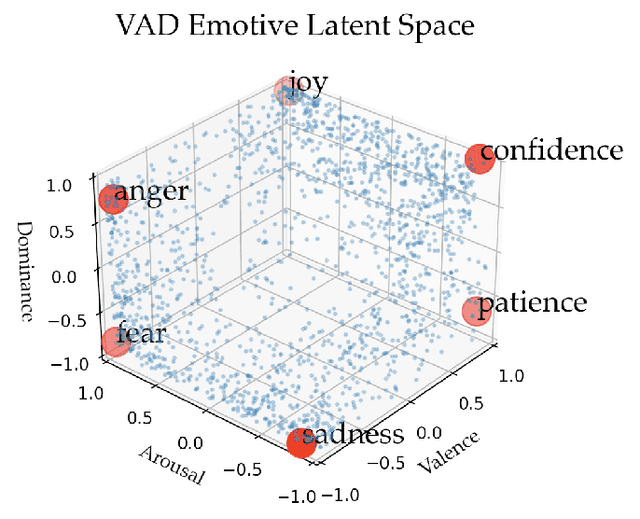

Our goal is to enable robots to perform functional tasks in emotive ways, be it in response to their users' emotional states, or expressive of their confidence levels. Prior work has proposed learning independent cost functions from user feedback for each target emotion, so that the robot may optimize it alongside task and environment specific objectives for any situation it encounters. However, this approach is inefficient when modeling multiple emotions and unable to generalize to new ones. In this work, we leverage the fact that emotions are not independent of each other: they are related through a latent space of Valence-Arousal-Dominance (VAD). Our key idea is to learn a model for how trajectories map onto VAD with user labels. Considering the distance between a trajectory's mapping and a target VAD allows this single model to represent cost functions for all emotions. As a result 1) all user feedback can contribute to learning about every emotion; 2) the robot can generate trajectories for any emotion in the space instead of only a few predefined ones; and 3) the robot can respond emotively to user-generated natural language by mapping it to a target VAD. We introduce a method that interactively learns to map trajectories to this latent space and test it in simulation and in a user study. In experiments, we use a simple vacuum robot as well as the Cassie biped.
Automated Catheter Tip Repositioning for Intra-cardiac Echocardiography
Jan 21, 2022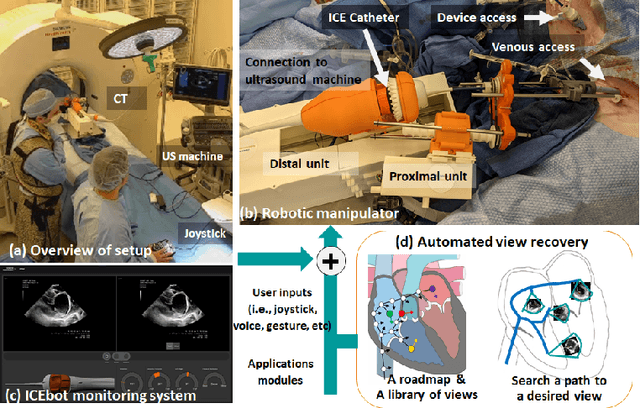


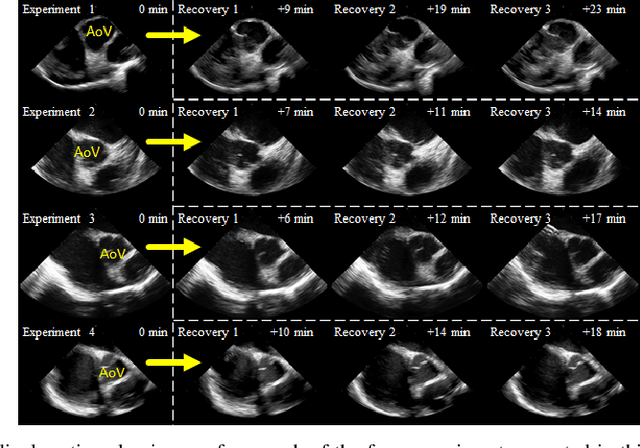
Purpose: Intra-Cardiac Echocardiography (ICE) is a powerful imaging modality for guiding cardiac electrophysiology and structural heart interventions. ICE provides real-time observation of anatomy and devices, while enabling direct monitoring of potential complications. In single operator settings, the physician needs to switch back-and-forth between the ICE catheter and therapy device, making continuous ICE support impossible. Two operators setup are therefore sometimes implemented, with the challenge of increase room occupation and cost. Two operator setups are sometimes implemented, but increase procedural costs and room occupation. Methods: ICE catheter robotic control system is developed with automated catheter tip repositioning (i.e. view recovery) method, which can reproduce important views previously navigated to and saved by the user. The performance of the proposed method is demonstrated and evaluated in a combination of heart phantom and animal experiments. Results: Automated ICE view recovery achieved catheter tip position accuracy of 2.09 +/-0.90 mm and catheter image orientation accuracy of 3.93 +/- 2.07 degree in animal studies, and 0.67 +/- 0.79 mm and 0.37 +/- 0.19 degree in heart phantom studies, respectively. Our proposed method is also successfully used during transeptal puncture in animals without complications, showing the possibility for fluoro-less transeptal puncture with ICE catheter robot. Conclusion: Robotic ICE imaging has the potential to provide precise and reproducible anatomical views, which can reduce overall execution time, labor burden of procedures, and x-ray usage for a range of cardiac procedures. Keywords: Automated View Recovery, Path Planning, Intra-cardiac echocardiography (ICE), Catheter, Tendon-driven manipulator, Cardiac Imaging
Vision-Aided Autonomous Navigation of Bipedal Robots in Height-Constrained Environments
Sep 13, 2021
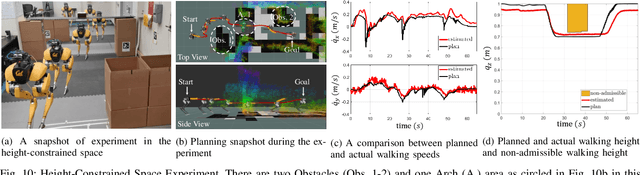
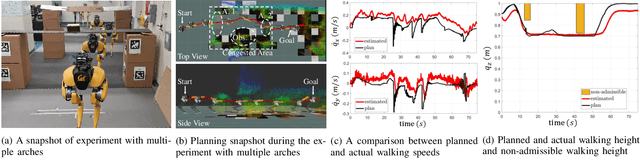
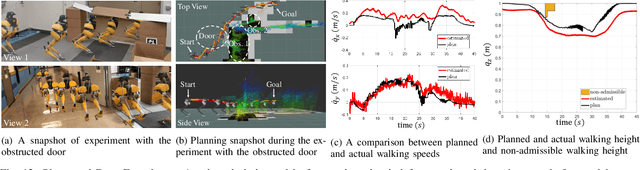
Navigating a large-scaled robot in unknown and cluttered height-constrained environments is challenging. Not only is a fast and reliable planning algorithm required to go around obstacles, the robot should also be able to change its intrinsic dimension by crouching in order to travel underneath height constrained regions. There are few mobile robots that are capable of handling such a challenge, and bipedal robots provide a solution. However, as bipedal robots have nonlinear and hybrid dynamics, trajectory planning while ensuring dynamic feasibility and safety on these robots is challenging. This paper presents an end-to-end vision-aided autonomous navigation framework which leverages three layers of planners and a variable walking height controller to enable bipedal robots to safely explore height-constrained environments. A vertically actuated Spring-Loaded Inverted Pendulum (vSLIP) model is introduced to capture the robot coupled dynamics of planar walking and vertical walking height. This reduced-order model is utilized to optimize for long-term and short-term safe trajectory plans. A variable walking height controller is leveraged to enable the bipedal robot to maintain stable periodic walking gaits while following the planned trajectory. The entire framework is tested and experimentally validated using a bipedal robot Cassie. This demonstrates reliable autonomy to drive the robot to safely avoid obstacles while walking to the goal location in various kinds of height-constrained cluttered environments.
Autonomous Navigation for Quadrupedal Robots with Optimized Jumping through Constrained Obstacles
Jul 01, 2021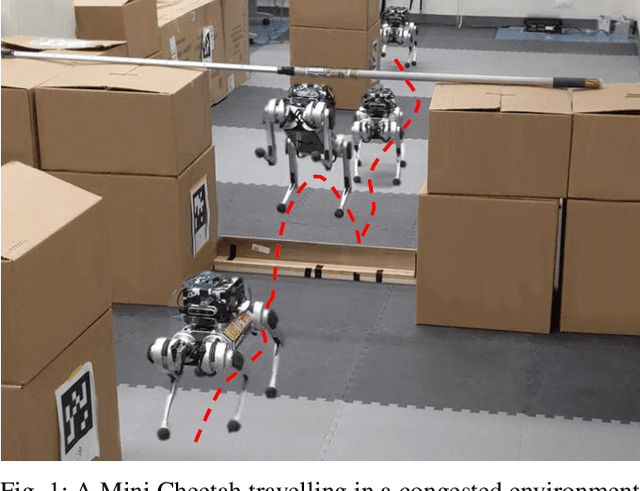

Quadrupeds are strong candidates for navigating challenging environments because of their agile and dynamic designs. This paper presents a methodology that extends the range of exploration for quadrupedal robots by creating an end-to-end navigation framework that exploits walking and jumping modes. To obtain a dynamic jumping maneuver while avoiding obstacles, dynamically-feasible trajectories are optimized offline through collocation-based optimization where safety constraints are imposed. Such optimization schematic allows the robot to jump through window-shaped obstacles by considering both obstacles in the air and on the ground. The resulted jumping mode is utilized in an autonomous navigation pipeline that leverages a search-based global planner and a local planner to enable the robot to reach the goal location by walking. A state machine together with a decision making strategy allows the system to switch behaviors between walking around obstacles or jumping through them. The proposed framework is experimentally deployed and validated on a quadrupedal robot, a Mini Cheetah, to enable the robot to autonomously navigate through an environment while avoiding obstacles and jumping over a maximum height of 13 cm to pass through a window-shaped opening in order to reach its goal.
CRT-Net: A Generalized and Scalable Framework for the Computer-Aided Diagnosis of Electrocardiogram Signals
May 28, 2021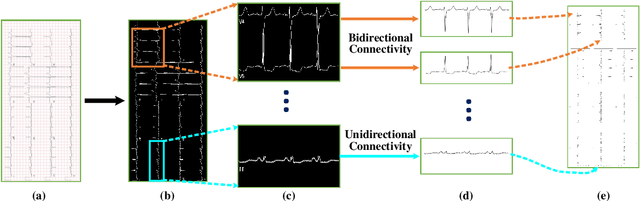
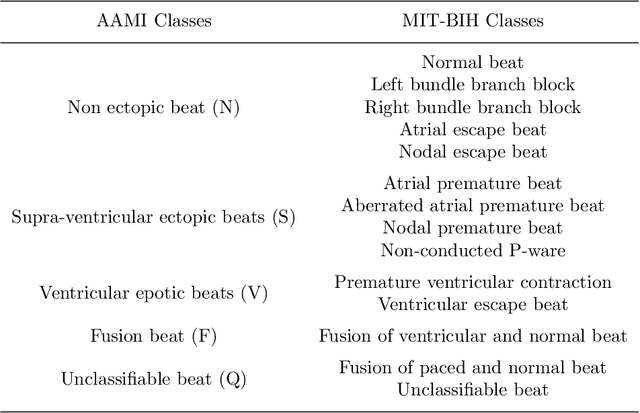
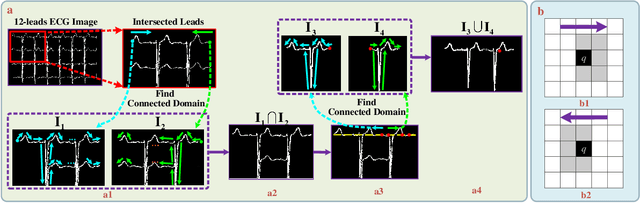
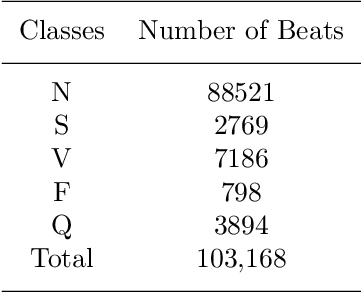
Electrocardiogram (ECG) signals play critical roles in the clinical screening and diagnosis of many types of cardiovascular diseases. Despite deep neural networks that have been greatly facilitated computer-aided diagnosis (CAD) in many clinical tasks, the variability and complexity of ECG in the clinic still pose significant challenges in both diagnostic performance and clinical applications. In this paper, we develop a robust and scalable framework for the clinical recognition of ECG. Considering the fact that hospitals generally record ECG signals in the form of graphic waves of 2-D images, we first extract the graphic waves of 12-lead images into numerical 1-D ECG signals by a proposed bi-directional connectivity method. Subsequently, a novel deep neural network, namely CRT-Net, is designed for the fine-grained and comprehensive representation and recognition of 1-D ECG signals. The CRT-Net can well explore waveform features, morphological characteristics and time domain features of ECG by embedding convolution neural network(CNN), recurrent neural network(RNN), and transformer module in a scalable deep model, which is especially suitable in clinical scenarios with different lengths of ECG signals captured from different devices. The proposed framework is first evaluated on two widely investigated public repositories, demonstrating the superior performance of ECG recognition in comparison with state-of-the-art. Moreover, we validate the effectiveness of our proposed bi-directional connectivity and CRT-Net on clinical ECG images collected from the local hospital, including 258 patients with chronic kidney disease (CKD), 351 patients with Type-2 Diabetes (T2DM), and around 300 patients in the control group. In the experiments, our methods can achieve excellent performance in the recognition of these two types of disease.
Enhancing Feasibility and Safety of Nonlinear Model Predictive Control with Discrete-Time Control Barrier Functions
May 21, 2021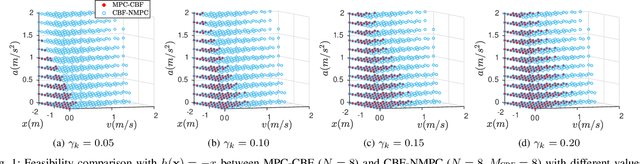
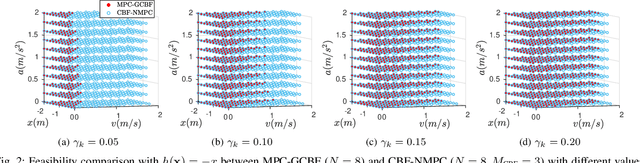
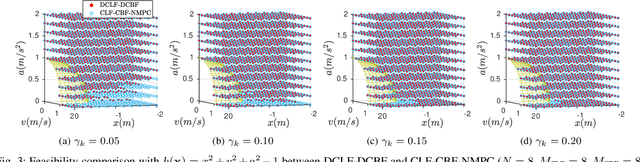
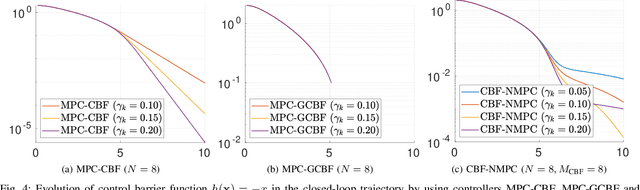
Safety is one of the fundamental problems in robotics. Recently, one-step or multi-step optimal control problems for discrete-time nonlinear dynamical system are formulated to offer tracking stability using control Lyapunov functions (CLFs) while subject to input constraints as well as safety-critical constraints using control barrier functions (CBFs). The limitations of these existing approaches are mainly about feasibility and safety. In the existing approaches, the optimization feasibility and the system safety cannot be enhanced at the same time theoretically. In this paper, we propose two formulations that unifies CLFs and CBFs under the framework of nonlinear model predictive control (NMPC). In the proposed formulations, safety criteria is commonly formulated as CBF constraints and stability performance is ensured with either a terminal cost function or CLF constraints. Relaxing variables are introduced on the CBF constraints to resolve the tradeoff between feasibility and safety so that they can be enhanced at the same. The advantages about feasibility and safety of proposed formulations compared with existing methods are analyzed theoretically and validated with numerical results.
Robotic Guide Dog: Leading a Human with Leash-Guided Hybrid Physical Interaction
Mar 26, 2021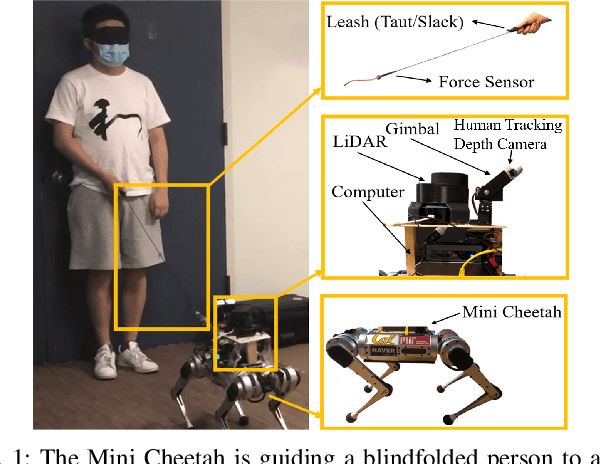
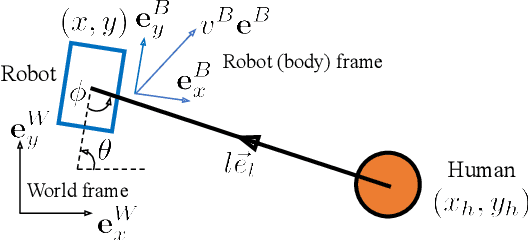
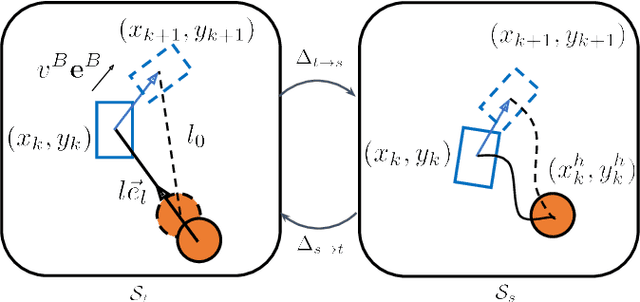
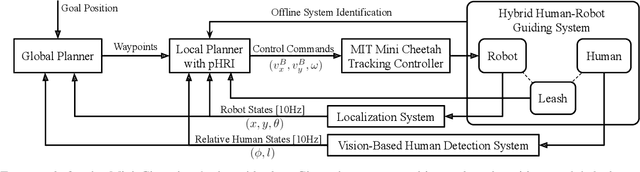
An autonomous robot that is able to physically guide humans through narrow and cluttered spaces could be a big boon to the visually-impaired. Most prior robotic guiding systems are based on wheeled platforms with large bases with actuated rigid guiding canes. The large bases and the actuated arms limit these prior approaches from operating in narrow and cluttered environments. We propose a method that introduces a quadrupedal robot with a leash to enable the robot-guiding human system to change its intrinsic dimension (by letting the leash go slack) in order to fit into narrow spaces. We propose a hybrid physical Human-Robot Interaction model that involves leash tension to describe the dynamical relationship in the robot-guiding human system. This hybrid model is utilized in a mixed-integer programming problem to develop a reactive planner that is able to utilize slack-taut switching to guide a blind-folded person to safely travel in a confined space. The proposed leash-guided robot framework is deployed on a Mini Cheetah quadrupedal robot and validated in experiments.
Reinforcement Learning for Robust Parameterized Locomotion Control of Bipedal Robots
Mar 26, 2021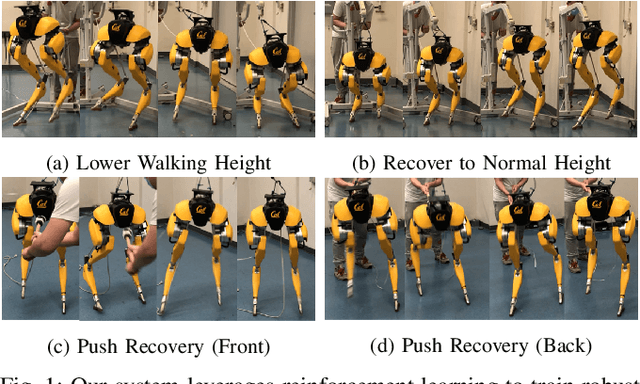
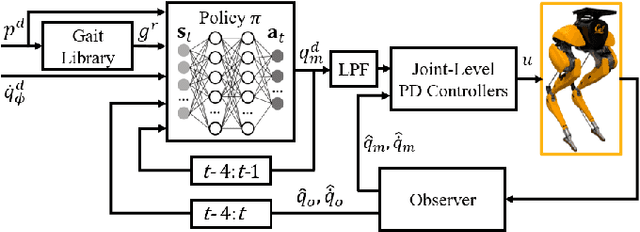
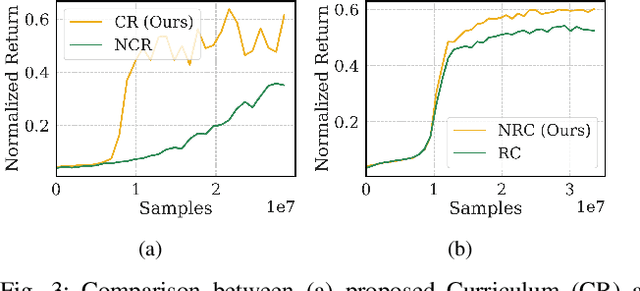
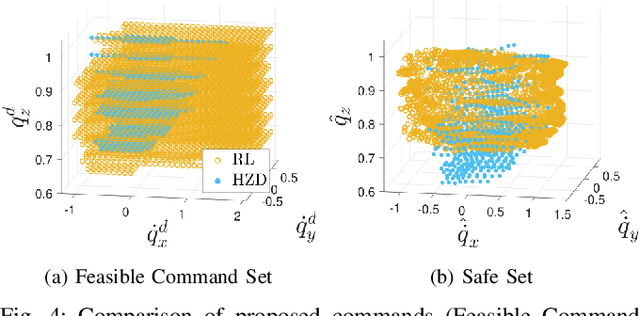
Developing robust walking controllers for bipedal robots is a challenging endeavor. Traditional model-based locomotion controllers require simplifying assumptions and careful modelling; any small errors can result in unstable control. To address these challenges for bipedal locomotion, we present a model-free reinforcement learning framework for training robust locomotion policies in simulation, which can then be transferred to a real bipedal Cassie robot. To facilitate sim-to-real transfer, domain randomization is used to encourage the policies to learn behaviors that are robust across variations in system dynamics. The learned policies enable Cassie to perform a set of diverse and dynamic behaviors, while also being more robust than traditional controllers and prior learning-based methods that use residual control. We demonstrate this on versatile walking behaviors such as tracking a target walking velocity, walking height, and turning yaw.