 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuVER: Improving First-Stage Entity Retrieval with Multi-View Entity Representations
Sep 13, 2021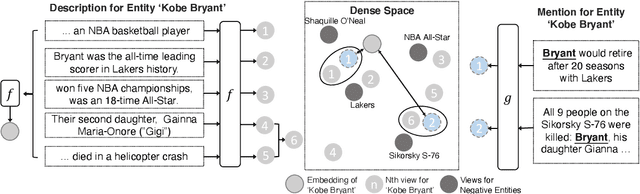
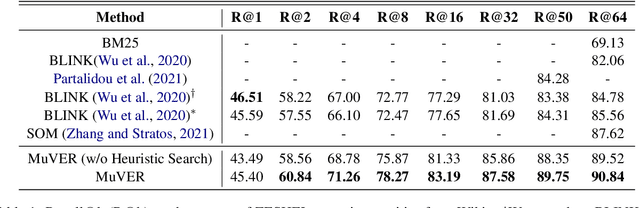

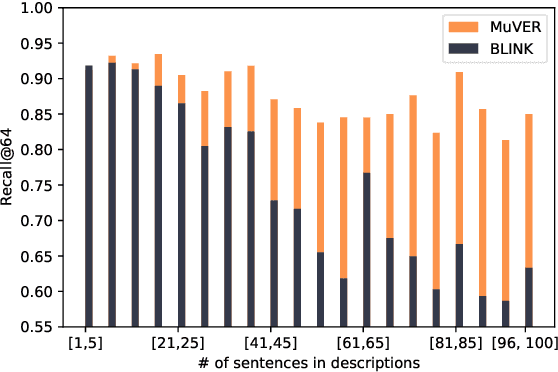
Entity retrieval, which aims at disambiguating mentions to canonical entities from massive KBs, is essential for many tasks in natural language processing. Recent progress in entity retrieval shows that the dual-encoder structure is a powerful and efficient framework to nominate candidates if entities are only identified by descriptions. However, they ignore the property that meanings of entity mentions diverge in different contexts and are related to various portions of descriptions, which are treated equally in previous works. In this work, we propose Multi-View Entity Representations (MuVER), a novel approach for entity retrieval that constructs multi-view representations for entity descriptions and approximates the optimal view for mentions via a heuristic searching method. Our method achieves the state-of-the-art performance on ZESHEL and improves the quality of candidates on three standard Entity Linking datasets
Improving Named Entity Recognition by External Context Retrieving and Cooperative Learning
Jun 02, 2021
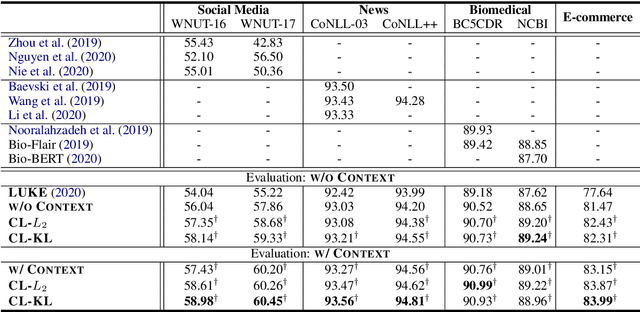
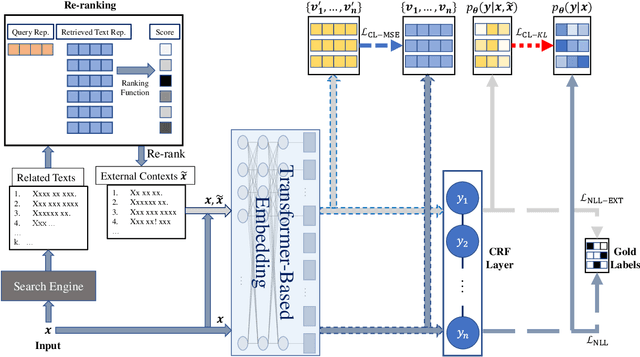
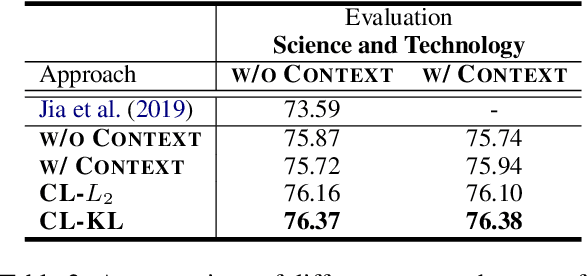
Recent advances in Named Entity Recognition (NER) show that document-level contexts can significantly improve model performance. In many application scenarios, however, such contexts are not available. In this paper, we propose to find external contexts of a sentence by retrieving and selecting a set of semantically relevant texts through a search engine, with the original sentence as the query. We find empirically that the contextual representations computed on the retrieval-based input view, constructed through the concatenation of a sentence and its external contexts, can achieve significantly improved performance compared to the original input view based only on the sentence. Furthermore, we can improve the model performance of both input views by Cooperative Learning, a training method that encourages the two input views to produce similar contextual representations or output label distributions. Experiments show that our approach can achieve new state-of-the-art performance on 8 NER data sets across 5 domains.
An Investigation of Potential Function Designs for Neural CRF
Nov 11, 2020
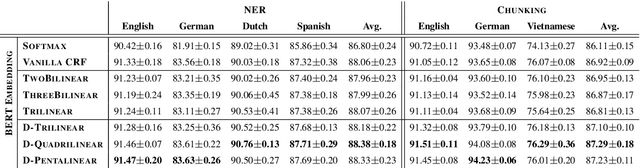
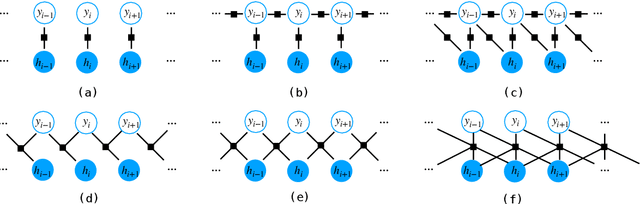
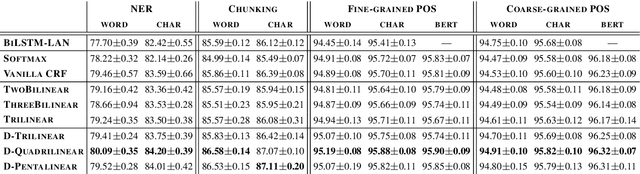
The neural linear-chain CRF model is one of the most widely-used approach to sequence labeling. In this paper, we investigate a series of increasingly expressive potential functions for neural CRF models, which not only integrate the emission and transition functions, but also explicitly take the representations of the contextual words as input. Our extensive experiments show that the decomposed quadrilinear potential function based on the vector representations of two neighboring labels and two neighboring words consistently achieves the best performance.
AIN: Fast and Accurate Sequence Labeling with Approximate Inference Network
Oct 12, 2020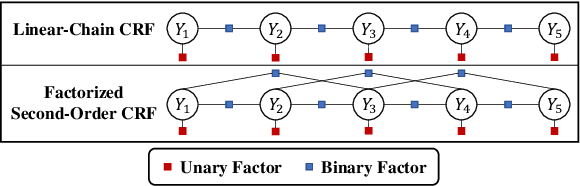
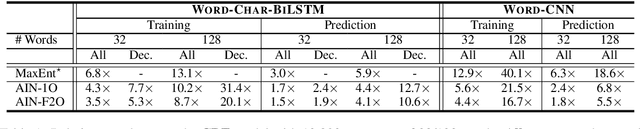
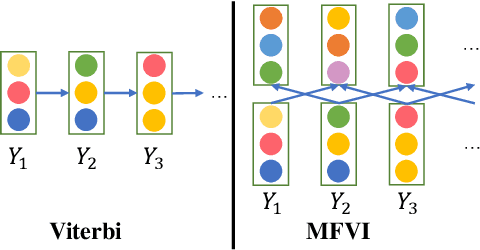

The linear-chain Conditional Random Field (CRF) model is one of the most widely-used neural sequence labeling approaches. Exact probabilistic inference algorithms such as the forward-backward and Viterbi algorithms are typically applied in training and prediction stages of the CRF model. However, these algorithms require sequential computation that makes parallelization impossible. In this paper, we propose to employ a parallelizable approximate variational inference algorithm for the CRF model. Based on this algorithm, we design an approximate inference network that can be connected with the encoder of the neural CRF model to form an end-to-end network, which is amenable to parallelization for faster training and prediction. The empirical results show that our proposed approaches achieve a 12.7-fold improvement in decoding speed with long sentences and a competitive accuracy compared with the traditional CRF approach.
Structural Knowledge Distillation
Oct 10, 2020
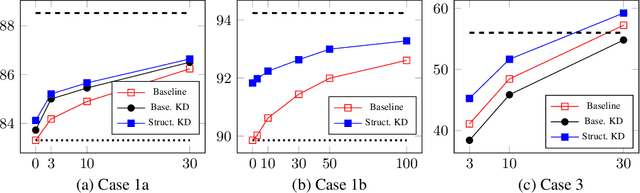
Knowledge distillation is a critical technique to transfer knowledge between models, typically from a large model (the teacher) to a smaller one (the student). The objective function of knowledge distillation is typically the cross-entropy between the teacher and the student's output distributions. However, for structured prediction problems, the output space is exponential in size; therefore, the cross-entropy objective becomes intractable to compute and optimize directly. In this paper, we derive a factorized form of the knowledge distillation objective for structured prediction, which is tractable for many typical choices of the teacher and student models. In particular, we show the tractability and empirical effectiveness of structural knowledge distillation between sequence labeling and dependency parsing models under four different scenarios: 1) the teacher and student share the same factorization form of the output structure scoring function; 2) the student factorization produces smaller substructures than the teacher factorization; 3) the teacher factorization produces smaller substructures than the student factorization; 4) the factorization forms from the teacher and the student are incompatible.
Automated Concatenation of Embeddings for Structured Prediction
Oct 10, 2020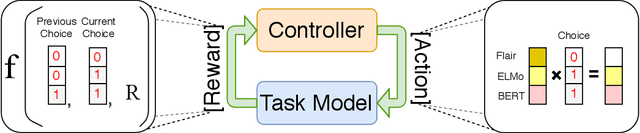
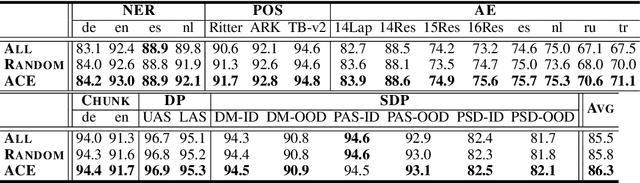
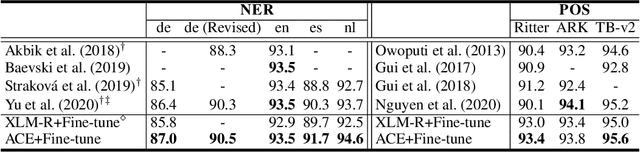
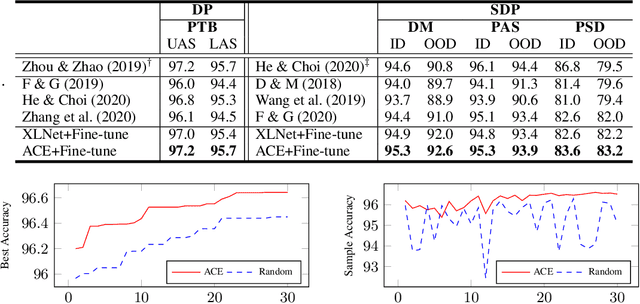
Pretrained contextualized embeddings are powerful word representations for structured prediction tasks. Recent work found that better word representations can be obtained by concatenating different types of embeddings. However, the selection of embeddings to form the best concatenated representation usually varies depending on the task and the collection of candidate embeddings, and the ever-increasing number of embedding types makes it a more difficult problem. In this paper, we propose Automated Concatenation of Embeddings (ACE) to automate the process of finding better concatenations of embeddings for structured prediction tasks, based on a formulation inspired by recent progress on neural architecture search. Specifically, a controller alternately samples a concatenation of embeddings, according to its current belief of the effectiveness of individual embedding types in consideration for a task, and updates the belief based on a reward. We follow strategies in reinforcement learning to optimize the parameters of the controller and compute the reward based on the accuracy of a task model, which is fed with the sampled concatenation as input and trained on a task dataset. Empirical results on 6 tasks and 23 datasets show that our approach outperforms strong baselines and achieves state-of-the-art performance with fine-tuned embeddings in the vast majority of evaluations.
More Embeddings, Better Sequence Labelers?
Oct 10, 2020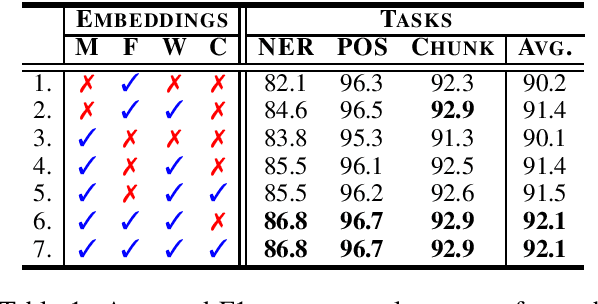
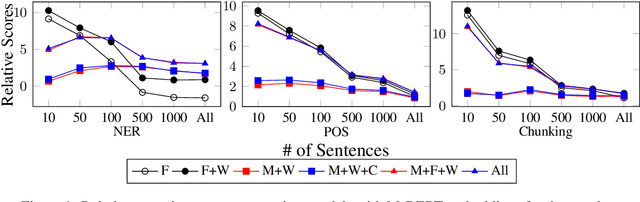

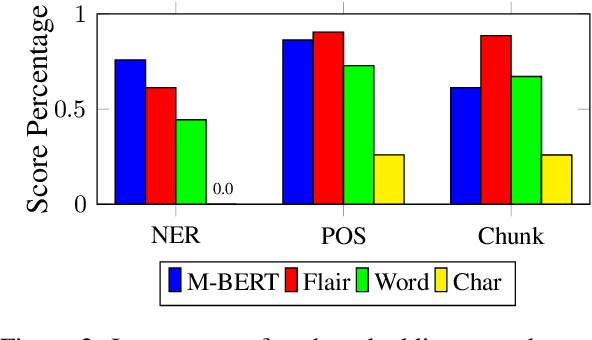
Recent work proposes a family of contextual embeddings that significantly improves the accuracy of sequence labelers over non-contextual embeddings. However, there is no definite conclusion on whether we can build better sequence labelers by combining different kinds of embeddings in various settings. In this paper, we conduct extensive experiments on 3 tasks over 18 datasets and 8 languages to study the accuracy of sequence labeling with various embedding concatenations and make three observations: (1) concatenating more embedding variants leads to better accuracy in rich-resource and cross-domain settings and some conditions of low-resource settings; (2) concatenating additional contextual sub-word embeddings with contextual character embeddings hurts the accuracy in extremely low-resource settings; (3) based on the conclusion of (1), concatenating additional similar contextual embeddings cannot lead to further improvements. We hope these conclusions can help people build stronger sequence labelers in various settings.
Automatic Speech Recognition and Topic Identification for Almost-Zero-Resource Languages
Jun 18, 2018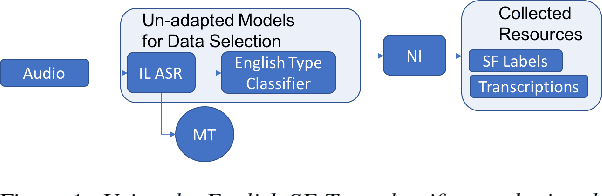
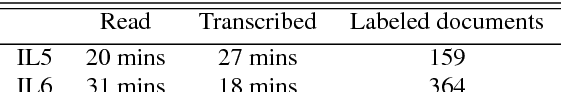
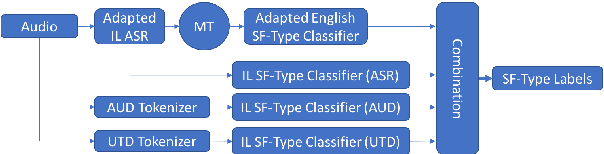
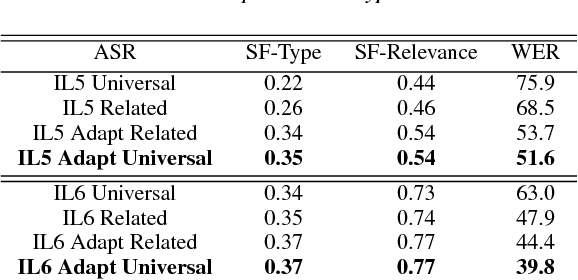
Automatic speech recognition (ASR) systems often need to be developed for extremely low-resource languages to serve end-uses such as audio content categorization and search. While universal phone recognition is natural to consider when no transcribed speech is available to train an ASR system in a language, adapting universal phone models using very small amounts (minutes rather than hours) of transcribed speech also needs to be studied, particularly with state-of-the-art DNN-based acoustic models. The DARPA LORELEI program provides a framework for such very-low-resource ASR studies, and provides an extrinsic metric for evaluating ASR performance in a humanitarian assistance, disaster relief setting. This paper presents our Kaldi-based systems for the program, which employ a universal phone modeling approach to ASR, and describes recipes for very rapid adaptation of this universal ASR system. The results we obtain significantly outperform results obtained by many competing approaches on the NIST LoReHLT 2017 Evaluation datasets.
Transfer Learning based Dynamic Multiobjective Optimization Algorithms
Nov 18, 2017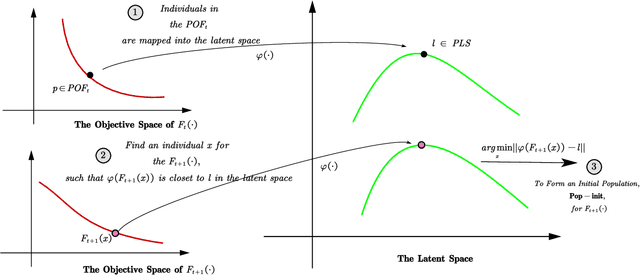
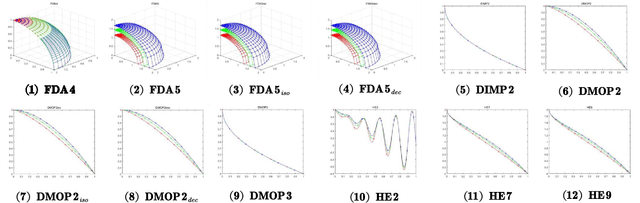
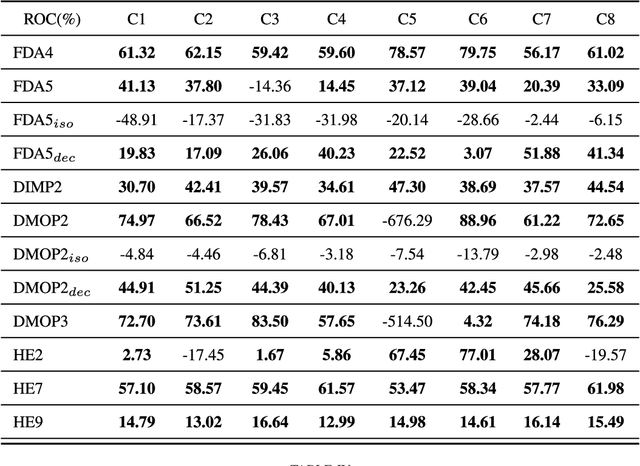
One of the major distinguishing features of the dynamic multiobjective optimization problems (DMOPs) is the optimization objectives will change over time, thus tracking the varying Pareto-optimal front becomes a challenge. One of the promising solutions is reusing the "experiences" to construct a prediction model via statistical machine learning approaches. However most of the existing methods ignore the non-independent and identically distributed nature of data used to construct the prediction model. In this paper, we propose an algorithmic framework, called Tr-DMOEA, which integrates transfer learning and population-based evolutionary algorithm for solving the DMOPs. This approach takes the transfer learning method as a tool to help reuse the past experience for speeding up the evolutionary process, and at the same time, any population based multiobjective algorithms can benefit from this integration without any extensive modifications. To verify this, we incorporate the proposed approach into the development of three well-known algorithms, nondominated sorting genetic algorithm II (NSGA-II), multiobjective particle swarm optimization (MOPSO), and the regularity model-based multiobjective estimation of distribution algorithm (RM-MEDA), and then employ twelve benchmark functions to test these algorithms as well as compare with some chosen state-of-the-art designs. The experimental results confirm the effectiveness of the proposed method through exploiting machine learning technology.
Statistical Machine Translation Features with Multitask Tensor Networks
Jun 01, 2015
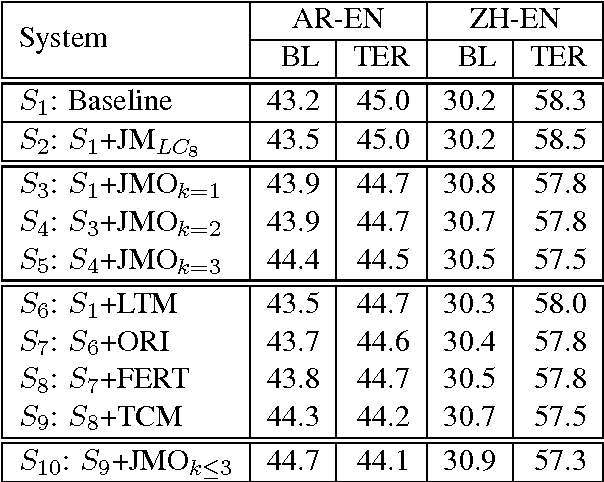
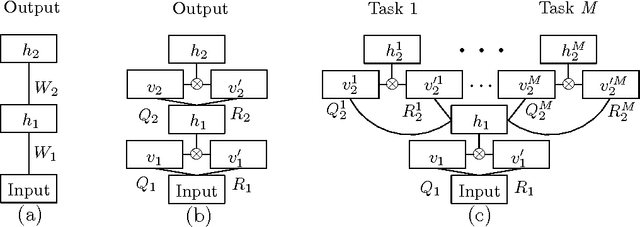
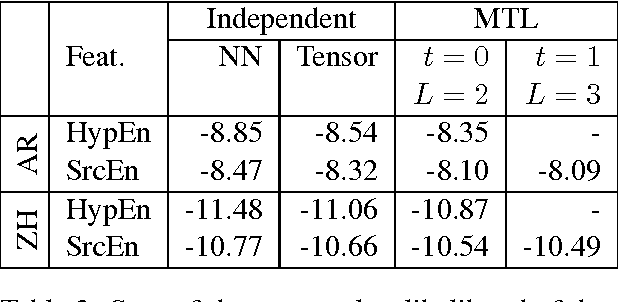
We present a three-pronged approach to improving Statistical Machine Translation (SMT), building on recent success in the application of neural networks to SMT. First, we propose new features based on neural networks to model various non-local translation phenomena. Second, we augment the architecture of the neural network with tensor layers that capture important higher-order interaction among the network units. Third, we apply multitask learning to estimate the neural network parameters jointly. Each of our proposed methods results in significant improvements that are complementary. The overall improvement is +2.7 and +1.8 BLEU points for Arabic-English and Chinese-English translation over a state-of-the-art system that already includes neural network features.