 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePotential and Limitations of LLMs in Capturing Structured Semantics: A Case Study on SRL
May 10, 2024

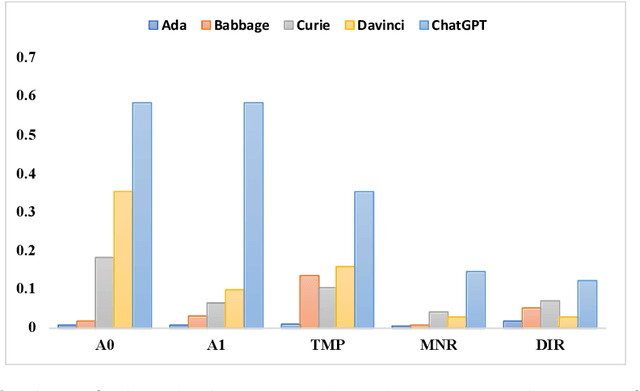

Large Language Models (LLMs) play a crucial role in capturing structured semantics to enhance language understanding, improve interpretability, and reduce bias. Nevertheless, an ongoing controversy exists over the extent to which LLMs can grasp structured semantics. To assess this, we propose using Semantic Role Labeling (SRL) as a fundamental task to explore LLMs' ability to extract structured semantics. In our assessment, we employ the prompting approach, which leads to the creation of our few-shot SRL parser, called PromptSRL. PromptSRL enables LLMs to map natural languages to explicit semantic structures, which provides an interpretable window into the properties of LLMs. We find interesting potential: LLMs can indeed capture semantic structures, and scaling-up doesn't always mirror potential. Additionally, limitations of LLMs are observed in C-arguments, etc. Lastly, we are surprised to discover that significant overlap in the errors is made by both LLMs and untrained humans, accounting for almost 30% of all errors.
Joint Entity and Relation Extraction with Span Pruning and Hypergraph Neural Networks
Oct 26, 2023



Entity and Relation Extraction (ERE) is an important task in information extraction. Recent marker-based pipeline models achieve state-of-the-art performance, but still suffer from the error propagation issue. Also, most of current ERE models do not take into account higher-order interactions between multiple entities and relations, while higher-order modeling could be beneficial.In this work, we propose HyperGraph neural network for ERE ($\hgnn{}$), which is built upon the PL-marker (a state-of-the-art marker-based pipleline model). To alleviate error propagation,we use a high-recall pruner mechanism to transfer the burden of entity identification and labeling from the NER module to the joint module of our model. For higher-order modeling, we build a hypergraph, where nodes are entities (provided by the span pruner) and relations thereof, and hyperedges encode interactions between two different relations or between a relation and its associated subject and object entities. We then run a hypergraph neural network for higher-order inference by applying message passing over the built hypergraph. Experiments on three widely used benchmarks (\acef{}, \ace{} and \scierc{}) for ERE task show significant improvements over the previous state-of-the-art PL-marker.
Joint Information Extraction with Cross-Task and Cross-Instance High-Order Modeling
Dec 17, 2022



Prior works on Information Extraction (IE) typically predict different tasks and instances (e.g., event triggers, entities, roles, relations) independently, while neglecting their interactions and leading to model inefficiency. In this work, we introduce a joint IE framework, HighIE, that learns and predicts multiple IE tasks by integrating high-order cross-task and cross-instance dependencies. Specifically, we design two categories of high-order factors: homogeneous factors and heterogeneous factors. Then, these factors are utilized to jointly predict labels of all instances. To address the intractability problem of exact high-order inference, we incorporate a high-order neural decoder that is unfolded from a mean-field variational inference method. The experimental results show that our approach achieves consistent improvements on three IE tasks compared with our baseline and prior work.
Structural Knowledge Distillation
Oct 10, 2020
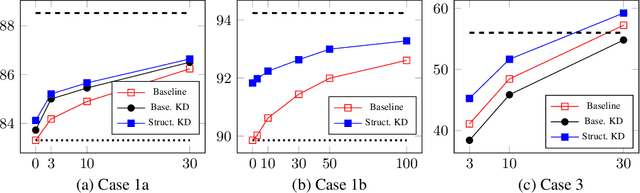
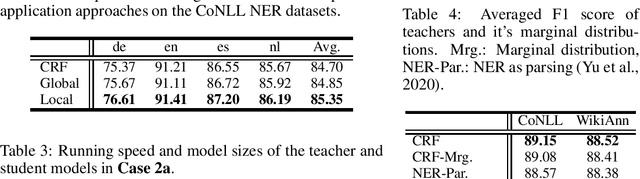
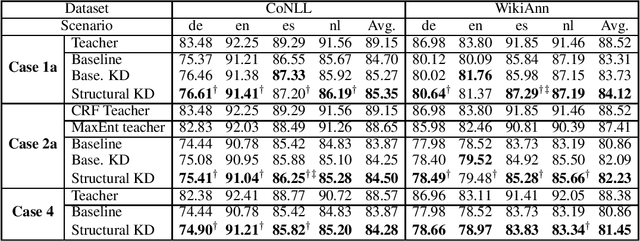
Knowledge distillation is a critical technique to transfer knowledge between models, typically from a large model (the teacher) to a smaller one (the student). The objective function of knowledge distillation is typically the cross-entropy between the teacher and the student's output distributions. However, for structured prediction problems, the output space is exponential in size; therefore, the cross-entropy objective becomes intractable to compute and optimize directly. In this paper, we derive a factorized form of the knowledge distillation objective for structured prediction, which is tractable for many typical choices of the teacher and student models. In particular, we show the tractability and empirical effectiveness of structural knowledge distillation between sequence labeling and dependency parsing models under four different scenarios: 1) the teacher and student share the same factorization form of the output structure scoring function; 2) the student factorization produces smaller substructures than the teacher factorization; 3) the teacher factorization produces smaller substructures than the student factorization; 4) the factorization forms from the teacher and the student are incompatible.
Controllable Length Control Neural Encoder-Decoder via Reinforcement Learning
Sep 17, 2019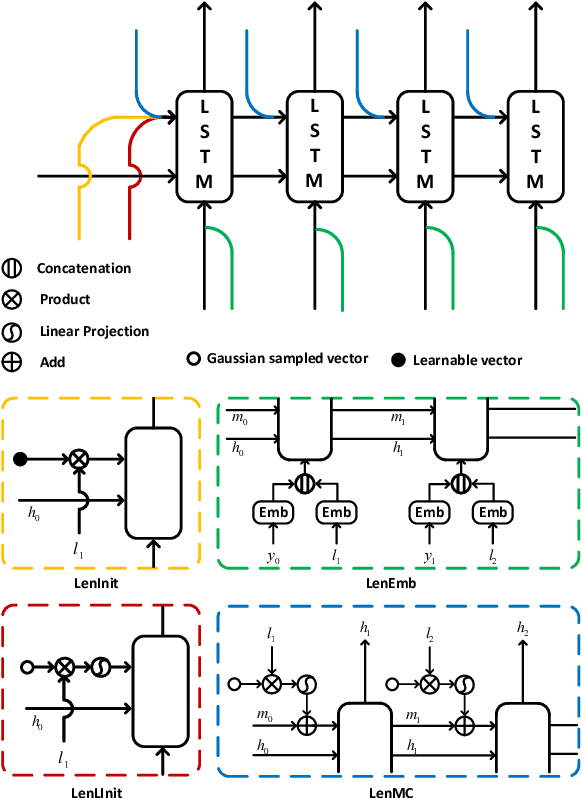

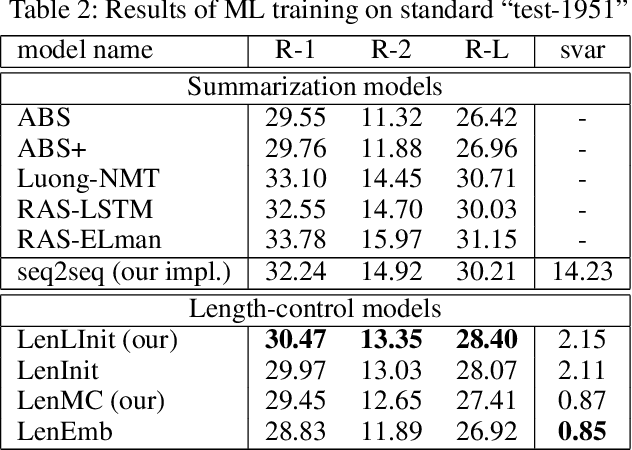
Controlling output length in neural language generation is valuable in many scenarios, especially for the tasks that have length constraints. A model with stronger length control capacity can produce sentences with more specific length, however, it usually sacrifices semantic accuracy of the generated sentences. Here, we denote a concept of Controllable Length Control (CLC) for the trade-off between length control capacity and semantic accuracy of the language generation model. More specifically, CLC is to alter length control capacity of the model so as to generate sentence with corresponding quality. This is meaningful in real applications when length control capacity and outputs quality are requested with different priorities, or to overcome unstability of length control during model training. In this paper, we propose two reinforcement learning (RL) methods to adjust the trade-off between length control capacity and semantic accuracy of length control models. Results show that our RL methods improve scores across a wide range of target lengths and achieve the goal of CLC. Additionally, two models LenMC and LenLInit modified on previous length-control models are proposed to obtain better performance in summarization task while still maintain the ability to control length.