 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Reweight Imaginary Transitions for Model-Based Reinforcement Learning
Apr 09, 2021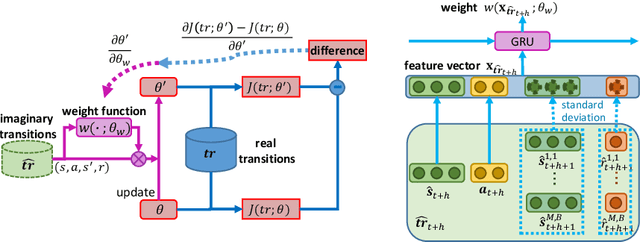
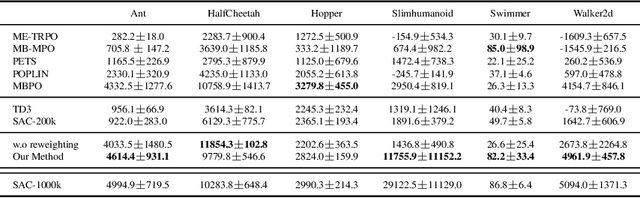
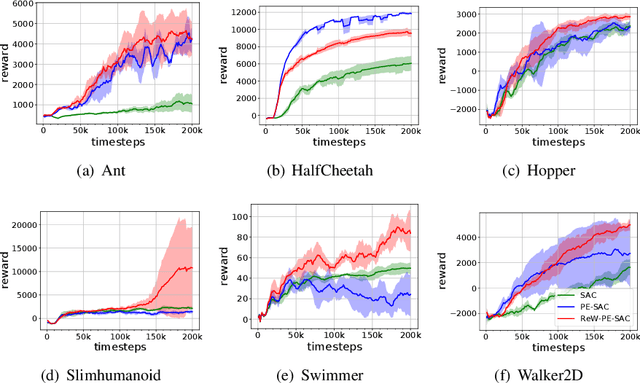
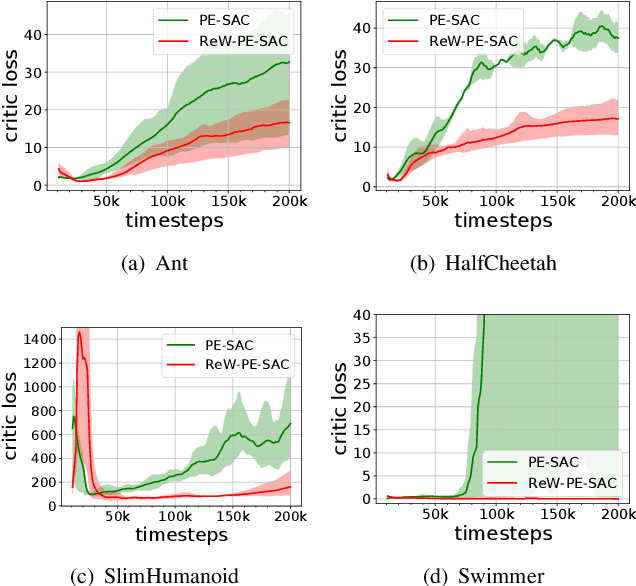
Model-based reinforcement learning (RL) is more sample efficient than model-free RL by using imaginary trajectories generated by the learned dynamics model. When the model is inaccurate or biased, imaginary trajectories may be deleterious for training the action-value and policy functions. To alleviate such problem, this paper proposes to adaptively reweight the imaginary transitions, so as to reduce the negative effects of poorly generated trajectories. More specifically, we evaluate the effect of an imaginary transition by calculating the change of the loss computed on the real samples when we use the transition to train the action-value and policy functions. Based on this evaluation criterion, we construct the idea of reweighting each imaginary transition by a well-designed meta-gradient algorithm. Extensive experimental results demonstrate that our method outperforms state-of-the-art model-based and model-free RL algorithms on multiple tasks. Visualization of our changing weights further validates the necessity of utilizing reweight scheme.
Planning with Exploration: Addressing Dynamics Bottleneck in Model-based Reinforcement Learning
Oct 24, 2020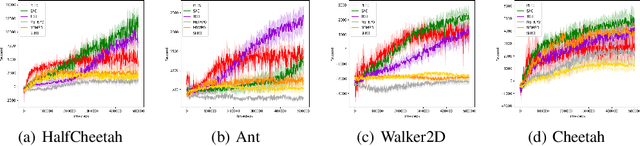

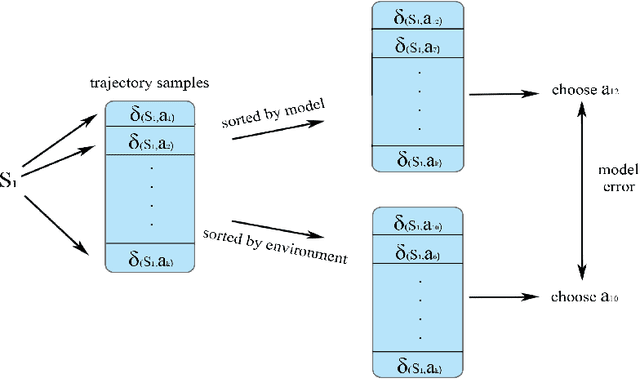
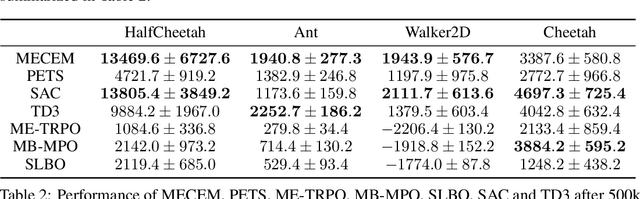
Model-based reinforcement learning is a framework in which an agent learns an environment model, makes planning and decision-making in this model, and finally interacts with the real environment. Model-based reinforcement learning has high sample efficiency compared with model-free reinforcement learning, and shows great potential in the real-world application. However, model-based reinforcement learning has been plagued by dynamics bottleneck. Dynamics bottleneck is the phenomenon that when the timestep to interact with the environment increases, the reward of the agent falls into the local optimum instead of increasing. In this paper, we analyze and explain how the coupling relationship between model and policy causes the dynamics bottleneck and shows improving the exploration ability of the agent can alleviate this issue. We then propose a new planning algorithm called Maximum Entropy Cross-Entropy Method (MECEM). MECEM can improve the agent's exploration ability by maximizing the distribution of action entropy in the planning process. We conduct experiments on fourteen well-recognized benchmark environments such as HalfCheetah, Ant and Swimmer. The results verify that our approach obtains the state-of-the-art performance on eleven benchmark environments and can effectively alleviate dynamics bottleneck on HalfCheetah, Ant and Walker2D.
Transfer Learning based Dynamic Multiobjective Optimization Algorithms
Nov 18, 2017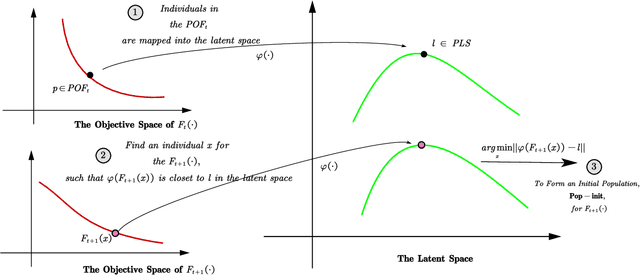
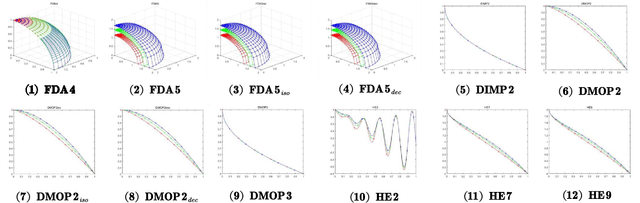
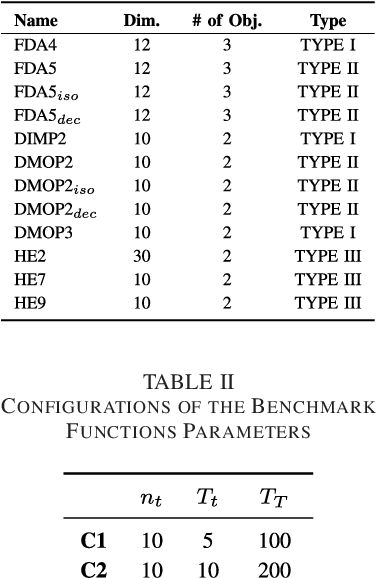
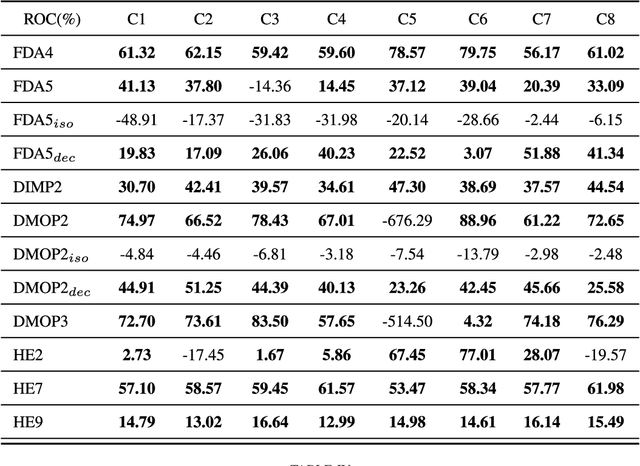
One of the major distinguishing features of the dynamic multiobjective optimization problems (DMOPs) is the optimization objectives will change over time, thus tracking the varying Pareto-optimal front becomes a challenge. One of the promising solutions is reusing the "experiences" to construct a prediction model via statistical machine learning approaches. However most of the existing methods ignore the non-independent and identically distributed nature of data used to construct the prediction model. In this paper, we propose an algorithmic framework, called Tr-DMOEA, which integrates transfer learning and population-based evolutionary algorithm for solving the DMOPs. This approach takes the transfer learning method as a tool to help reuse the past experience for speeding up the evolutionary process, and at the same time, any population based multiobjective algorithms can benefit from this integration without any extensive modifications. To verify this, we incorporate the proposed approach into the development of three well-known algorithms, nondominated sorting genetic algorithm II (NSGA-II), multiobjective particle swarm optimization (MOPSO), and the regularity model-based multiobjective estimation of distribution algorithm (RM-MEDA), and then employ twelve benchmark functions to test these algorithms as well as compare with some chosen state-of-the-art designs. The experimental results confirm the effectiveness of the proposed method through exploiting machine learning technology.