 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Adaptive Contextual Bandits for Resource Constraint based Recommendation
Apr 06, 2020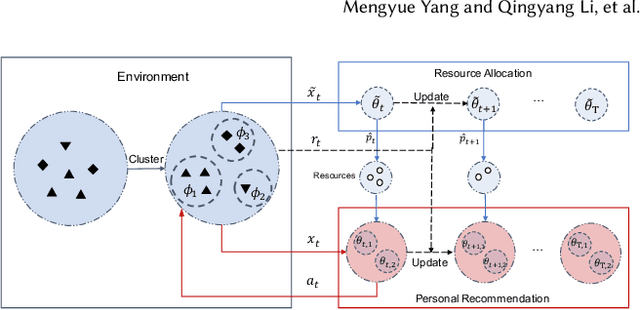
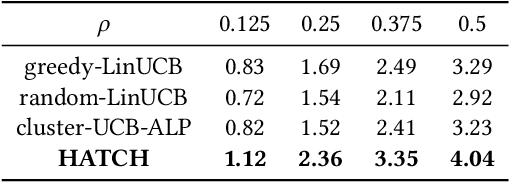
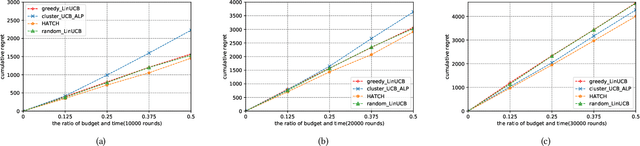

Contextual multi-armed bandit (MAB) achieves cutting-edge performance on a variety of problems. When it comes to real-world scenarios such as recommendation system and online advertising, however, it is essential to consider the resource consumption of exploration. In practice, there is typically non-zero cost associated with executing a recommendation (arm) in the environment, and hence, the policy should be learned with a fixed exploration cost constraint. It is challenging to learn a global optimal policy directly, since it is a NP-hard problem and significantly complicates the exploration and exploitation trade-off of bandit algorithms. Existing approaches focus on solving the problems by adopting the greedy policy which estimates the expected rewards and costs and uses a greedy selection based on each arm's expected reward/cost ratio using historical observation until the exploration resource is exhausted. However, existing methods are hard to extend to infinite time horizon, since the learning process will be terminated when there is no more resource. In this paper, we propose a hierarchical adaptive contextual bandit method (HATCH) to conduct the policy learning of contextual bandits with a budget constraint. HATCH adopts an adaptive method to allocate the exploration resource based on the remaining resource/time and the estimation of reward distribution among different user contexts. In addition, we utilize full of contextual feature information to find the best personalized recommendation. Finally, in order to prove the theoretical guarantee, we present a regret bound analysis and prove that HATCH achieves a regret bound as low as $O(\sqrt{T})$. The experimental results demonstrate the effectiveness and efficiency of the proposed method on both synthetic data sets and the real-world applications.
Deep Reinforcement Learning for Multi-Driver Vehicle Dispatching and Repositioning Problem
Nov 25, 2019
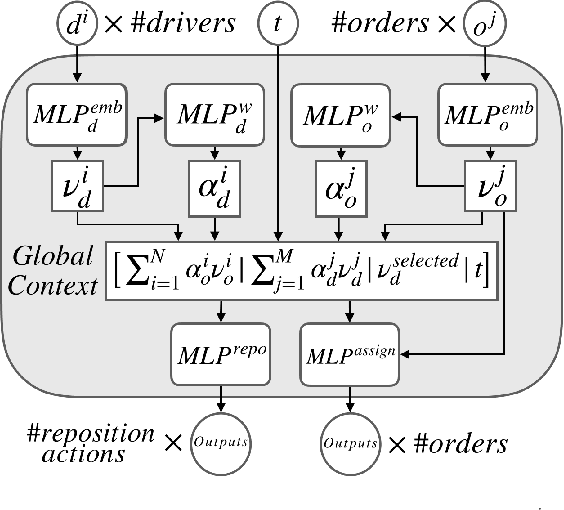
Order dispatching and driver repositioning (also known as fleet management) in the face of spatially and temporally varying supply and demand are central to a ride-sharing platform marketplace. Hand-crafting heuristic solutions that account for the dynamics in these resource allocation problems is difficult, and may be better handled by an end-to-end machine learning method. Previous works have explored machine learning methods to the problem from a high-level perspective, where the learning method is responsible for either repositioning the drivers or dispatching orders, and as a further simplification, the drivers are considered independent agents maximizing their own reward functions. In this paper we present a deep reinforcement learning approach for tackling the full fleet management and dispatching problems. In addition to treating the drivers as individual agents, we consider the problem from a system-centric perspective, where a central fleet management agent is responsible for decision-making for all drivers.
Multi-Agent Reinforcement Learning for Order-dispatching via Order-Vehicle Distribution Matching
Oct 07, 2019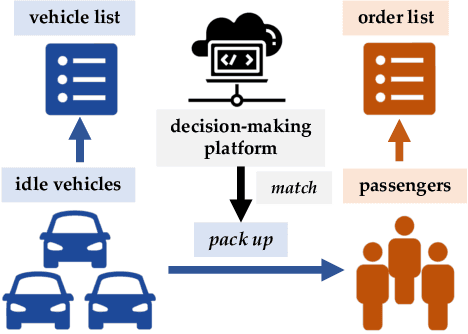

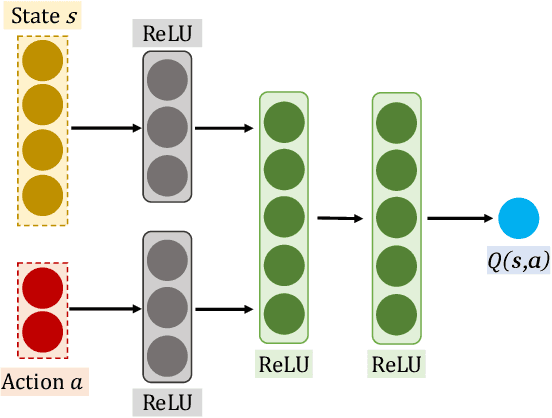

Improving the efficiency of dispatching orders to vehicles is a research hotspot in online ride-hailing systems. Most of the existing solutions for order-dispatching are centralized controlling, which require to consider all possible matches between available orders and vehicles. For large-scale ride-sharing platforms, there are thousands of vehicles and orders to be matched at every second which is of very high computational cost. In this paper, we propose a decentralized execution order-dispatching method based on multi-agent reinforcement learning to address the large-scale order-dispatching problem. Different from the previous cooperative multi-agent reinforcement learning algorithms, in our method, all agents work independently with the guidance from an evaluation of the joint policy since there is no need for communication or explicit cooperation between agents. Furthermore, we use KL-divergence optimization at each time step to speed up the learning process and to balance the vehicles (supply) and orders (demand). Experiments on both the explanatory environment and real-world simulator show that the proposed method outperforms the baselines in terms of accumulated driver income (ADI) and Order Response Rate (ORR) in various traffic environments. Besides, with the support of the online platform of Didi Chuxing, we designed a hybrid system to deploy our model.
Similarity Kernel and Clustering via Random Projection Forests
Aug 28, 2019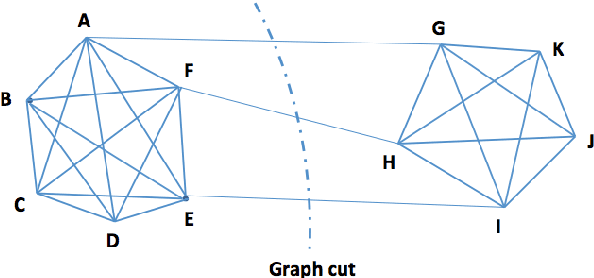
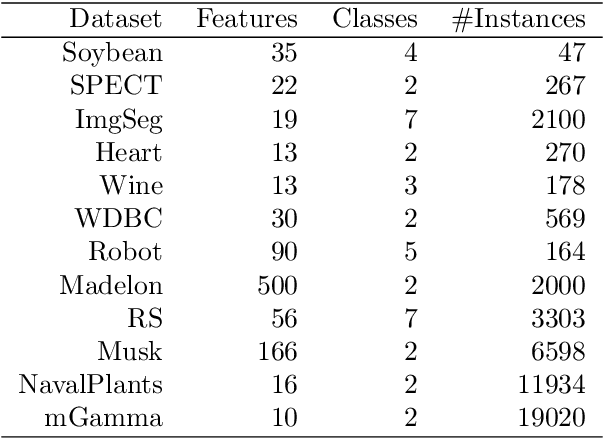
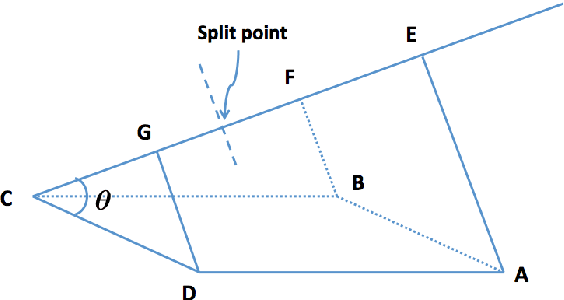
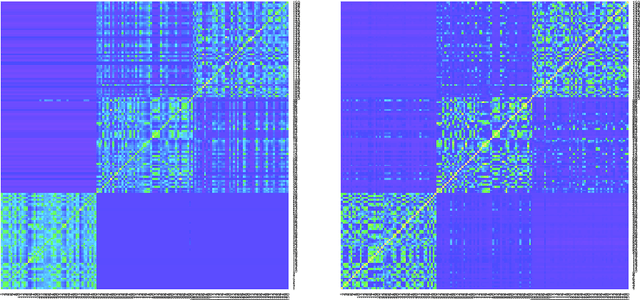
Similarity plays a fundamental role in many areas, including data mining, machine learning, statistics and various applied domains. Inspired by the success of ensemble methods and the flexibility of trees, we propose to learn a similarity kernel called rpf-kernel through random projection forests (rpForests). Our theoretical analysis reveals a highly desirable property of rpf-kernel: far-away (dissimilar) points have a low similarity value while nearby (similar) points would have a high similarity}, and the similarities have a native interpretation as the probability of points remaining in the same leaf nodes during the growth of rpForests. The learned rpf-kernel leads to an effective clustering algorithm--rpfCluster. On a wide variety of real and benchmark datasets, rpfCluster compares favorably to K-means clustering, spectral clustering and a state-of-the-art clustering ensemble algorithm--Cluster Forests. Our approach is simple to implement and readily adapt to the geometry of the underlying data. Given its desirable theoretical property and competitive empirical performance when applied to clustering, we expect rpf-kernel to be applicable to many problems of an unsupervised nature or as a regularizer in some supervised or weakly supervised settings.
Environment Reconstruction with Hidden Confounders for Reinforcement Learning based Recommendation
Jul 12, 2019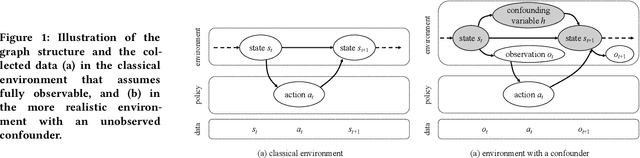
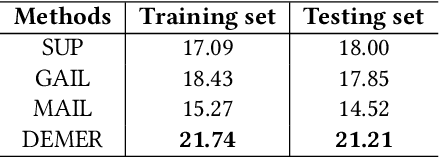
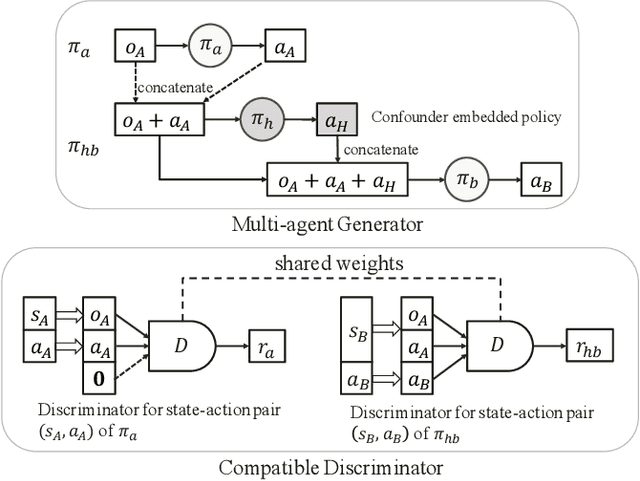
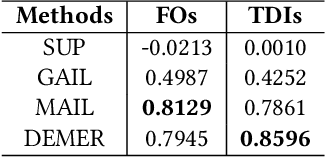
Reinforcement learning aims at searching the best policy model for decision making, and has been shown powerful for sequential recommendations. The training of the policy by reinforcement learning, however, is placed in an environment. In many real-world applications, however, the policy training in the real environment can cause an unbearable cost, due to the exploration in the environment. Environment reconstruction from the past data is thus an appealing way to release the power of reinforcement learning in these applications. The reconstruction of the environment is, basically, to extract the casual effect model from the data. However, real-world applications are often too complex to offer fully observable environment information. Therefore, quite possibly there are unobserved confounding variables lying behind the data. The hidden confounder can obstruct an effective reconstruction of the environment. In this paper, by treating the hidden confounder as a hidden policy, we propose a deconfounded multi-agent environment reconstruction (DEMER) approach in order to learn the environment together with the hidden confounder. DEMER adopts a multi-agent generative adversarial imitation learning framework. It proposes to introduce the confounder embedded policy, and use the compatible discriminator for training the policies. We then apply DEMER in an application of driver program recommendation. We firstly use an artificial driver program recommendation environment, abstracted from the real application, to verify and analyze the effectiveness of DEMER. We then test DEMER in the real application of Didi Chuxing. Experiment results show that DEMER can effectively reconstruct the hidden confounder, and thus can build the environment better. DEMER also derives a recommendation policy with a significantly improved performance in the test phase of the real application.
Cost-sensitive Selection of Variables by Ensemble of Model Sequences
Jan 02, 2019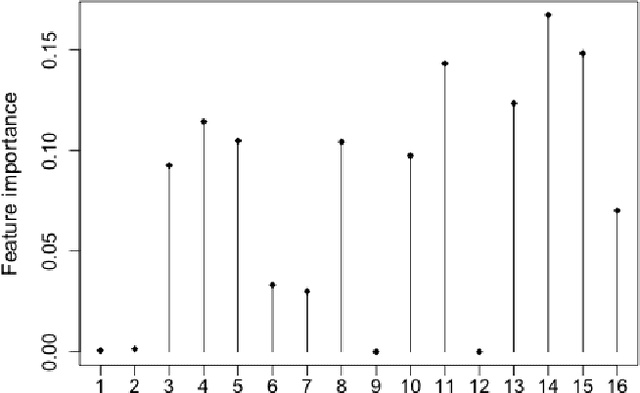
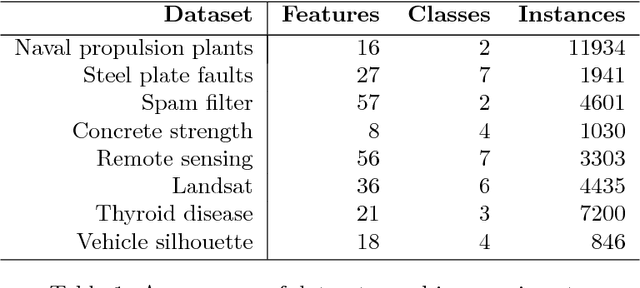
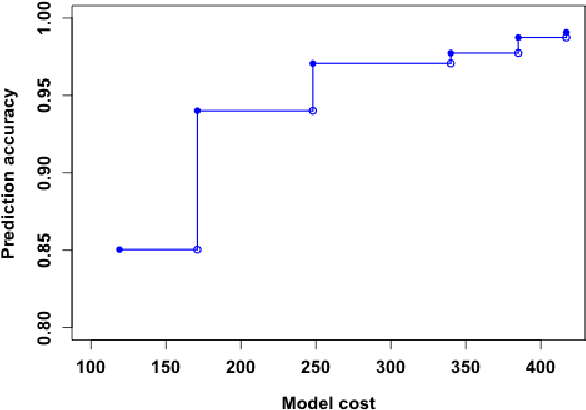
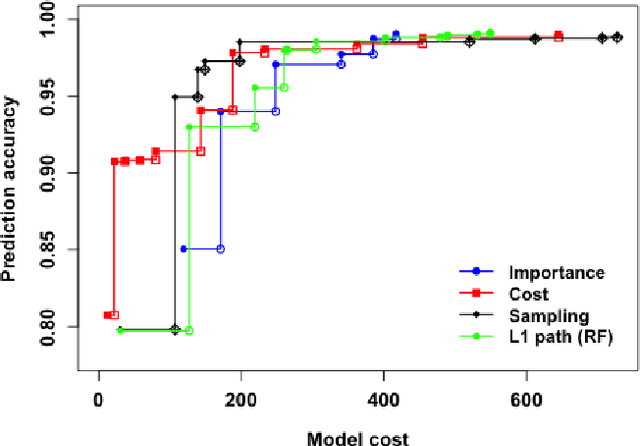
Many applications require the collection of data on different variables or measurements over many system performance metrics. We term those broadly as measures or variables. Often data collection along each measure incurs a cost, thus it is desirable to consider the cost of measures in modeling. This is a fairly new class of problems in the area of cost-sensitive learning. A few attempts have been made to incorporate costs in combining and selecting measures. However, existing studies either do not strictly enforce a budget constraint, or are not the `most' cost effective. With a focus on classification problem, we propose a computationally efficient approach that could find a near optimal model under a given budget by exploring the most `promising' part of the solution space. Instead of outputting a single model, we produce a model schedule---a list of models, sorted by model costs and expected predictive accuracy. This could be used to choose the model with the best predictive accuracy under a given budget, or to trade off between the budget and the predictive accuracy. Experiments on some benchmark datasets show that our approach compares favorably to competing methods.
Optimizing Taxi Carpool Policies via Reinforcement Learning and Spatio-Temporal Mining
Nov 11, 2018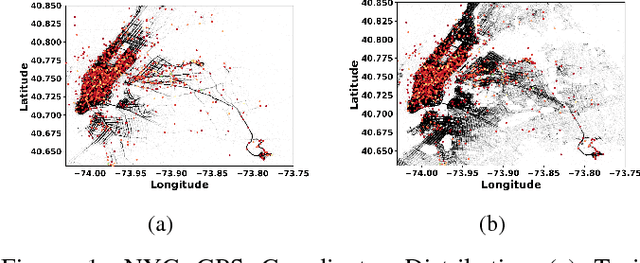

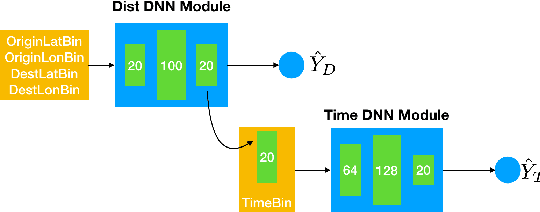
In this paper, we develop a reinforcement learning (RL) based system to learn an effective policy for carpooling that maximizes transportation efficiency so that fewer cars are required to fulfill the given amount of trip demand. For this purpose, first, we develop a deep neural network model, called ST-NN (Spatio-Temporal Neural Network), to predict taxi trip time from the raw GPS trip data. Secondly, we develop a carpooling simulation environment for RL training, with the output of ST-NN and using the NYC taxi trip dataset. In order to maximize transportation efficiency and minimize traffic congestion, we choose the effective distance covered by the driver on a carpool trip as the reward. Therefore, the more effective distance a driver achieves over a trip (i.e. to satisfy more trip demand) the higher the efficiency and the less will be the traffic congestion. We compared the performance of RL learned policy to a fixed policy (which always accepts carpool) as a baseline and obtained promising results that are interpretable and demonstrate the advantage of our RL approach. We also compare the performance of ST-NN to that of state-of-the-art travel time estimation methods and observe that ST-NN significantly improves the prediction performance and is more robust to outliers.
HIPAD - A Hybrid Interior-Point Alternating Direction algorithm for knowledge-based SVM and feature selection
Nov 16, 2014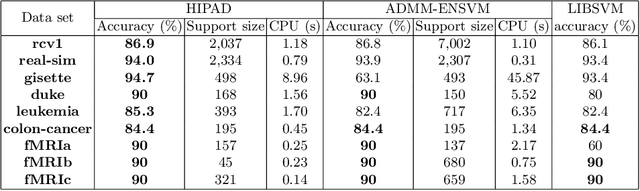

We consider classification tasks in the regime of scarce labeled training data in high dimensional feature space, where specific expert knowledge is also available. We propose a new hybrid optimization algorithm that solves the elastic-net support vector machine (SVM) through an alternating direction method of multipliers in the first phase, followed by an interior-point method for the classical SVM in the second phase. Both SVM formulations are adapted to knowledge incorporation. Our proposed algorithm addresses the challenges of automatic feature selection, high optimization accuracy, and algorithmic flexibility for taking advantage of prior knowledge. We demonstrate the effectiveness and efficiency of our algorithm and compare it with existing methods on a collection of synthetic and real-world data.
Robust Low-rank Tensor Recovery: Models and Algorithms
Nov 24, 2013
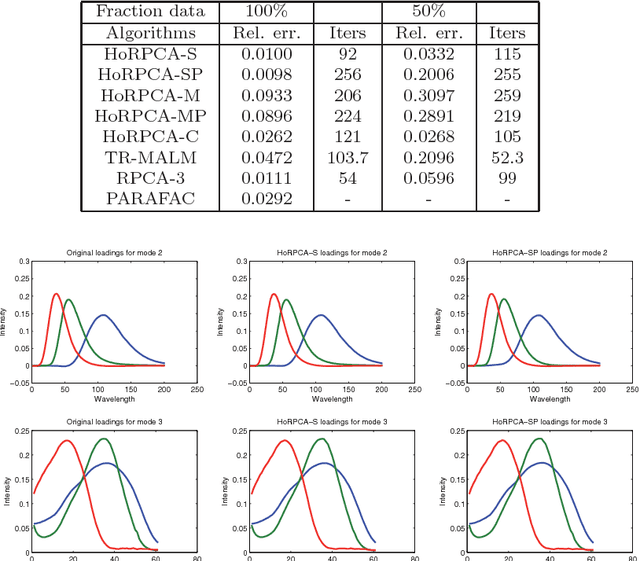


Robust tensor recovery plays an instrumental role in robustifying tensor decompositions for multilinear data analysis against outliers, gross corruptions and missing values and has a diverse array of applications. In this paper, we study the problem of robust low-rank tensor recovery in a convex optimization framework, drawing upon recent advances in robust Principal Component Analysis and tensor completion. We propose tailored optimization algorithms with global convergence guarantees for solving both the constrained and the Lagrangian formulations of the problem. These algorithms are based on the highly efficient alternating direction augmented Lagrangian and accelerated proximal gradient methods. We also propose a nonconvex model that can often improve the recovery results from the convex models. We investigate the empirical recoverability properties of the convex and nonconvex formulations and compare the computational performance of the algorithms on simulated data. We demonstrate through a number of real applications the practical effectiveness of this convex optimization framework for robust low-rank tensor recovery.
Structured Sparsity via Alternating Direction Methods
Dec 15, 2011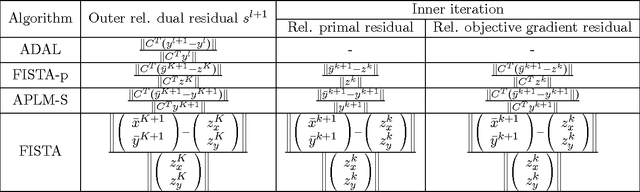
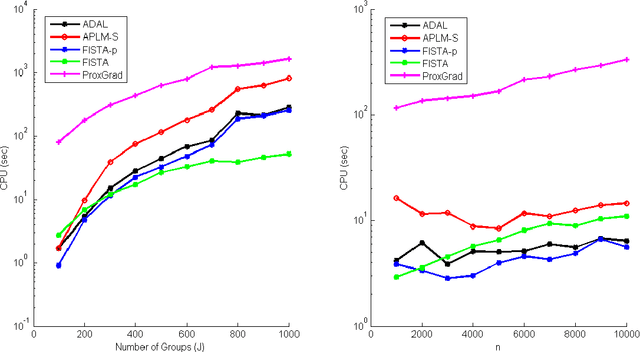
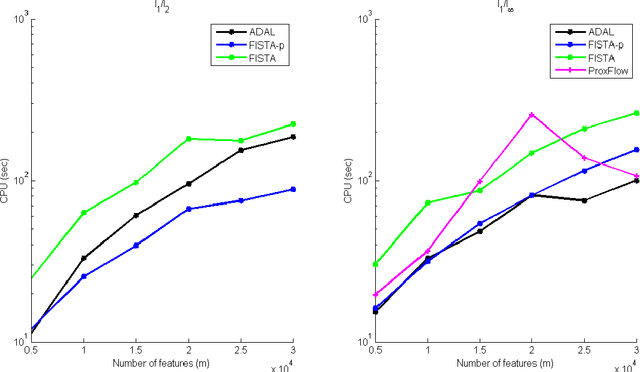

We consider a class of sparse learning problems in high dimensional feature space regularized by a structured sparsity-inducing norm which incorporates prior knowledge of the group structure of the features. Such problems often pose a considerable challenge to optimization algorithms due to the non-smoothness and non-separability of the regularization term. In this paper, we focus on two commonly adopted sparsity-inducing regularization terms, the overlapping Group Lasso penalty $l_1/l_2$-norm and the $l_1/l_\infty$-norm. We propose a unified framework based on the augmented Lagrangian method, under which problems with both types of regularization and their variants can be efficiently solved. As the core building-block of this framework, we develop new algorithms using an alternating partial-linearization/splitting technique, and we prove that the accelerated versions of these algorithms require $O(\frac{1}{\sqrt{\epsilon}})$ iterations to obtain an $\epsilon$-optimal solution. To demonstrate the efficiency and relevance of our algorithms, we test them on a collection of data sets and apply them to two real-world problems to compare the relative merits of the two norms.