 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFISHER: A Foundation Model for Multi-Modal Industrial Signal Comprehensive Representation
Jul 22, 2025With the rapid deployment of SCADA systems, how to effectively analyze industrial signals and detect abnormal states is an urgent need for the industry. Due to the significant heterogeneity of these signals, which we summarize as the M5 problem, previous works only focus on small sub-problems and employ specialized models, failing to utilize the synergies between modalities and the powerful scaling law. However, we argue that the M5 signals can be modeled in a unified manner due to the intrinsic similarity. As a result, we propose FISHER, a Foundation model for multi-modal Industrial Signal compreHEnsive Representation. To support arbitrary sampling rates, FISHER considers the increment of sampling rate as the concatenation of sub-band information. Specifically, FISHER takes the STFT sub-band as the modeling unit and adopts a teacher student SSL framework for pre-training. We also develop the RMIS benchmark, which evaluates the representations of M5 industrial signals on multiple health management tasks. Compared with top SSL models, FISHER showcases versatile and outstanding capabilities with a general performance gain up to 5.03%, along with much more efficient scaling curves. We also investigate the scaling law on downstream tasks and derive potential avenues for future works. FISHER is now open-sourced on https://github.com/jianganbai/FISHER
Given Users Recommendations Based on Reviews on Yelp
Dec 03, 2021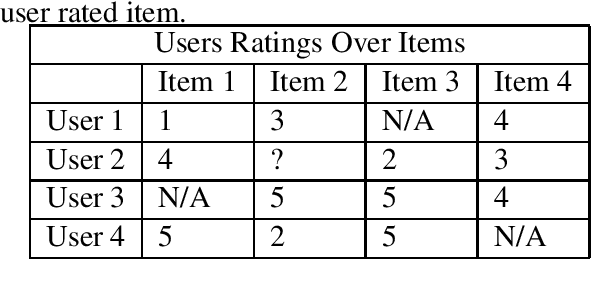
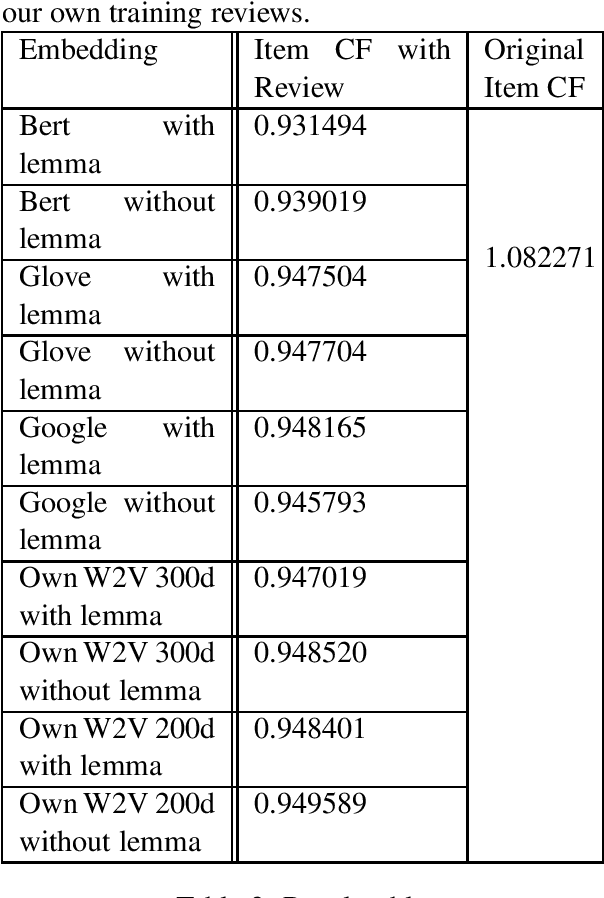
In our project, we focus on NLP-based hybrid recommendation systems. Our data is from Yelp Data. For our hybrid recommendation system, we have two major components: the first part is to embed the reviews with the Bert model and word2vec model; the second part is the implementation of an item-based collaborative filtering algorithm to compute the similarity of each review under different categories of restaurants. In the end, with the help of similarity scores, we are able to recommend users the most matched restaurant based on their recorded reviews. The coding work is split into several parts: selecting samples and data cleaning, processing, embedding, computing similarity, and computing prediction and error. Due to the size of the data, each part will generate one or more JSON files as the milestone to reduce the pressure on memory and the communication between each part.
Approximate Muscle Guided Beam Search for Three-Index Assignment Problem
Mar 06, 2017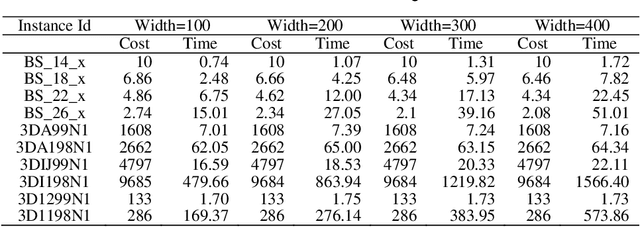
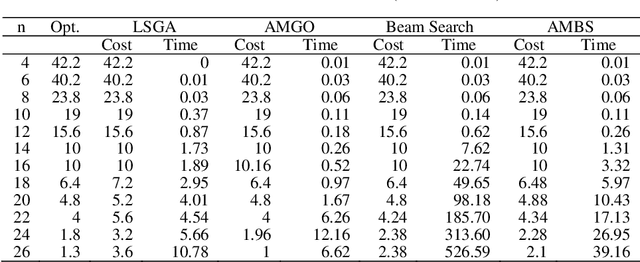
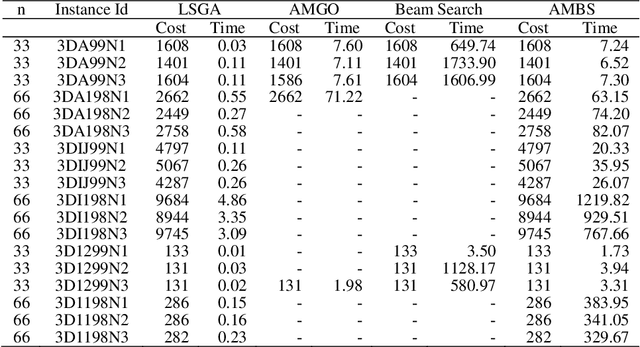
As a well-known NP-hard problem, the Three-Index Assignment Problem (AP3) has attracted lots of research efforts for developing heuristics. However, existing heuristics either obtain less competitive solutions or consume too much time. In this paper, a new heuristic named Approximate Muscle guided Beam Search (AMBS) is developed to achieve a good trade-off between solution quality and running time. By combining the approximate muscle with beam search, the solution space size can be significantly decreased, thus the time for searching the solution can be sharply reduced. Extensive experimental results on the benchmark indicate that the new algorithm is able to obtain solutions with competitive quality and it can be employed on instances with largescale. Work of this paper not only proposes a new efficient heuristic, but also provides a promising method to improve the efficiency of beam search.