 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciVisAgentSkills: Design and Evaluation of Agent Skills for Scientific Data Analysis and Visualization
Jun 04, 2026Recent advances in agentic visualization have enabled the translation of natural language into executable scientific visualization (SciVis) workflows. While general-purpose coding agents show strong capabilities, they often lack the tool-specific expertise required for SciVis tasks. In this work, we present SciVisAgentSkills, a collection of reusable agent skills that augment coding agents for scientific data analysis and visualization by encoding environment assumptions, tool usage patterns, and domain heuristics across scientific tools such as ParaView, napari, VMD, and TTK. We evaluate these skills on Codex and Claude Code using SciVisAgentBench, a benchmark of 108 expert-designed multi-step tasks. Results show that agent skills improve mean task scores across the evaluated suites, with token-efficiency benefits that depend on the agent harness and tool setting. These findings highlight the importance of structured procedural knowledge for enabling reliable, long-horizon SciVis workflows, while also showing that skills should be studied alongside the execution harness that loads and applies them. The skills are available at https://github.com/KuangshiAi/SciVisAgentSkills.
Toward AI VIS Co-Scientists: A General and End-to-End Agent Harness for Solving Complex Data Visualization Tasks
May 20, 2026The ability to inspect, interpret, and communicate complex data is crucial for virtually any scientific endeavor, but often requires significant expertise outside the core domain ranging from data management and analysis to visualization design and implementation. We present an end-to-end agentic harness that, based on only the data and a high level description of the tasks, independently designs custom visual analysis applications (VIS apps). This represents an important step towards a general AI co-scientist envisioned by many as an autonomous system that can autonomously execute long horizon tasks based on high-level directions. Our proposed VIS co-scientist is an essential component of this broader AI co-scientist vision: a harness that can autonomously analyze data and design visualization solutions using a collection of agents and specialized skills that coordinate exploratory analysis, plan, configure the environment, implement, validate the interface, and most importantly evaluate the overall task completion. Each stage produces document and instruction artifacts that guide downstream work and enable iterative refinement. We validate this approach on IEEE SciVis Contests spanning multiple science and engineering fields. These contests serve as ideal proving grounds because they encode real-world complexity: ambiguous requirements, diverse data modalities, design trade-offs, and task-driven validation. Given only the data and target tasks, our system autonomously produces functional single-page VIS Apps with verified linked-view behavior, highly customized to domain experts' specified tasks and needs.
SciVisAgentBench: A Benchmark for Evaluating Scientific Data Analysis and Visualization Agents
Mar 31, 2026Recent advances in large language models (LLMs) have enabled agentic systems that translate natural language intent into executable scientific visualization (SciVis) tasks. Despite rapid progress, the community lacks a principled and reproducible benchmark for evaluating these emerging SciVis agents in realistic, multi-step analysis settings. We present SciVisAgentBench, a comprehensive and extensible benchmark for evaluating scientific data analysis and visualization agents. Our benchmark is grounded in a structured taxonomy spanning four dimensions: application domain, data type, complexity level, and visualization operation. It currently comprises 108 expert-crafted cases covering diverse SciVis scenarios. To enable reliable assessment, we introduce a multimodal outcome-centric evaluation pipeline that combines LLM-based judging with deterministic evaluators, including image-based metrics, code checkers, rule-based verifiers, and case-specific evaluators. We also conduct a validity study with 12 SciVis experts to examine the agreement between human and LLM judges. Using this framework, we evaluate representative SciVis agents and general-purpose coding agents to establish initial baselines and reveal capability gaps. SciVisAgentBench is designed as a living benchmark to support systematic comparison, diagnose failure modes, and drive progress in agentic SciVis. The benchmark is available at https://scivisagentbench.github.io/.
An Evaluation-Centric Paradigm for Scientific Visualization Agents
Sep 18, 2025
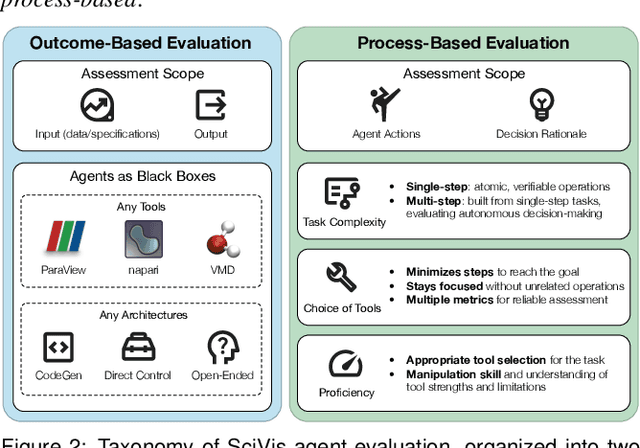
Recent advances in multi-modal large language models (MLLMs) have enabled increasingly sophisticated autonomous visualization agents capable of translating user intentions into data visualizations. However, measuring progress and comparing different agents remains challenging, particularly in scientific visualization (SciVis), due to the absence of comprehensive, large-scale benchmarks for evaluating real-world capabilities. This position paper examines the various types of evaluation required for SciVis agents, outlines the associated challenges, provides a simple proof-of-concept evaluation example, and discusses how evaluation benchmarks can facilitate agent self-improvement. We advocate for a broader collaboration to develop a SciVis agentic evaluation benchmark that would not only assess existing capabilities but also drive innovation and stimulate future development in the field.
ParaView-MCP: An Autonomous Visualization Agent with Direct Tool Use
May 11, 2025While powerful and well-established, tools like ParaView present a steep learning curve that discourages many potential users. This work introduces ParaView-MCP, an autonomous agent that integrates modern multimodal large language models (MLLMs) with ParaView to not only lower the barrier to entry but also augment ParaView with intelligent decision support. By leveraging the state-of-the-art reasoning, command execution, and vision capabilities of MLLMs, ParaView-MCP enables users to interact with ParaView through natural language and visual inputs. Specifically, our system adopted the Model Context Protocol (MCP) - a standardized interface for model-application communication - that facilitates direct interaction between MLLMs with ParaView's Python API to allow seamless information exchange between the user, the language model, and the visualization tool itself. Furthermore, by implementing a visual feedback mechanism that allows the agent to observe the viewport, we unlock a range of new capabilities, including recreating visualizations from examples, closed-loop visualization parameter updates based on user-defined goals, and even cross-application collaboration involving multiple tools. Broadly, we believe such an agent-driven visualization paradigm can profoundly change the way we interact with visualization tools. We expect a significant uptake in the development of such visualization tools, in both visualization research and industry.
See or Recall: A Sanity Check for the Role of Vision in Solving Visualization Question Answer Tasks with Multimodal LLMs
Apr 14, 2025Recent developments in multimodal large language models (MLLM) have equipped language models to reason about vision and language jointly. This permits MLLMs to both perceive and answer questions about data visualization across a variety of designs and tasks. Applying MLLMs to a broad range of visualization tasks requires us to properly evaluate their capabilities, and the most common way to conduct evaluation is through measuring a model's visualization reasoning capability, analogous to how we would evaluate human understanding of visualizations (e.g., visualization literacy). However, we found that in the context of visualization question answering (VisQA), how an MLLM perceives and reasons about visualizations can be fundamentally different from how humans approach the same problem. During the evaluation, even without visualization, the model could correctly answer a substantial portion of the visualization test questions, regardless of whether any selection options were provided. We hypothesize that the vast amount of knowledge encoded in the language model permits factual recall that supersedes the need to seek information from the visual signal. It raises concerns that the current VisQA evaluation may not fully capture the models' visualization reasoning capabilities. To address this, we propose a comprehensive sanity check framework that integrates a rule-based decision tree and a sanity check table to disentangle the effects of "seeing" (visual processing) and "recall" (reliance on prior knowledge). This validates VisQA datasets for evaluation, highlighting where models are truly "seeing", positively or negatively affected by the factual recall, or relying on inductive biases for question answering. Our study underscores the need for careful consideration in designing future visualization understanding studies when utilizing MLLMs.
AVA: Towards Autonomous Visualization Agents through Visual Perception-Driven Decision-Making
Dec 07, 2023With recent advances in multi-modal foundation models, the previously text-only large language models (LLM) have evolved to incorporate visual input, opening up unprecedented opportunities for various applications in visualization. Our work explores the utilization of the visual perception ability of multi-modal LLMs to develop Autonomous Visualization Agents (AVAs) that can interpret and accomplish user-defined visualization objectives through natural language. We propose the first framework for the design of AVAs and present several usage scenarios intended to demonstrate the general applicability of the proposed paradigm. The addition of visual perception allows AVAs to act as the virtual visualization assistant for domain experts who may lack the knowledge or expertise in fine-tuning visualization outputs. Our preliminary exploration and proof-of-concept agents suggest that this approach can be widely applicable whenever the choices of appropriate visualization parameters require the interpretation of previous visual output. Feedback from unstructured interviews with experts in AI research, medical visualization, and radiology has been incorporated, highlighting the practicality and potential of AVAs. Our study indicates that AVAs represent a general paradigm for designing intelligent visualization systems that can achieve high-level visualization goals, which pave the way for developing expert-level visualization agents in the future.