 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLimits To (Machine) Learning
Dec 14, 2025



Machine learning (ML) methods are highly flexible, but their ability to approximate the true data-generating process is fundamentally constrained by finite samples. We characterize a universal lower bound, the Limits-to-Learning Gap (LLG), quantifying the unavoidable discrepancy between a model's empirical fit and the population benchmark. Recovering the true population $R^2$, therefore, requires correcting observed predictive performance by this bound. Using a broad set of variables, including excess returns, yields, credit spreads, and valuation ratios, we find that the implied LLGs are large. This indicates that standard ML approaches can substantially understate true predictability in financial data. We also derive LLG-based refinements to the classic Hansen and Jagannathan (1991) bounds, analyze implications for parameter learning in general-equilibrium settings, and show that the LLG provides a natural mechanism for generating excess volatility.
Training NTK to Generalize with KARE
May 16, 2025The performance of the data-dependent neural tangent kernel (NTK; Jacot et al. (2018)) associated with a trained deep neural network (DNN) often matches or exceeds that of the full network. This implies that DNN training via gradient descent implicitly performs kernel learning by optimizing the NTK. In this paper, we propose instead to optimize the NTK explicitly. Rather than minimizing empirical risk, we train the NTK to minimize its generalization error using the recently developed Kernel Alignment Risk Estimator (KARE; Jacot et al. (2020)). Our simulations and real data experiments show that NTKs trained with KARE consistently match or significantly outperform the original DNN and the DNN- induced NTK (the after-kernel). These results suggest that explicitly trained kernels can outperform traditional end-to-end DNN optimization in certain settings, challenging the conventional dominance of DNNs. We argue that explicit training of NTK is a form of over-parametrized feature learning.
A Simple Algorithm For Scaling Up Kernel Methods
Jan 30, 2023The recent discovery of the equivalence between infinitely wide neural networks (NNs) in the lazy training regime and Neural Tangent Kernels (NTKs) (Jacot et al., 2018) has revived interest in kernel methods. However, conventional wisdom suggests kernel methods are unsuitable for large samples due to their computational complexity and memory requirements. We introduce a novel random feature regression algorithm that allows us (when necessary) to scale to virtually infinite numbers of random features. We illustrate the performance of our method on the CIFAR-10 dataset.
Deep Regression Ensembles
Mar 10, 2022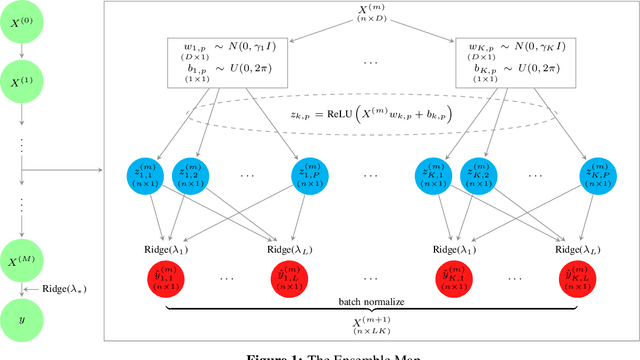
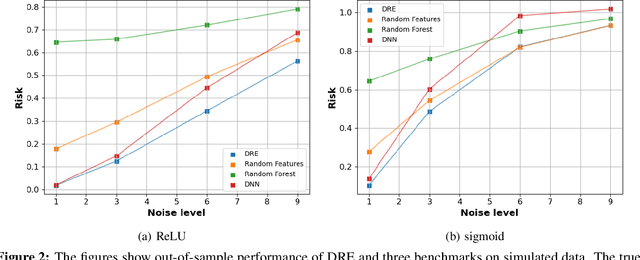
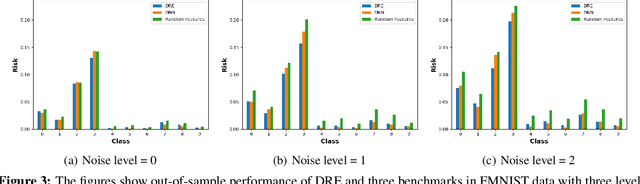
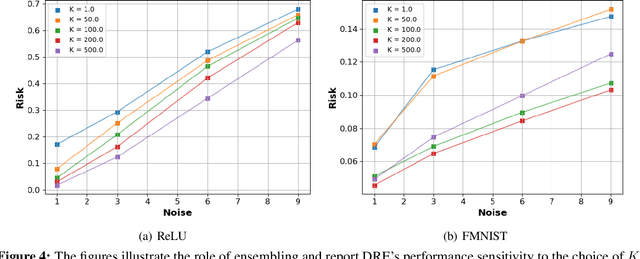
We introduce a methodology for designing and training deep neural networks (DNN) that we call "Deep Regression Ensembles" (DRE). It bridges the gap between DNN and two-layer neural networks trained with random feature regression. Each layer of DRE has two components, randomly drawn input weights and output weights trained myopically (as if the final output layer) using linear ridge regression. Within a layer, each neuron uses a different subset of inputs and a different ridge penalty, constituting an ensemble of random feature ridge regressions. Our experiments show that a single DRE architecture is at par with or exceeds state-of-the-art DNN in many data sets. Yet, because DRE neural weights are either known in closed-form or randomly drawn, its computational cost is orders of magnitude smaller than DNN.