 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashLabs Chroma 1.0: A Real-Time End-to-End Spoken Dialogue Model with Personalized Voice Cloning
Jan 16, 2026Recent end-to-end spoken dialogue systems leverage speech tokenizers and neural audio codecs to enable LLMs to operate directly on discrete speech representations. However, these models often exhibit limited speaker identity preservation, hindering personalized voice interaction. In this work, we present Chroma 1.0, the first open-source, real-time, end-to-end spoken dialogue model that achieves both low-latency interaction and high-fidelity personalized voice cloning. Chroma achieves sub-second end-to-end latency through an interleaved text-audio token schedule (1:2) that supports streaming generation, while maintaining high-quality personalized voice synthesis across multi-turn conversations. Our experimental results demonstrate that Chroma achieves a 10.96% relative improvement in speaker similarity over the human baseline, with a Real-Time Factor (RTF) of 0.43, while maintaining strong reasoning and dialogue capabilities. Our code and models are publicly available at https://github.com/FlashLabs-AI-Corp/FlashLabs-Chroma and https://huggingface.co/FlashLabs/Chroma-4B .
Multimodal Foundation Model-Driven User Interest Modeling and Behavior Analysis on Short Video Platforms
Sep 05, 2025With the rapid expansion of user bases on short video platforms, personalized recommendation systems are playing an increasingly critical role in enhancing user experience and optimizing content distribution. Traditional interest modeling methods often rely on unimodal data, such as click logs or text labels, which limits their ability to fully capture user preferences in a complex multimodal content environment. To address this challenge, this paper proposes a multimodal foundation model-based framework for user interest modeling and behavior analysis. By integrating video frames, textual descriptions, and background music into a unified semantic space using cross-modal alignment strategies, the framework constructs fine-grained user interest vectors. Additionally, we introduce a behavior-driven feature embedding mechanism that incorporates viewing, liking, and commenting sequences to model dynamic interest evolution, thereby improving both the timeliness and accuracy of recommendations. In the experimental phase, we conduct extensive evaluations using both public and proprietary short video datasets, comparing our approach against multiple mainstream recommendation algorithms and modeling techniques. Results demonstrate significant improvements in behavior prediction accuracy, interest modeling for cold-start users, and recommendation click-through rates. Moreover, we incorporate interpretability mechanisms using attention weights and feature visualization to reveal the model's decision basis under multimodal inputs and trace interest shifts, thereby enhancing the transparency and controllability of the recommendation system.
Synergistic Prompting for Robust Visual Recognition with Missing Modalities
Jul 10, 2025Large-scale multi-modal models have demonstrated remarkable performance across various visual recognition tasks by leveraging extensive paired multi-modal training data. However, in real-world applications, the presence of missing or incomplete modality inputs often leads to significant performance degradation. Recent research has focused on prompt-based strategies to tackle this issue; however, existing methods are hindered by two major limitations: (1) static prompts lack the flexibility to adapt to varying missing-data conditions, and (2) basic prompt-tuning methods struggle to ensure reliable performance when critical modalities are missing.To address these challenges, we propose a novel Synergistic Prompting (SyP) framework for robust visual recognition with missing modalities. The proposed SyP introduces two key innovations: (I) a Dynamic Adapter, which computes adaptive scaling factors to dynamically generate prompts, replacing static parameters for flexible multi-modal adaptation, and (II) a Synergistic Prompting Strategy, which combines static and dynamic prompts to balance information across modalities, ensuring robust reasoning even when key modalities are missing. The proposed SyP achieves significant performance improvements over existing approaches across three widely-used visual recognition datasets, demonstrating robustness under diverse missing rates and conditions. Extensive experiments and ablation studies validate its effectiveness in handling missing modalities, highlighting its superior adaptability and reliability.
MEGA: Second-Order Gradient Alignment for Catastrophic Forgetting Mitigation in GFSCIL
Apr 18, 2025Graph Few-Shot Class-Incremental Learning (GFSCIL) enables models to continually learn from limited samples of novel tasks after initial training on a large base dataset. Existing GFSCIL approaches typically utilize Prototypical Networks (PNs) for metric-based class representations and fine-tune the model during the incremental learning stage. However, these PN-based methods oversimplify learning via novel query set fine-tuning and fail to integrate Graph Continual Learning (GCL) techniques due to architectural constraints. To address these challenges, we propose a more rigorous and practical setting for GFSCIL that excludes query sets during the incremental training phase. Building on this foundation, we introduce Model-Agnostic Meta Graph Continual Learning (MEGA), aimed at effectively alleviating catastrophic forgetting for GFSCIL. Specifically, by calculating the incremental second-order gradient during the meta-training stage, we endow the model to learn high-quality priors that enhance incremental learning by aligning its behaviors across both the meta-training and incremental learning stages. Extensive experiments on four mainstream graph datasets demonstrate that MEGA achieves state-of-the-art results and enhances the effectiveness of various GCL methods in GFSCIL. We believe that our proposed MEGA serves as a model-agnostic GFSCIL paradigm, paving the way for future research.
DWCL: Dual-Weighted Contrastive Learning for Multi-View Clustering
Nov 26, 2024



Multi-view contrastive clustering (MVCC) has gained significant attention for generating consistent clustering structures from multiple views through contrastive learning. However, most existing MVCC methods create cross-views by combining any two views, leading to a high volume of unreliable pairs. Furthermore, these approaches often overlook discrepancies in multi-view representations, resulting in representation degeneration. To address these challenges, we introduce a novel model called Dual-Weighted Contrastive Learning (DWCL) for Multi-View Clustering. Specifically, to reduce the impact of unreliable cross-views, we introduce an innovative Best-Other (B-O) contrastive mechanism that enhances the representation of individual views at a low computational cost. Furthermore, we develop a dual weighting strategy that combines a view quality weight, reflecting the quality of each view, with a view discrepancy weight. This approach effectively mitigates representation degeneration by downplaying cross-views that are both low in quality and high in discrepancy. We theoretically validate the efficiency of the B-O contrastive mechanism and the effectiveness of the dual weighting strategy. Extensive experiments demonstrate that DWCL outperforms previous methods across eight multi-view datasets, showcasing superior performance and robustness in MVCC. Specifically, our method achieves absolute accuracy improvements of 5.4\% and 5.6\% compared to state-of-the-art methods on the Caltech6V7 and MSRCv1 datasets, respectively.
ESC-MISR: Enhancing Spatial Correlations for Multi-Image Super-Resolution in Remote Sensing
Nov 07, 2024



Multi-Image Super-Resolution (MISR) is a crucial yet challenging research task in the remote sensing community. In this paper, we address the challenging task of Multi-Image Super-Resolution in Remote Sensing (MISR-RS), aiming to generate a High-Resolution (HR) image from multiple Low-Resolution (LR) images obtained by satellites. Recently, the weak temporal correlations among LR images have attracted increasing attention in the MISR-RS task. However, existing MISR methods treat the LR images as sequences with strong temporal correlations, overlooking spatial correlations and imposing temporal dependencies. To address this problem, we propose a novel end-to-end framework named Enhancing Spatial Correlations in MISR (ESC-MISR), which fully exploits the spatial-temporal relations of multiple images for HR image reconstruction. Specifically, we first introduce a novel fusion module named Multi-Image Spatial Transformer (MIST), which emphasizes parts with clearer global spatial features and enhances the spatial correlations between LR images. Besides, we perform a random shuffle strategy for the sequential inputs of LR images to attenuate temporal dependencies and capture weak temporal correlations in the training stage. Compared with the state-of-the-art methods, our ESC-MISR achieves 0.70dB and 0.76dB cPSNR improvements on the two bands of the PROBA-V dataset respectively, demonstrating the superiority of our method.
FTF-ER: Feature-Topology Fusion-Based Experience Replay Method for Continual Graph Learning
Jul 28, 2024



Continual graph learning (CGL) is an important and challenging task that aims to extend static GNNs to dynamic task flow scenarios. As one of the mainstream CGL methods, the experience replay (ER) method receives widespread attention due to its superior performance. However, existing ER methods focus on identifying samples by feature significance or topological relevance, which limits their utilization of comprehensive graph data. In addition, the topology-based ER methods only consider local topological information and add neighboring nodes to the buffer, which ignores the global topological information and increases memory overhead. To bridge these gaps, we propose a novel method called Feature-Topology Fusion-based Experience Replay (FTF-ER) to effectively mitigate the catastrophic forgetting issue with enhanced efficiency. Specifically, from an overall perspective to maximize the utilization of the entire graph data, we propose a highly complementary approach including both feature and global topological information, which can significantly improve the effectiveness of the sampled nodes. Moreover, to further utilize global topological information, we propose Hodge Potential Score (HPS) as a novel module to calculate the topological importance of nodes. HPS derives a global node ranking via Hodge decomposition on graphs, providing more accurate global topological information compared to neighbor sampling. By excluding neighbor sampling, HPS significantly reduces buffer storage costs for acquiring topological information and simultaneously decreases training time. Compared with state-of-the-art methods, FTF-ER achieves a significant improvement of 3.6% in AA and 7.1% in AF on the OGB-Arxiv dataset, demonstrating its superior performance in the class-incremental learning setting.
Context-aware Session-based Recommendation with Graph Neural Networks
Oct 14, 2023Session-based recommendation (SBR) is a task that aims to predict items based on anonymous sequences of user behaviors in a session. While there are methods that leverage rich context information in sessions for SBR, most of them have the following limitations: 1) they fail to distinguish the item-item edge types when constructing the global graph for exploiting cross-session contexts; 2) they learn a fixed embedding vector for each item, which lacks the flexibility to reflect the variation of user interests across sessions; 3) they generally use the one-hot encoded vector of the target item as the hard label to predict, thus failing to capture the true user preference. To solve these issues, we propose CARES, a novel context-aware session-based recommendation model with graph neural networks, which utilizes different types of contexts in sessions to capture user interests. Specifically, we first construct a multi-relation cross-session graph to connect items according to intra- and cross-session item-level contexts. Further, to encode the variation of user interests, we design personalized item representations. Finally, we employ a label collaboration strategy for generating soft user preference distribution as labels. Experiments on three benchmark datasets demonstrate that CARES consistently outperforms state-of-the-art models in terms of P@20 and MRR@20. Our data and codes are publicly available at https://github.com/brilliantZhang/CARES.
Accelerating Generic Graph Neural Networks via Architecture, Compiler, Partition Method Co-Design
Aug 16, 2023Graph neural networks (GNNs) have shown significant accuracy improvements in a variety of graph learning domains, sparking considerable research interest. To translate these accuracy improvements into practical applications, it is essential to develop high-performance and efficient hardware acceleration for GNN models. However, designing GNN accelerators faces two fundamental challenges: the high bandwidth requirement of GNN models and the diversity of GNN models. Previous works have addressed the first challenge by using more expensive memory interfaces to achieve higher bandwidth. For the second challenge, existing works either support specific GNN models or have generic designs with poor hardware utilization. In this work, we tackle both challenges simultaneously. First, we identify a new type of partition-level operator fusion, which we utilize to internally reduce the high bandwidth requirement of GNNs. Next, we introduce partition-level multi-threading to schedule the concurrent processing of graph partitions, utilizing different hardware resources. To further reduce the extra on-chip memory required by multi-threading, we propose fine-grained graph partitioning to generate denser graph partitions. Importantly, these three methods make no assumptions about the targeted GNN models, addressing the challenge of model variety. We implement these methods in a framework called SwitchBlade, consisting of a compiler, a graph partitioner, and a hardware accelerator. Our evaluation demonstrates that SwitchBlade achieves an average speedup of $1.85\times$ and energy savings of $19.03\times$ compared to the NVIDIA V100 GPU. Additionally, SwitchBlade delivers performance comparable to state-of-the-art specialized accelerators.
Architectural Implications of Graph Neural Networks
Sep 02, 2020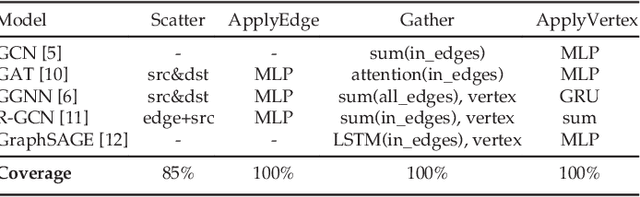
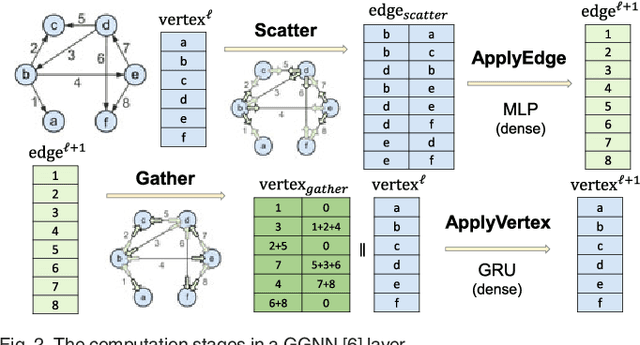
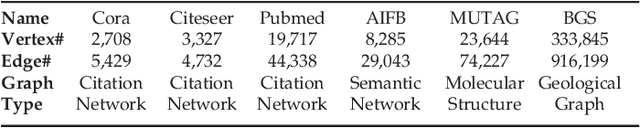
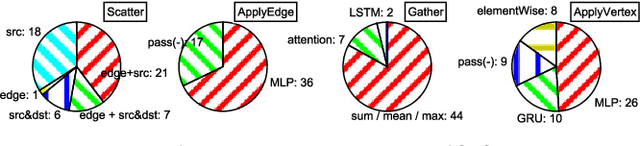
Graph neural networks (GNN) represent an emerging line of deep learning models that operate on graph structures. It is becoming more and more popular due to its high accuracy achieved in many graph-related tasks. However, GNN is not as well understood in the system and architecture community as its counterparts such as multi-layer perceptrons and convolutional neural networks. This work tries to introduce the GNN to our community. In contrast to prior work that only presents characterizations of GCNs, our work covers a large portion of the varieties for GNN workloads based on a general GNN description framework. By constructing the models on top of two widely-used libraries, we characterize the GNN computation at inference stage concerning general-purpose and application-specific architectures and hope our work can foster more system and architecture research for GNNs.
* 4 pages, published in IEEE Computer Architecture Letters (CAL) 2020