 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIT at SemEval-2022 Task 2: Pre-trained Language Model for Idioms Detection
Apr 13, 2022

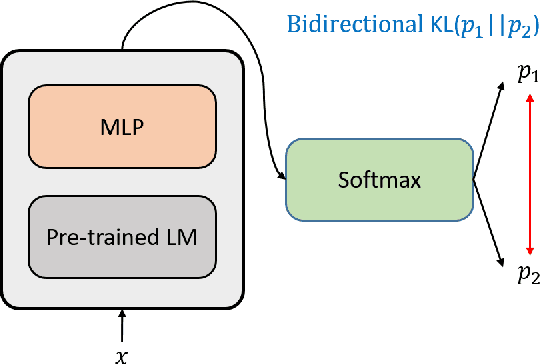

The same multi-word expressions may have different meanings in different sentences. They can be mainly divided into two categories, which are literal meaning and idiomatic meaning. Non-contextual-based methods perform poorly on this problem, and we need contextual embedding to understand the idiomatic meaning of multi-word expressions correctly. We use a pre-trained language model, which can provide a context-aware sentence embedding, to detect whether multi-word expression in the sentence is idiomatic usage.
HFL at SemEval-2022 Task 8: A Linguistics-inspired Regression Model with Data Augmentation for Multilingual News Similarity
Apr 11, 2022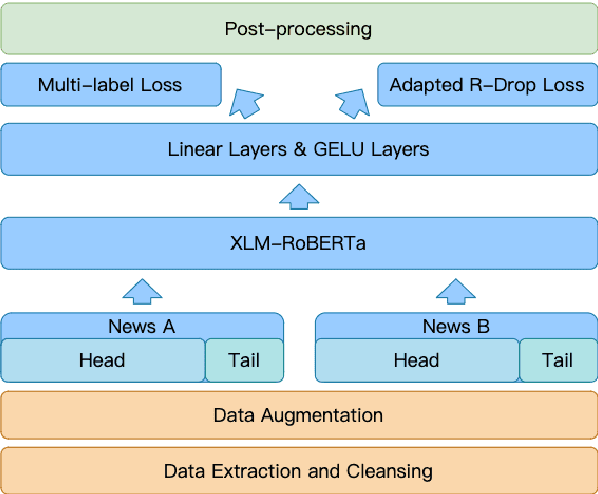

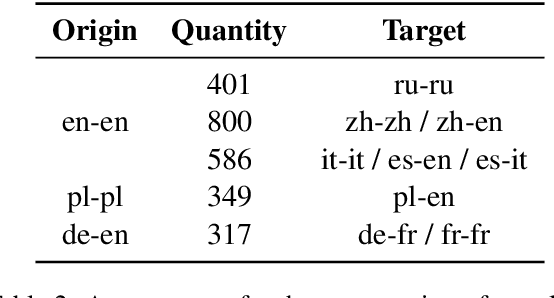
This paper describes our system designed for SemEval-2022 Task 8: Multilingual News Article Similarity. We proposed a linguistics-inspired model trained with a few task-specific strategies. The main techniques of our system are: 1) data augmentation, 2) multi-label loss, 3) adapted R-Drop, 4) samples reconstruction with the head-tail combination. We also present a brief analysis of some negative methods like two-tower architecture. Our system ranked 1st on the leaderboard while achieving a Pearson's Correlation Coefficient of 0.818 on the official evaluation set.
TextPruner: A Model Pruning Toolkit for Pre-Trained Language Models
Mar 30, 2022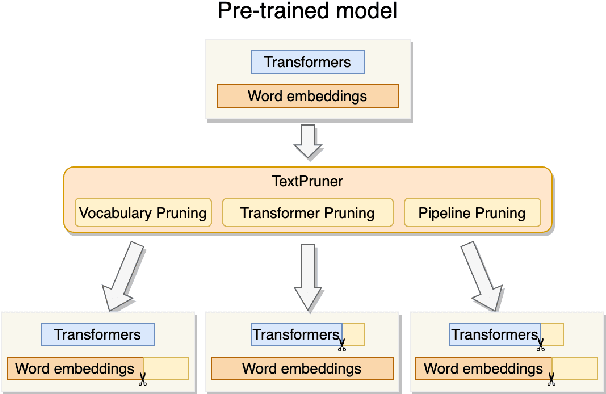

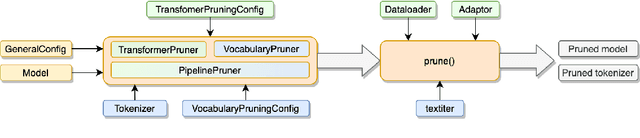
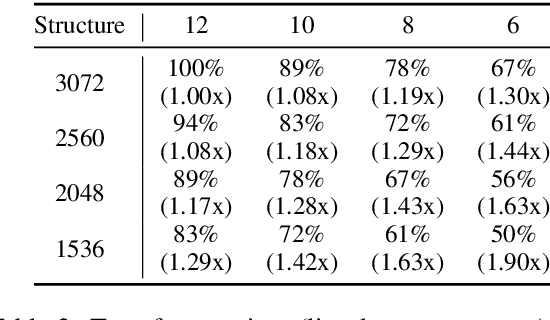
Pre-trained language models have been prevailed in natural language processing and become the backbones of many NLP tasks, but the demands for computational resources have limited their applications. In this paper, we introduce TextPruner, an open-source model pruning toolkit designed for pre-trained language models, targeting fast and easy model compression. TextPruner offers structured post-training pruning methods, including vocabulary pruning and transformer pruning, and can be applied to various models and tasks. We also propose a self-supervised pruning method that can be applied without the labeled data. Our experiments with several NLP tasks demonstrate the ability of TextPruner to reduce the model size without re-training the model.
Cross-Lingual Text Classification with Multilingual Distillation and Zero-Shot-Aware Training
Feb 28, 2022Multilingual pre-trained language models (MPLMs) not only can handle tasks in different languages but also exhibit surprising zero-shot cross-lingual transferability. However, MPLMs usually are not able to achieve comparable supervised performance on rich-resource languages compared to the state-of-the-art monolingual pre-trained models. In this paper, we aim to improve the multilingual model's supervised and zero-shot performance simultaneously only with the resources from supervised languages. Our approach is based on transferring knowledge from high-performance monolingual models with a teacher-student framework. We let the multilingual model learn from multiple monolingual models simultaneously. To exploit the model's cross-lingual transferability, we propose MBLM (multi-branch multilingual language model), a model built on the MPLMs with multiple language branches. Each branch is a stack of transformers. MBLM is trained with the zero-shot-aware training strategy that encourages the model to learn from the mixture of zero-shot representations from all the branches. The results on two cross-lingual classification tasks show that, with only the task's supervised data used, our method improves both the supervised and zero-shot performance of MPLMs.
CINO: A Chinese Minority Pre-trained Language Model
Feb 28, 2022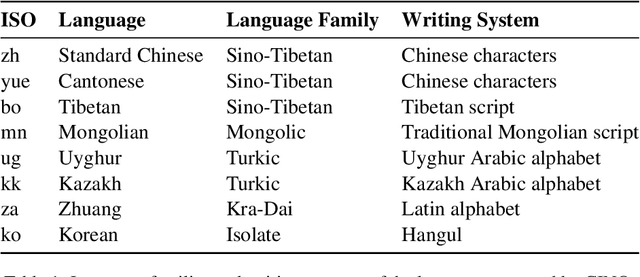

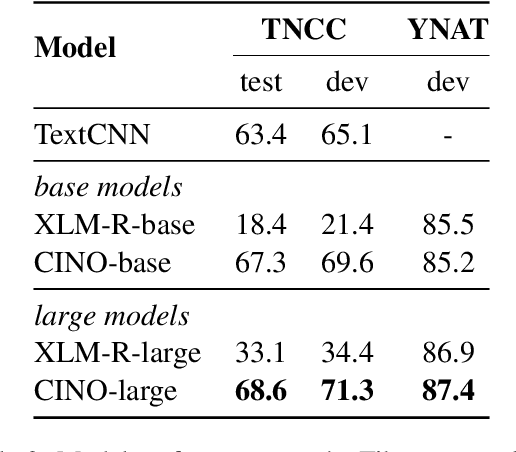

Multilingual pre-trained language models have shown impressive performance on cross-lingual tasks. It greatly facilitates the applications of natural language processing on low-resource languages. However, there are still some languages that the existing multilingual models do not perform well on. In this paper, we propose CINO (Chinese Minority Pre-trained Language Model), a multilingual pre-trained language model for Chinese minority languages. It covers Standard Chinese, Cantonese, and six other Chinese minority languages. To evaluate the cross-lingual ability of the multilingual models on the minority languages, we collect documents from Wikipedia and build a text classification dataset WCM (Wiki-Chinese-Minority). We test CINO on WCM and two other text classification tasks. Experiments show that CINO outperforms the baselines notably. The CINO model and the WCM dataset are available at http://cino.hfl-rc.com.
InterHT: Knowledge Graph Embeddings by Interaction between Head and Tail Entities
Feb 10, 2022
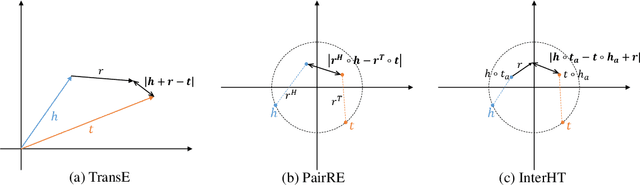
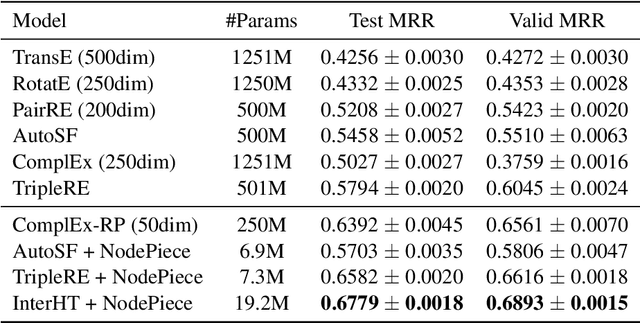
Knowledge graph embedding (KGE) models learn the representation of entities and relations in knowledge graphs. Distance-based methods show promising performance on link prediction task, which predicts the result by the distance between two entity representations. However, most of these methods represent the head entity and tail entity separately, which limits the model capacity. We propose a novel distance-based method named InterHT that allows the head and tail entities to interact better and get better entity representation. Experimental results show that our proposed method achieves the best results on ogbl-wikikg2 dataset.
Knowledge Enhanced Sports Game Summarization
Nov 24, 2021

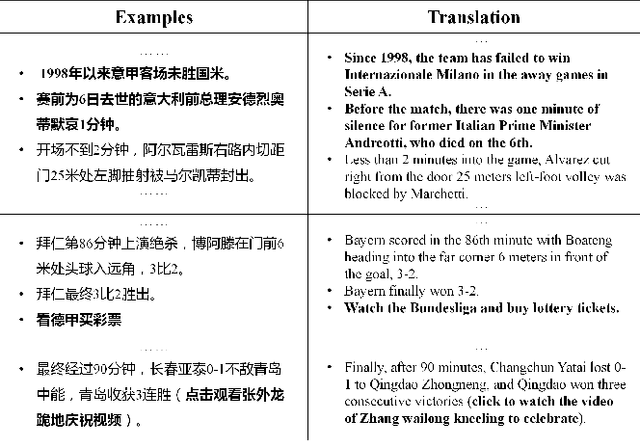
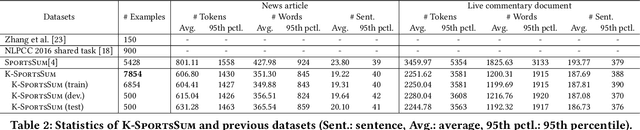
Sports game summarization aims at generating sports news from live commentaries. However, existing datasets are all constructed through automated collection and cleaning processes, resulting in a lot of noise. Besides, current works neglect the knowledge gap between live commentaries and sports news, which limits the performance of sports game summarization. In this paper, we introduce K-SportsSum, a new dataset with two characteristics: (1) K-SportsSum collects a large amount of data from massive games. It has 7,854 commentary-news pairs. To improve the quality, K-SportsSum employs a manual cleaning process; (2) Different from existing datasets, to narrow the knowledge gap, K-SportsSum further provides a large-scale knowledge corpus that contains the information of 523 sports teams and 14,724 sports players. Additionally, we also introduce a knowledge-enhanced summarizer that utilizes both live commentaries and the knowledge to generate sports news. Extensive experiments on K-SportsSum and SportsSum datasets show that our model achieves new state-of-the-art performances. Qualitative analysis and human study further verify that our model generates more informative sports news.
SportsSum2.0: Generating High-Quality Sports News from Live Text Commentary
Oct 12, 2021
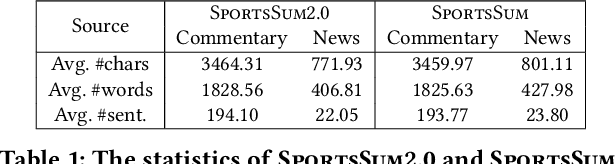
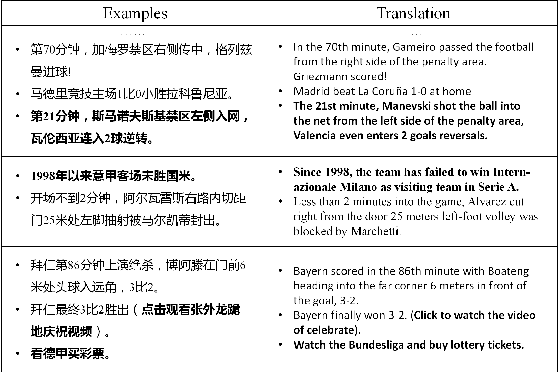
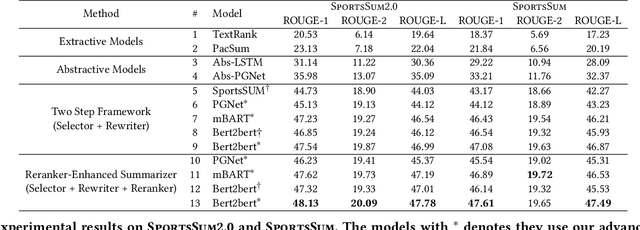
Sports game summarization aims to generate news articles from live text commentaries. A recent state-of-the-art work, SportsSum, not only constructs a large benchmark dataset, but also proposes a two-step framework. Despite its great contributions, the work has three main drawbacks: 1) the noise existed in SportsSum dataset degrades the summarization performance; 2) the neglect of lexical overlap between news and commentaries results in low-quality pseudo-labeling algorithm; 3) the usage of directly concatenating rewritten sentences to form news limits its practicability. In this paper, we publish a new benchmark dataset SportsSum2.0, together with a modified summarization framework. In particular, to obtain a clean dataset, we employ crowd workers to manually clean the original dataset. Moreover, the degree of lexical overlap is incorporated into the generation of pseudo labels. Further, we introduce a reranker-enhanced summarizer to take into account the fluency and expressiveness of the summarized news. Extensive experiments show that our model outperforms the state-of-the-art baseline.
Affective Decoding for Empathetic Response Generation
Sep 03, 2021

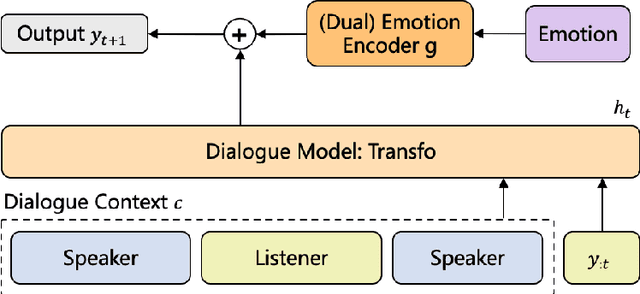
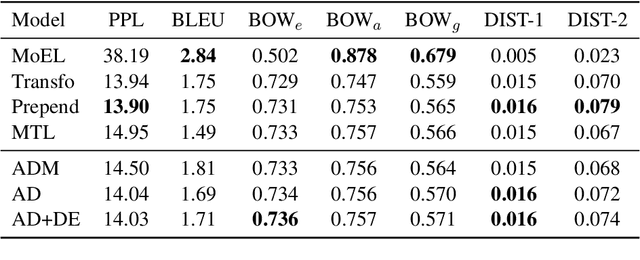
Understanding speaker's feelings and producing appropriate responses with emotion connection is a key communicative skill for empathetic dialogue systems. In this paper, we propose a simple technique called Affective Decoding for empathetic response generation. Our method can effectively incorporate emotion signals during each decoding step, and can additionally be augmented with an auxiliary dual emotion encoder, which learns separate embeddings for the speaker and listener given the emotion base of the dialogue. Extensive empirical studies show that our models are perceived to be more empathetic by human evaluations, in comparison to several strong mainstream methods for empathetic responding.
Detecting Speaker Personas from Conversational Texts
Sep 03, 2021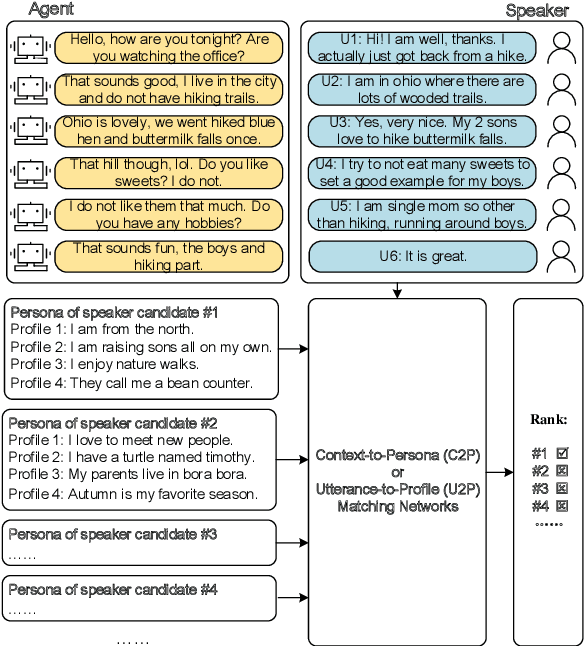
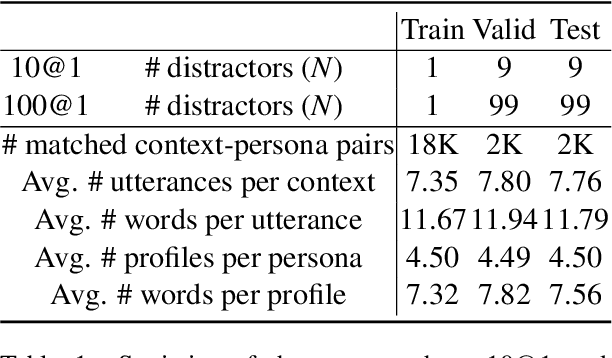
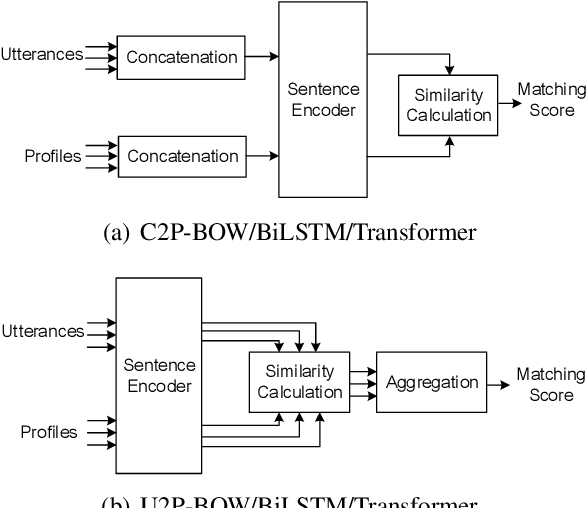
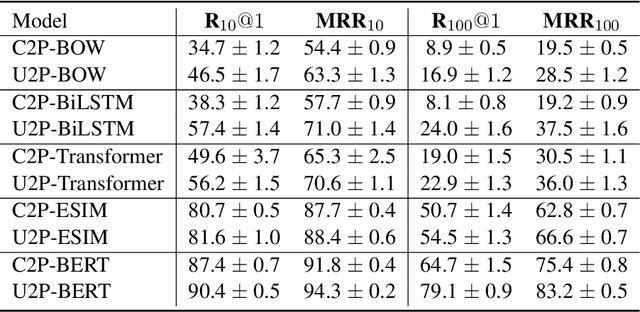
Personas are useful for dialogue response prediction. However, the personas used in current studies are pre-defined and hard to obtain before a conversation. To tackle this issue, we study a new task, named Speaker Persona Detection (SPD), which aims to detect speaker personas based on the plain conversational text. In this task, a best-matched persona is searched out from candidates given the conversational text. This is a many-to-many semantic matching task because both contexts and personas in SPD are composed of multiple sentences. The long-term dependency and the dynamic redundancy among these sentences increase the difficulty of this task. We build a dataset for SPD, dubbed as Persona Match on Persona-Chat (PMPC). Furthermore, we evaluate several baseline models and propose utterance-to-profile (U2P) matching networks for this task. The U2P models operate at a fine granularity which treat both contexts and personas as sets of multiple sequences. Then, each sequence pair is scored and an interpretable overall score is obtained for a context-persona pair through aggregation. Evaluation results show that the U2P models outperform their baseline counterparts significantly.