 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-objective Evolution of Heuristic Using Large Language Model
Sep 25, 2024



Heuristics are commonly used to tackle diverse search and optimization problems. Design heuristics usually require tedious manual crafting with domain knowledge. Recent works have incorporated large language models (LLMs) into automatic heuristic search leveraging their powerful language and coding capacity. However, existing research focuses on the optimal performance on the target problem as the sole objective, neglecting other criteria such as efficiency and scalability, which are vital in practice. To tackle this challenge, we propose to model heuristic search as a multi-objective optimization problem and consider introducing other practical criteria beyond optimal performance. Due to the complexity of the search space, conventional multi-objective optimization methods struggle to effectively handle multi-objective heuristic search. We propose the first LLM-based multi-objective heuristic search framework, Multi-objective Evolution of Heuristic (MEoH), which integrates LLMs in a zero-shot manner to generate a non-dominated set of heuristics to meet multiple design criteria. We design a new dominance-dissimilarity mechanism for effective population management and selection, which incorporates both code dissimilarity in the search space and dominance in the objective space. MEoH is demonstrated in two well-known combinatorial optimization problems: the online Bin Packing Problem (BPP) and the Traveling Salesman Problem (TSP). Results indicate that a variety of elite heuristics are automatically generated in a single run, offering more trade-off options than existing methods. It successfully achieves competitive or superior performance while improving efficiency up to 10 times. Moreover, we also observe that the multi-objective search introduces novel insights into heuristic design and leads to the discovery of diverse heuristics.
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition
Aug 29, 2024



For visual recognition, knowledge distillation typically involves transferring knowledge from a large, well-trained teacher model to a smaller student model. In this paper, we introduce an effective method to distill knowledge from an off-the-shelf vision-language model (VLM), demonstrating that it provides novel supervision in addition to those from a conventional vision-only teacher model. Our key technical contribution is the development of a framework that generates novel text supervision and distills free-form text into a vision encoder. We showcase the effectiveness of our approach, termed VLM-KD, across various benchmark datasets, showing that it surpasses several state-of-the-art long-tail visual classifiers. To our knowledge, this work is the first to utilize knowledge distillation with text supervision generated by an off-the-shelf VLM and apply it to vanilla randomly initialized vision encoders.
SpikingSSMs: Learning Long Sequences with Sparse and Parallel Spiking State Space Models
Aug 27, 2024



Known as low energy consumption networks, spiking neural networks (SNNs) have gained a lot of attention within the past decades. While SNNs are increasing competitive with artificial neural networks (ANNs) for vision tasks, they are rarely used for long sequence tasks, despite their intrinsic temporal dynamics. In this work, we develop spiking state space models (SpikingSSMs) for long sequence learning by leveraging on the sequence learning abilities of state space models (SSMs). Inspired by dendritic neuron structure, we hierarchically integrate neuronal dynamics with the original SSM block, meanwhile realizing sparse synaptic computation. Furthermore, to solve the conflict of event-driven neuronal dynamics with parallel computing, we propose a light-weight surrogate dynamic network which accurately predicts the after-reset membrane potential and compatible to learnable thresholds, enabling orders of acceleration in training speed compared with conventional iterative methods. On the long range arena benchmark task, SpikingSSM achieves competitive performance to state-of-the-art SSMs meanwhile realizing on average 90\% of network sparsity. On language modeling, our network significantly surpasses existing spiking large language models (spikingLLMs) on the WikiText-103 dataset with only a third of the model size, demonstrating its potential as backbone architecture for low computation cost LLMs.
Design Principle Transfer in Neural Architecture Search via Large Language Models
Aug 21, 2024



Transferable neural architecture search (TNAS) has been introduced to design efficient neural architectures for multiple tasks, to enhance the practical applicability of NAS in real-world scenarios. In TNAS, architectural knowledge accumulated in previous search processes is reused to warm up the architecture search for new tasks. However, existing TNAS methods still search in an extensive search space, necessitating the evaluation of numerous architectures. To overcome this challenge, this work proposes a novel transfer paradigm, i.e., design principle transfer. In this work, the linguistic description of various structural components' effects on architectural performance is termed design principles. They are learned from established architectures and then can be reused to reduce the search space by discarding unpromising architectures. Searching in the refined search space can boost both the search performance and efficiency for new NAS tasks. To this end, a large language model (LLM)-assisted design principle transfer (LAPT) framework is devised. In LAPT, LLM is applied to automatically reason the design principles from a set of given architectures, and then a principle adaptation method is applied to refine these principles progressively based on the new search results. Experimental results show that LAPT can beat the state-of-the-art TNAS methods on most tasks and achieve comparable performance on others.
Understanding the Importance of Evolutionary Search in Automated Heuristic Design with Large Language Models
Jul 15, 2024



Automated heuristic design (AHD) has gained considerable attention for its potential to automate the development of effective heuristics. The recent advent of large language models (LLMs) has paved a new avenue for AHD, with initial efforts focusing on framing AHD as an evolutionary program search (EPS) problem. However, inconsistent benchmark settings, inadequate baselines, and a lack of detailed component analysis have left the necessity of integrating LLMs with search strategies and the true progress achieved by existing LLM-based EPS methods to be inadequately justified. This work seeks to fulfill these research queries by conducting a large-scale benchmark comprising four LLM-based EPS methods and four AHD problems across nine LLMs and five independent runs. Our extensive experiments yield meaningful insights, providing empirical grounding for the importance of evolutionary search in LLM-based AHD approaches, while also contributing to the advancement of future EPS algorithmic development. To foster accessibility and reproducibility, we have fully open-sourced our benchmark and corresponding results.
Rethinking Unsupervised Outlier Detection via Multiple Thresholding
Jul 07, 2024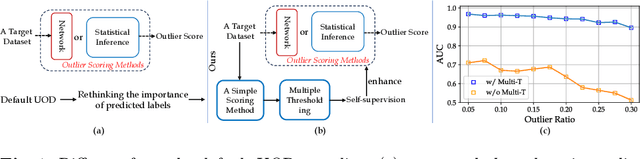

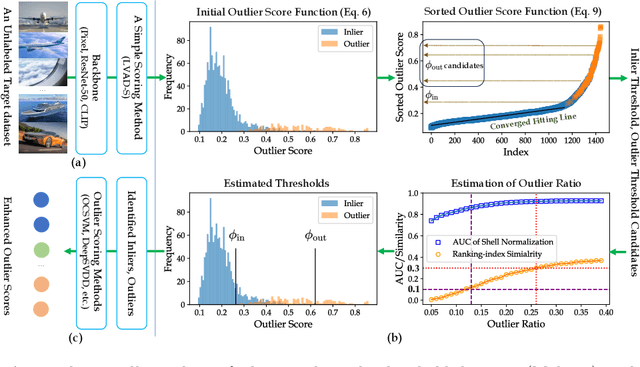

In the realm of unsupervised image outlier detection, assigning outlier scores holds greater significance than its subsequent task: thresholding for predicting labels. This is because determining the optimal threshold on non-separable outlier score functions is an ill-posed problem. However, the lack of predicted labels not only hiders some real applications of current outlier detectors but also causes these methods not to be enhanced by leveraging the dataset's self-supervision. To advance existing scoring methods, we propose a multiple thresholding (Multi-T) module. It generates two thresholds that isolate inliers and outliers from the unlabelled target dataset, whereas outliers are employed to obtain better feature representation while inliers provide an uncontaminated manifold. Extensive experiments verify that Multi-T can significantly improve proposed outlier scoring methods. Moreover, Multi-T contributes to a naive distance-based method being state-of-the-art.
Evolutionary Spiking Neural Networks: A Survey
Jun 18, 2024Spiking neural networks (SNNs) are gaining increasing attention as potential computationally efficient alternatives to traditional artificial neural networks(ANNs). However, the unique information propagation mechanisms and the complexity of SNN neuron models pose challenges for adopting traditional methods developed for ANNs to SNNs. These challenges include both weight learning and architecture design. While surrogate gradient learning has shown some success in addressing the former challenge, the latter remains relatively unexplored. Recently, a novel paradigm utilizing evolutionary computation methods has emerged to tackle these challenges. This approach has resulted in the development of a variety of energy-efficient and high-performance SNNs across a wide range of machine learning benchmarks. In this paper, we present a survey of these works and initiate discussions on potential challenges ahead.
AnomalyXFusion: Multi-modal Anomaly Synthesis with Diffusion
May 02, 2024Anomaly synthesis is one of the effective methods to augment abnormal samples for training. However, current anomaly synthesis methods predominantly rely on texture information as input, which limits the fidelity of synthesized abnormal samples. Because texture information is insufficient to correctly depict the pattern of anomalies, especially for logical anomalies. To surmount this obstacle, we present the AnomalyXFusion framework, designed to harness multi-modality information to enhance the quality of synthesized abnormal samples. The AnomalyXFusion framework comprises two distinct yet synergistic modules: the Multi-modal In-Fusion (MIF) module and the Dynamic Dif-Fusion (DDF) module. The MIF module refines modality alignment by aggregating and integrating various modality features into a unified embedding space, termed X-embedding, which includes image, text, and mask features. Concurrently, the DDF module facilitates controlled generation through an adaptive adjustment of X-embedding conditioned on the diffusion steps. In addition, to reveal the multi-modality representational power of AnomalyXFusion, we propose a new dataset, called MVTec Caption. More precisely, MVTec Caption extends 2.2k accurate image-mask-text annotations for the MVTec AD and LOCO datasets. Comprehensive evaluations demonstrate the effectiveness of AnomalyXFusion, especially regarding the fidelity and diversity for logical anomalies. Project page: http:github.com/hujiecpp/MVTec-Caption
ShadowMaskFormer: Mask Augmented Patch Embeddings for Shadow Removal
Apr 30, 2024



Transformer recently emerged as the de facto model for computer vision tasks and has also been successfully applied to shadow removal. However, these existing methods heavily rely on intricate modifications to the attention mechanisms within the transformer blocks while using a generic patch embedding. As a result, it often leads to complex architectural designs requiring additional computation resources. In this work, we aim to explore the efficacy of incorporating shadow information within the early processing stage. Accordingly, we propose a transformer-based framework with a novel patch embedding that is tailored for shadow removal, dubbed ShadowMaskFormer. Specifically, we present a simple and effective mask-augmented patch embedding to integrate shadow information and promote the model's emphasis on acquiring knowledge for shadow regions. Extensive experiments conducted on the ISTD, ISTD+, and SRD benchmark datasets demonstrate the efficacy of our method against state-of-the-art approaches while using fewer model parameters.
A Multi-objective Optimization Benchmark Test Suite for Real-time Semantic Segmentation
Apr 29, 2024



As one of the emerging challenges in Automated Machine Learning, the Hardware-aware Neural Architecture Search (HW-NAS) tasks can be treated as black-box multi-objective optimization problems (MOPs). An important application of HW-NAS is real-time semantic segmentation, which plays a pivotal role in autonomous driving scenarios. The HW-NAS for real-time semantic segmentation inherently needs to balance multiple optimization objectives, including model accuracy, inference speed, and hardware-specific considerations. Despite its importance, benchmarks have yet to be developed to frame such a challenging task as multi-objective optimization. To bridge the gap, we introduce a tailored streamline to transform the task of HW-NAS for real-time semantic segmentation into standard MOPs. Building upon the streamline, we present a benchmark test suite, CitySeg/MOP, comprising fifteen MOPs derived from the Cityscapes dataset. The CitySeg/MOP test suite is integrated into the EvoXBench platform to provide seamless interfaces with various programming languages (e.g., Python and MATLAB) for instant fitness evaluations. We comprehensively assessed the CitySeg/MOP test suite on various multi-objective evolutionary algorithms, showcasing its versatility and practicality. Source codes are available at https://github.com/EMI-Group/evoxbench.