 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHST: Hierarchical Swin Transformer for Compressed Image Super-resolution
Aug 21, 2022

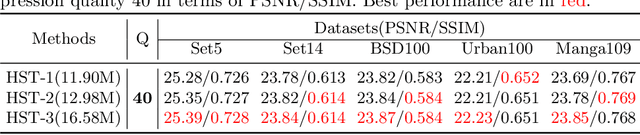
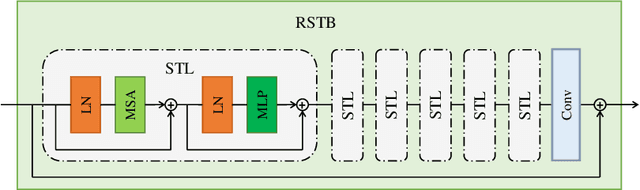
Compressed Image Super-resolution has achieved great attention in recent years, where images are degraded with compression artifacts and low-resolution artifacts. Since the complex hybrid distortions, it is hard to restore the distorted image with the simple cooperation of super-resolution and compression artifacts removing. In this paper, we take a step forward to propose the Hierarchical Swin Transformer (HST) network to restore the low-resolution compressed image, which jointly captures the hierarchical feature representations and enhances each-scale representation with Swin transformer, respectively. Moreover, we find that the pretraining with Super-resolution (SR) task is vital in compressed image super-resolution. To explore the effects of different SR pretraining, we take the commonly-used SR tasks (e.g., bicubic and different real super-resolution simulations) as our pretraining tasks, and reveal that SR plays an irreplaceable role in the compressed image super-resolution. With the cooperation of HST and pre-training, our HST achieves the fifth place in AIM 2022 challenge on the low-quality compressed image super-resolution track, with the PSNR of 23.51dB. Extensive experiments and ablation studies have validated the effectiveness of our proposed methods.
StyleAM: Perception-Oriented Unsupervised Domain Adaption for Non-reference Image Quality Assessment
Jul 29, 2022
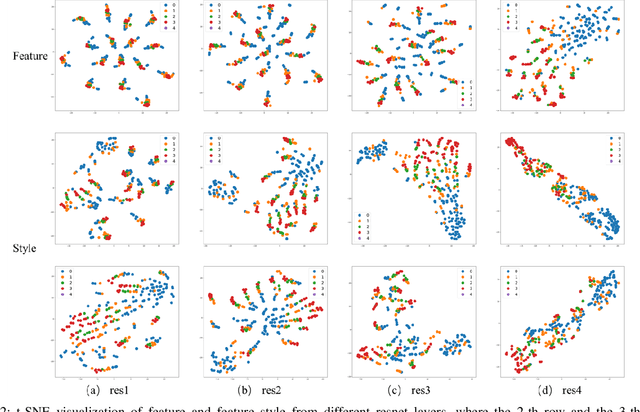
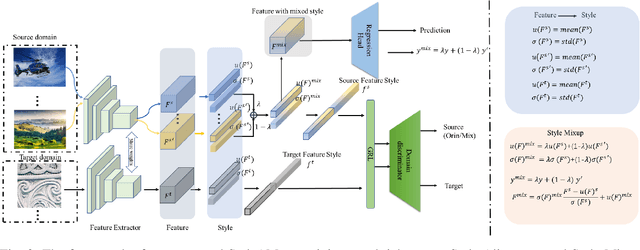
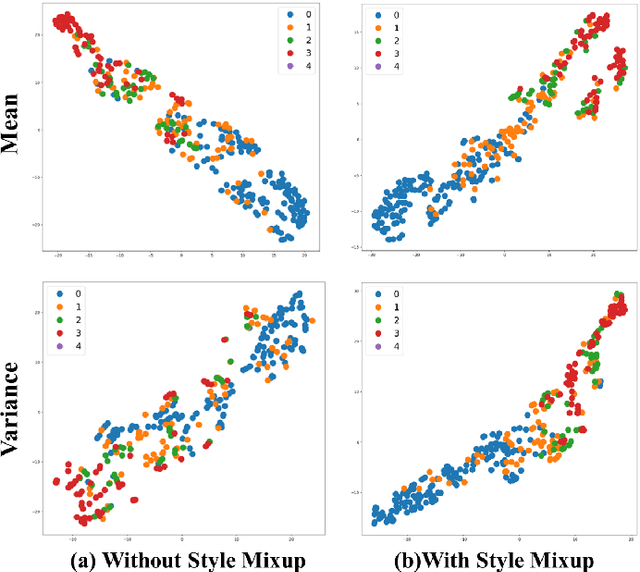
Deep neural networks (DNNs) have shown great potential in non-reference image quality assessment (NR-IQA). However, the annotation of NR-IQA is labor-intensive and time-consuming, which severely limits their application especially for authentic images. To relieve the dependence on quality annotation, some works have applied unsupervised domain adaptation (UDA) to NR-IQA. However, the above methods ignore that the alignment space used in classification is sub-optimal, since the space is not elaborately designed for perception. To solve this challenge, we propose an effective perception-oriented unsupervised domain adaptation method StyleAM for NR-IQA, which transfers sufficient knowledge from label-rich source domain data to label-free target domain images via Style Alignment and Mixup. Specifically, we find a more compact and reliable space i.e., feature style space for perception-oriented UDA based on an interesting/amazing observation, that the feature style (i.e., the mean and variance) of the deep layer in DNNs is exactly associated with the quality score in NR-IQA. Therefore, we propose to align the source and target domains in a more perceptual-oriented space i.e., the feature style space, to reduce the intervention from other quality-irrelevant feature factors. Furthermore, to increase the consistency between quality score and its feature style, we also propose a novel feature augmentation strategy Style Mixup, which mixes the feature styles (i.e., the mean and variance) before the last layer of DNNs together with mixing their labels. Extensive experimental results on two typical cross-domain settings (i.e., synthetic to authentic, and multiple distortions to one distortion) have demonstrated the effectiveness of our proposed StyleAM on NR-IQA.
Source-free Unsupervised Domain Adaptation for Blind Image Quality Assessment
Jul 17, 2022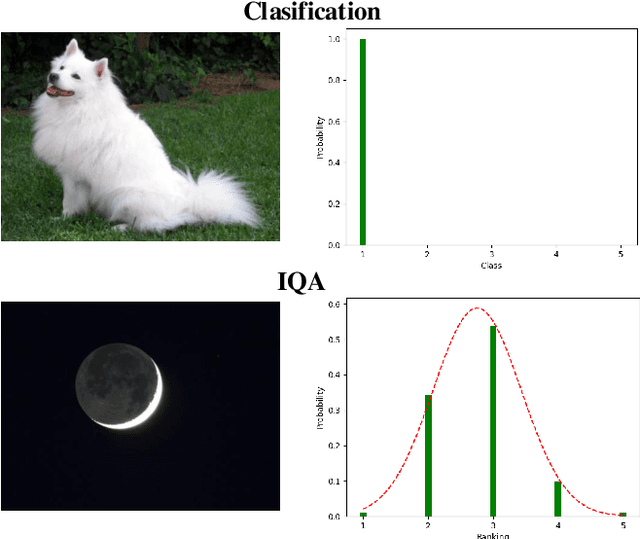
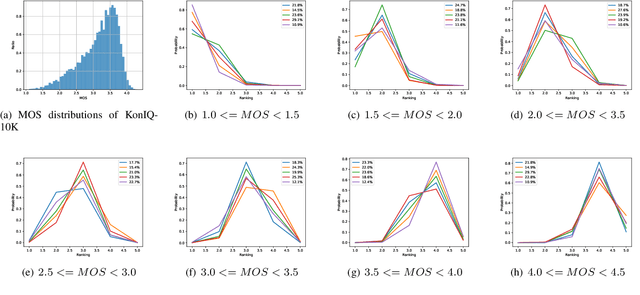
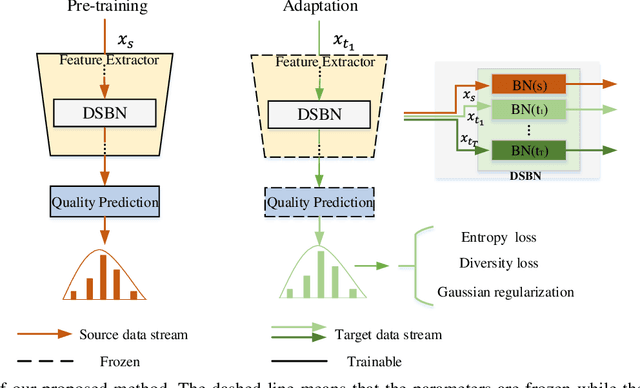
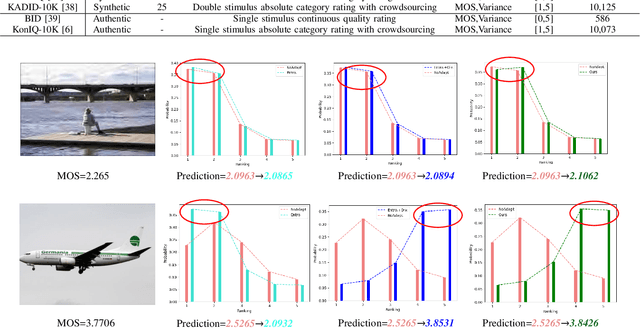
Existing learning-based methods for blind image quality assessment (BIQA) are heavily dependent on large amounts of annotated training data, and usually suffer from a severe performance degradation when encountering the domain/distribution shift problem. Thanks to the development of unsupervised domain adaptation (UDA), some works attempt to transfer the knowledge from a label-sufficient source domain to a label-free target domain under domain shift with UDA. However, it requires the coexistence of source and target data, which might be impractical for source data due to the privacy or storage issues. In this paper, we take the first step towards the source-free unsupervised domain adaptation (SFUDA) in a simple yet efficient manner for BIQA to tackle the domain shift without access to the source data. Specifically, we cast the quality assessment task as a rating distribution prediction problem. Based on the intrinsic properties of BIQA, we present a group of well-designed self-supervised objectives to guide the adaptation of the BN affine parameters towards the target domain. Among them, minimizing the prediction entropy and maximizing the batch prediction diversity aim to encourage more confident results while avoiding the trivial solution. Besides, based on the observation that the IQA rating distribution of single image follows the Gaussian distribution, we apply Gaussian regularization to the predicted rating distribution to make it more consistent with the nature of human scoring. Extensive experimental results under cross-domain scenarios demonstrated the effectiveness of our proposed method to mitigate the domain shift.
RTN: Reinforced Transformer Network for Coronary CT Angiography Vessel-level Image Quality Assessment
Jul 13, 2022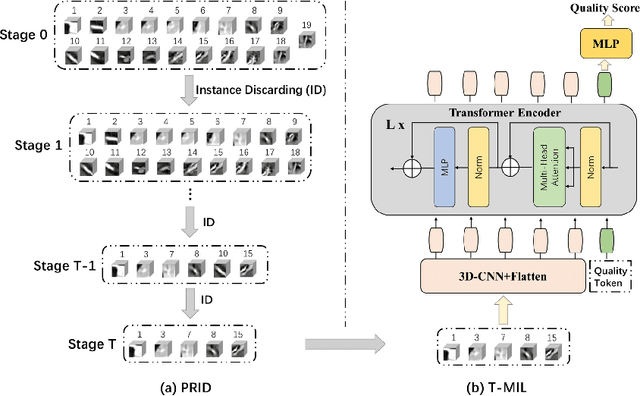
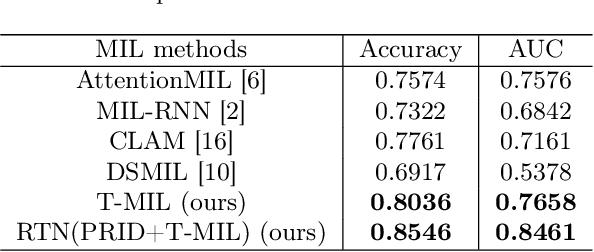


Coronary CT Angiography (CCTA) is susceptible to various distortions (e.g., artifacts and noise), which severely compromise the exact diagnosis of cardiovascular diseases. The appropriate CCTA Vessel-level Image Quality Assessment (CCTA VIQA) algorithm can be used to reduce the risk of error diagnosis. The primary challenges of CCTA VIQA are that the local part of coronary that determines final quality is hard to locate. To tackle the challenge, we formulate CCTA VIQA as a multiple-instance learning (MIL) problem, and exploit Transformer-based MIL backbone (termed as T-MIL) to aggregate the multiple instances along the coronary centerline into the final quality. However, not all instances are informative for final quality. There are some quality-irrelevant/negative instances intervening the exact quality assessment(e.g., instances covering only background or the coronary in instances is not identifiable). Therefore, we propose a Progressive Reinforcement learning based Instance Discarding module (termed as PRID) to progressively remove quality-irrelevant/negative instances for CCTA VIQA. Based on the above two modules, we propose a Reinforced Transformer Network (RTN) for automatic CCTA VIQA based on end-to-end optimization. Extensive experimental results demonstrate that our proposed method achieves the state-of-the-art performance on the real-world CCTA dataset, exceeding previous MIL methods by a large margin.
Image Coding for Machines with Omnipotent Feature Learning
Jul 07, 2022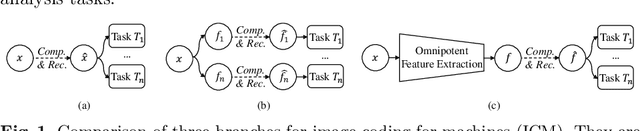


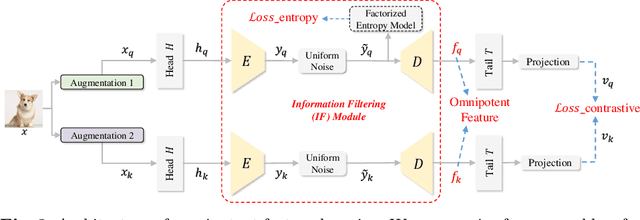
Image Coding for Machines (ICM) aims to compress images for AI tasks analysis rather than meeting human perception. Learning a kind of feature that is both general (for AI tasks) and compact (for compression) is pivotal for its success. In this paper, we attempt to develop an ICM framework by learning universal features while also considering compression. We name such features as omnipotent features and the corresponding framework as Omni-ICM. Considering self-supervised learning (SSL) improves feature generalization, we integrate it with the compression task into the Omni-ICM framework to learn omnipotent features. However, it is non-trivial to coordinate semantics modeling in SSL and redundancy removing in compression, so we design a novel information filtering (IF) module between them by co-optimization of instance distinguishment and entropy minimization to adaptively drop information that is weakly related to AI tasks (e.g., some texture redundancy). Different from previous task-specific solutions, Omni-ICM could directly support AI tasks analysis based on the learned omnipotent features without joint training or extra transformation. Albeit simple and intuitive, Omni-ICM significantly outperforms existing traditional and learning-based codecs on multiple fundamental vision tasks.
SwinIQA: Learned Swin Distance for Compressed Image Quality Assessment
May 09, 2022
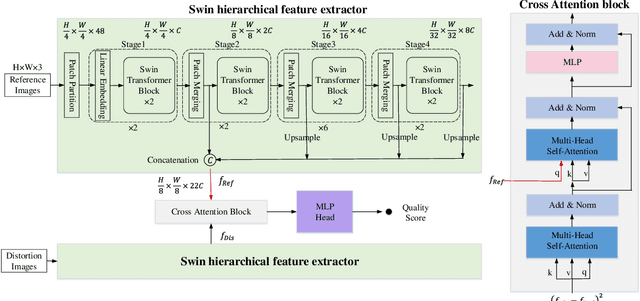
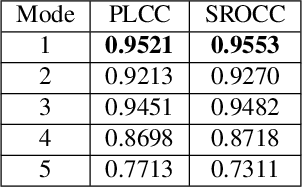
Image compression has raised widespread interest recently due to its significant importance for multimedia storage and transmission. Meanwhile, a reliable image quality assessment (IQA) for compressed images can not only help to verify the performance of various compression algorithms but also help to guide the compression optimization in turn. In this paper, we design a full-reference image quality assessment metric SwinIQA to measure the perceptual quality of compressed images in a learned Swin distance space. It is known that the compression artifacts are usually non-uniformly distributed with diverse distortion types and degrees. To warp the compressed images into the shared representation space while maintaining the complex distortion information, we extract the hierarchical feature representations from each stage of the Swin Transformer. Besides, we utilize cross attention operation to map the extracted feature representations into a learned Swin distance space. Experimental results show that the proposed metric achieves higher consistency with human's perceptual judgment compared with both traditional methods and learning-based methods on CLIC datasets.
Deep Frequency Filtering for Domain Generalization
Mar 23, 2022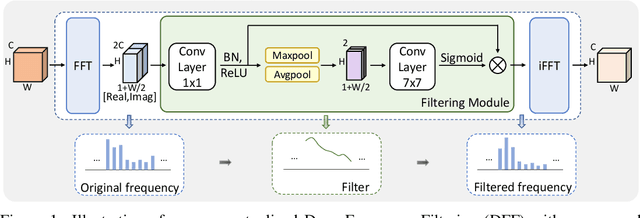
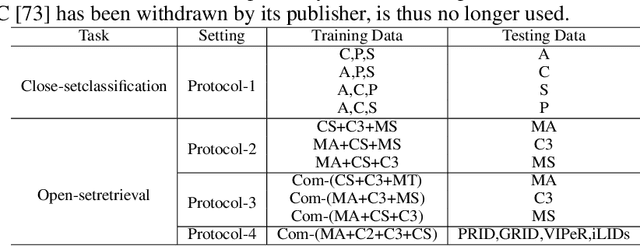
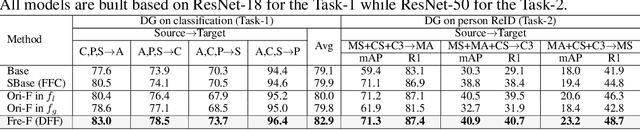

Improving the generalization capability of Deep Neural Networks (DNNs) is critical for their practical uses, which has been a longstanding challenge. Some theoretical studies have revealed that DNNs have preferences to different frequency components in the learning process and indicated that this may affect the robustness of learned features. In this paper, we propose Deep Frequency Filtering (DFF) for learning domain-generalizable features, which is the first endeavour to explicitly modulate frequency components of different transfer difficulties across domains during training. To achieve this, we perform Fast Fourier Transform (FFT) on feature maps at different layers, then adopt a light-weight module to learn the attention masks from frequency representations after FFT to enhance transferable frequency components while suppressing the components not conductive to generalization. Further, we empirically compare different types of attention for implementing our conceptualized DFF. Extensive experiments demonstrate the effectiveness of the proposed DFF and show that applying DFF on a plain baseline outperforms the state-of-the-art methods on different domain generalization tasks, including close-set classification and open-set retrieval.
ActiveMLP: An MLP-like Architecture with Active Token Mixer
Mar 11, 2022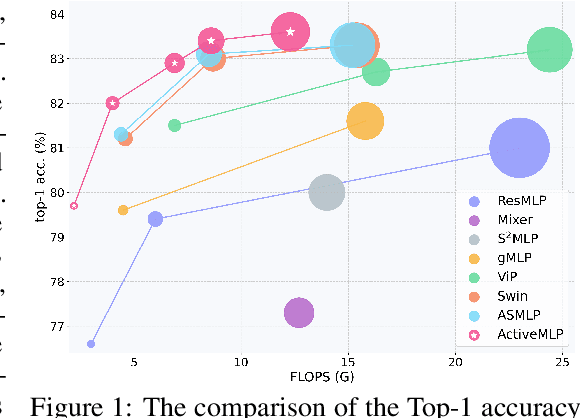

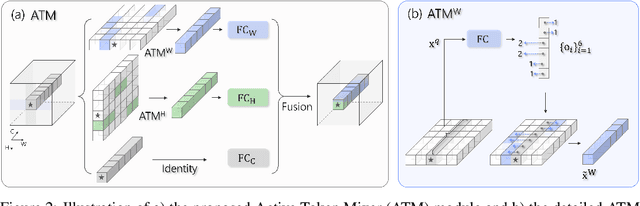
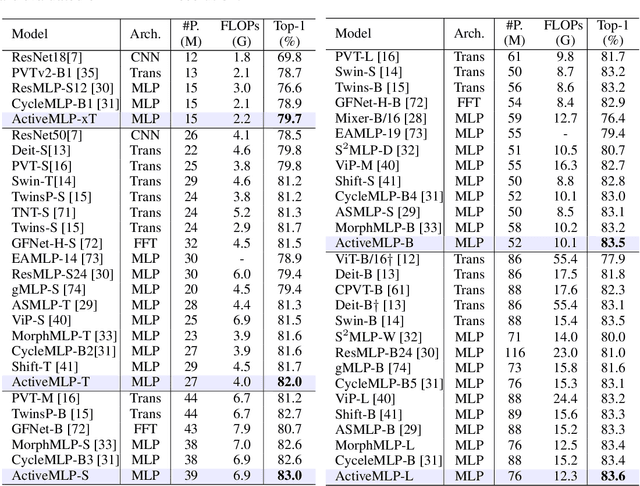
This paper presents ActiveMLP, a general MLP-like backbone for computer vision. The three existing dominant network families, i.e., CNNs, Transformers and MLPs, differ from each other mainly in the ways to fuse contextual information into a given token, leaving the design of more effective token-mixing mechanisms at the core of backbone architecture development. In ActiveMLP, we propose an innovative token-mixer, dubbed Active Token Mixer (ATM), to actively incorporate contextual information from other tokens in the global scope into the given one. This fundamental operator actively predicts where to capture useful contexts and learns how to fuse the captured contexts with the original information of the given token at channel levels. In this way, the spatial range of token-mixing is expanded and the way of token-mixing is reformed. With this design, ActiveMLP is endowed with the merits of global receptive fields and more flexible content-adaptive information fusion. Extensive experiments demonstrate that ActiveMLP is generally applicable and comprehensively surpasses different families of SOTA vision backbones by a clear margin on a broad range of vision tasks, including visual recognition and dense prediction tasks. The code and models will be available at https://github.com/microsoft/ActiveMLP.
Mask-based Latent Reconstruction for Reinforcement Learning
Jan 28, 2022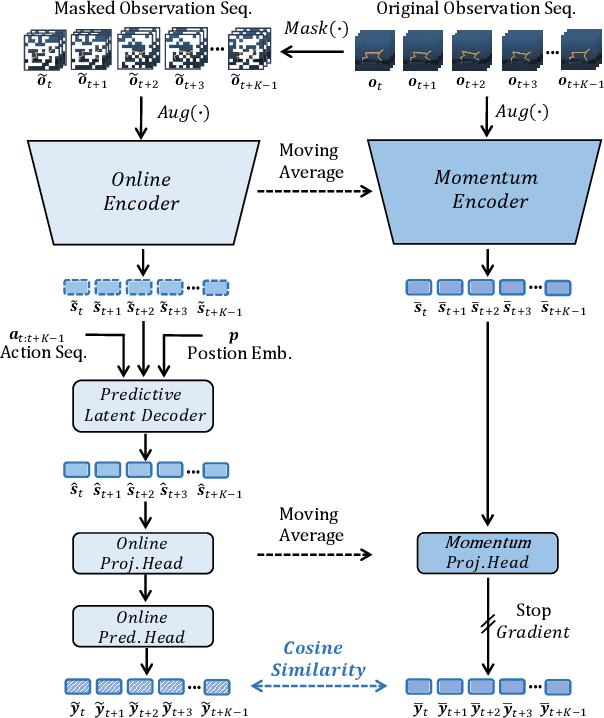
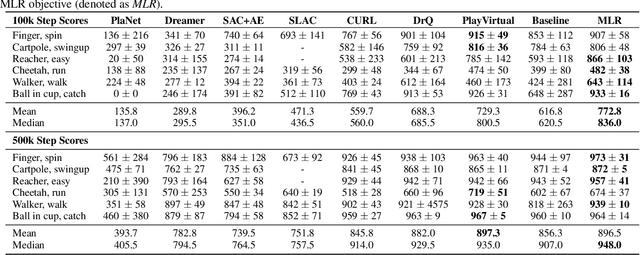
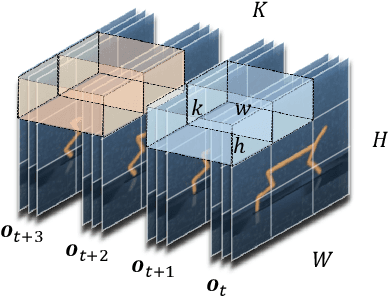
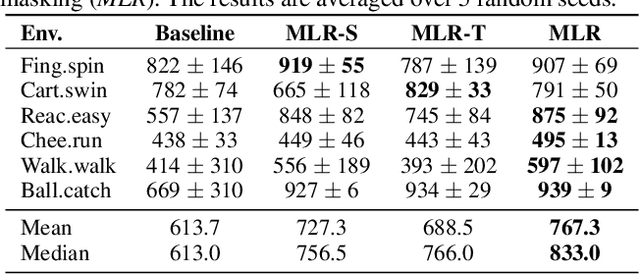
For deep reinforcement learning (RL) from pixels, learning effective state representations is crucial for achieving high performance. However, in practice, limited experience and high-dimensional input prevent effective representation learning. To address this, motivated by the success of masked modeling in other research fields, we introduce mask-based reconstruction to promote state representation learning in RL. Specifically, we propose a simple yet effective self-supervised method, Mask-based Latent Reconstruction (MLR), to predict the complete state representations in the latent space from the observations with spatially and temporally masked pixels. MLR enables the better use of context information when learning state representations to make them more informative, which facilitates RL agent training. Extensive experiments show that our MLR significantly improves the sample efficiency in RL and outperforms the state-of-the-art sample-efficient RL methods on multiple continuous benchmark environments.
Semantically Video Coding: Instill Static-Dynamic Clues into Structured Bitstream for AI Tasks
Jan 25, 2022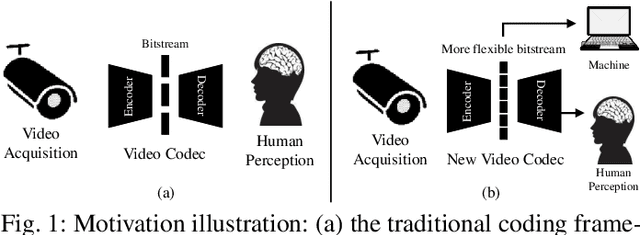
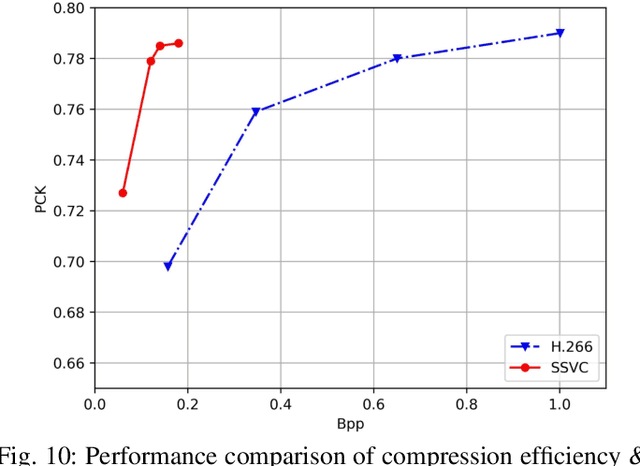
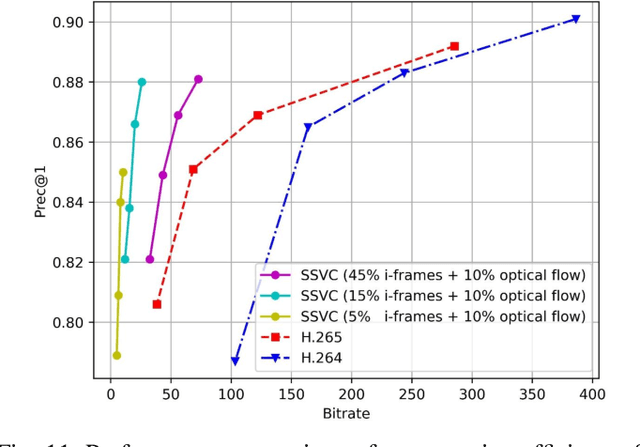
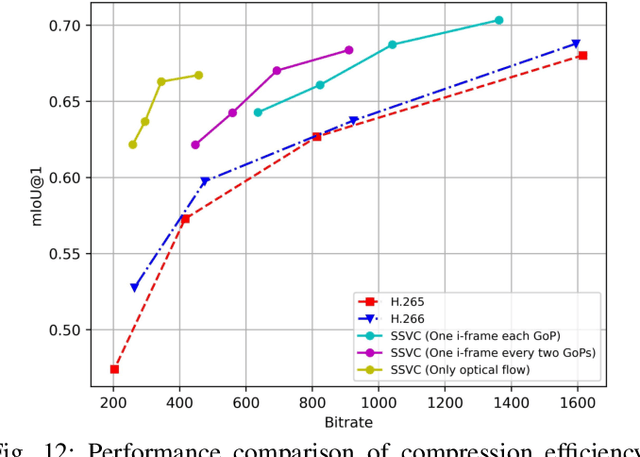
Traditional media coding schemes typically encode image/video into a semantic-unknown binary stream, which fails to directly support downstream intelligent tasks at the bitstream level. Semantically Structured Image Coding (SSIC) framework makes the first attempt to enable decoding-free or partial-decoding image intelligent task analysis via a Semantically Structured Bitstream (SSB). However, the SSIC only considers image coding and its generated SSB only contains the static object information. In this paper, we extend the idea of semantically structured coding from video coding perspective and propose an advanced Semantically Structured Video Coding (SSVC) framework to support heterogeneous intelligent applications. Video signals contain more rich dynamic motion information and exist more redundancy due to the similarity between adjacent frames. Thus, we present a reformulation of semantically structured bitstream (SSB) in SSVC which contains both static object characteristics and dynamic motion clues. Specifically, we introduce optical flow to encode continuous motion information and reduce cross-frame redundancy via a predictive coding architecture, then the optical flow and residual information are reorganized into SSB, which enables the proposed SSVC could better adaptively support video-based downstream intelligent applications. Extensive experiments demonstrate that the proposed SSVC framework could directly support multiple intelligent tasks just depending on a partially decoded bitstream. This avoids the full bitstream decompression and thus significantly saves bitrate/bandwidth consumption for intelligent analytics. We verify this point on the tasks of image object detection, pose estimation, video action recognition, video object segmentation, etc.