 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSME: ReRAM-based Sparse-Multiplication-Engine to Squeeze-Out Bit Sparsity of Neural Network
Mar 02, 2021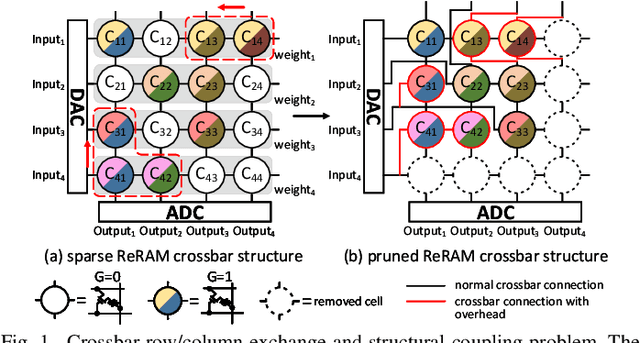
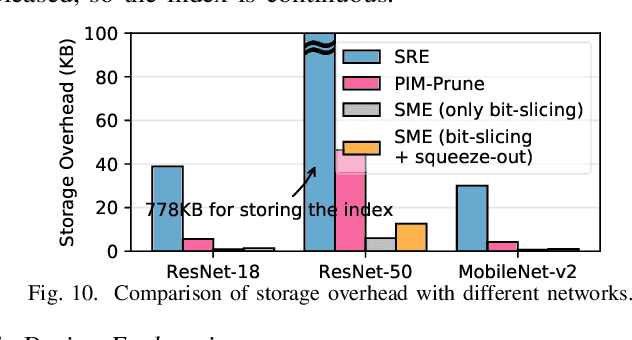
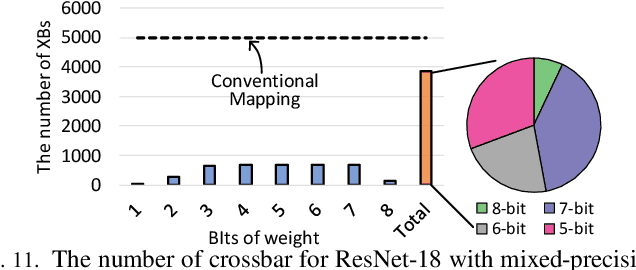
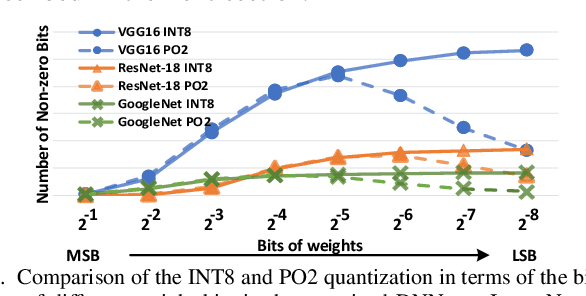
Resistive Random-Access-Memory (ReRAM) crossbar is a promising technique for deep neural network (DNN) accelerators, thanks to its in-memory and in-situ analog computing abilities for Vector-Matrix Multiplication-and-Accumulations (VMMs). However, it is challenging for crossbar architecture to exploit the sparsity in the DNN. It inevitably causes complex and costly control to exploit fine-grained sparsity due to the limitation of tightly-coupled crossbar structure. As the countermeasure, we developed a novel ReRAM-based DNN accelerator, named Sparse-Multiplication-Engine (SME), based on a hardware and software co-design framework. First, we orchestrate the bit-sparse pattern to increase the density of bit-sparsity based on existing quantization methods. Second, we propose a novel weigh mapping mechanism to slice the bits of a weight across the crossbars and splice the activation results in peripheral circuits. This mechanism can decouple the tightly-coupled crossbar structure and cumulate the sparsity in the crossbar. Finally, a superior squeeze-out scheme empties the crossbars mapped with highly-sparse non-zeros from the previous two steps. We design the SME architecture and discuss its use for other quantization methods and different ReRAM cell technologies. Compared with prior state-of-the-art designs, the SME shrinks the use of crossbars up to 8.7x and 2.1x using Resent-50 and MobileNet-v2, respectively, with less than 0.3% accuracy drop on ImageNet.
RADAR: Run-time Adversarial Weight Attack Detection and Accuracy Recovery
Jan 20, 2021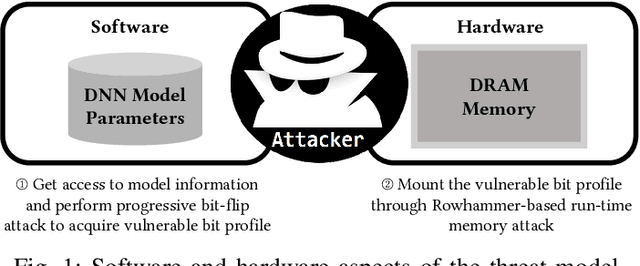
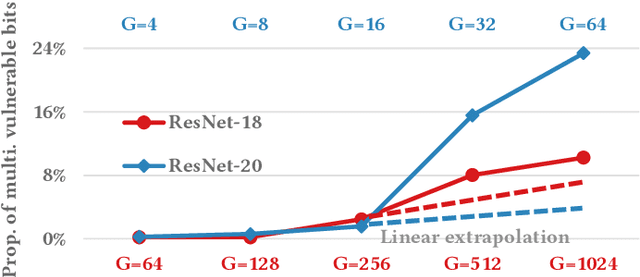
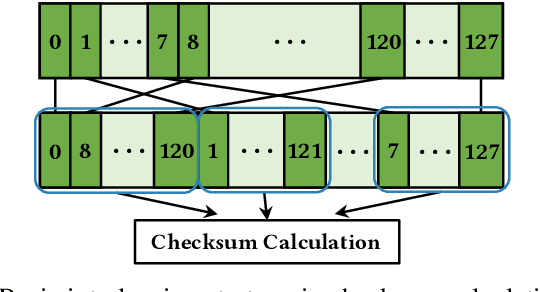
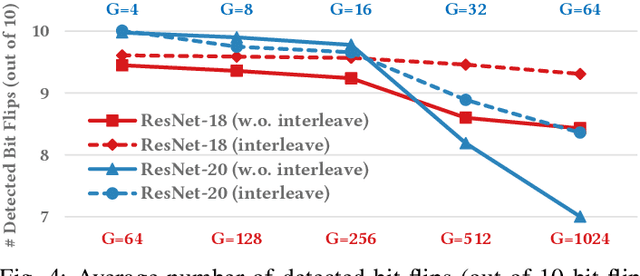
Adversarial attacks on Neural Network weights, such as the progressive bit-flip attack (PBFA), can cause a catastrophic degradation in accuracy by flipping a very small number of bits. Furthermore, PBFA can be conducted at run time on the weights stored in DRAM main memory. In this work, we propose RADAR, a Run-time adversarial weight Attack Detection and Accuracy Recovery scheme to protect DNN weights against PBFA. We organize weights that are interspersed in a layer into groups and employ a checksum-based algorithm on weights to derive a 2-bit signature for each group. At run time, the 2-bit signature is computed and compared with the securely stored golden signature to detect the bit-flip attacks in a group. After successful detection, we zero out all the weights in a group to mitigate the accuracy drop caused by malicious bit-flips. The proposed scheme is embedded in the inference computation stage. For the ResNet-18 ImageNet model, our method can detect 9.6 bit-flips out of 10 on average. For this model, the proposed accuracy recovery scheme can restore the accuracy from below 1% caused by 10 bit flips to above 69%. The proposed method has extremely low time and storage overhead. System-level simulation on gem5 shows that RADAR only adds <1% to the inference time, making this scheme highly suitable for run-time attack detection and mitigation.
MetaGater: Fast Learning of Conditional Channel Gated Networks via Federated Meta-Learning
Nov 28, 2020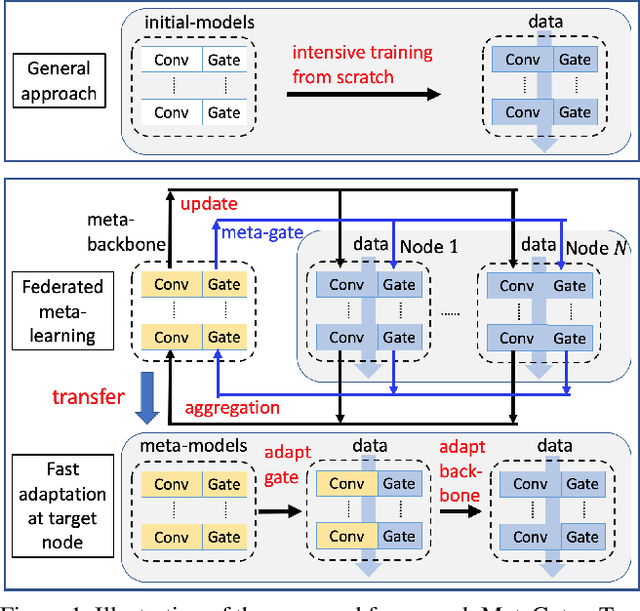
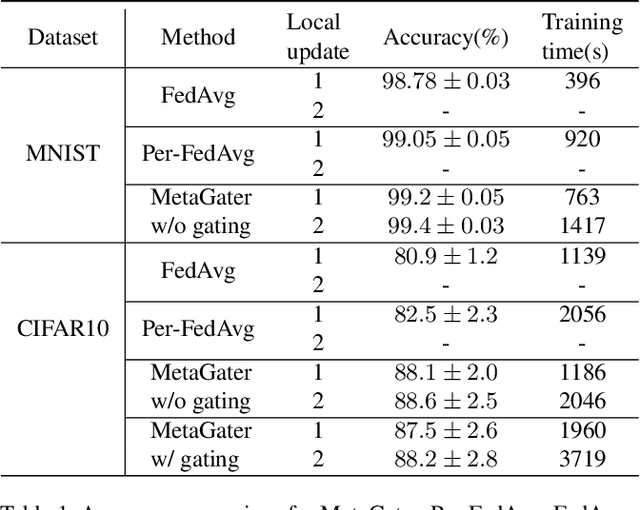
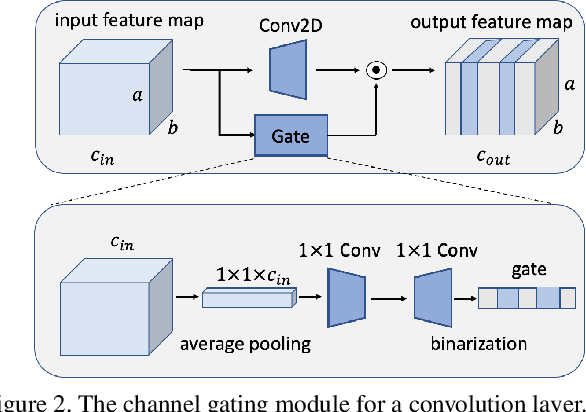

While deep learning has achieved phenomenal successes in many AI applications, its enormous model size and intensive computation requirements pose a formidable challenge to the deployment in resource-limited nodes. There has recently been an increasing interest in computationally-efficient learning methods, e.g., quantization, pruning and channel gating. However, most existing techniques cannot adapt to different tasks quickly. In this work, we advocate a holistic approach to jointly train the backbone network and the channel gating which enables dynamical selection of a subset of filters for more efficient local computation given the data input. Particularly, we develop a federated meta-learning approach to jointly learn good meta-initializations for both backbone networks and gating modules, by making use of the model similarity across learning tasks on different nodes. In this way, the learnt meta-gating module effectively captures the important filters of a good meta-backbone network, based on which a task-specific conditional channel gated network can be quickly adapted, i.e., through one-step gradient descent, from the meta-initializations in a two-stage procedure using new samples of that task. The convergence of the proposed federated meta-learning algorithm is established under mild conditions. Experimental results corroborate the effectiveness of our method in comparison to related work.
A Progressive Sub-Network Searching Framework for Dynamic Inference
Sep 11, 2020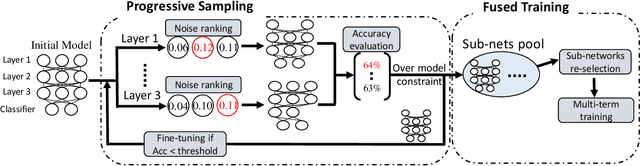
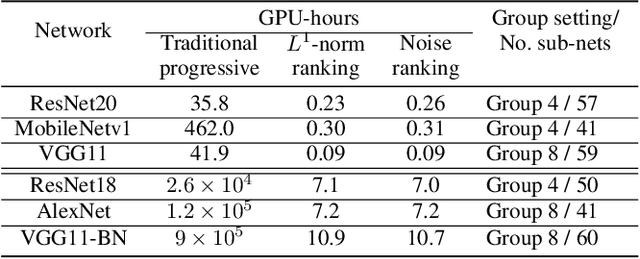
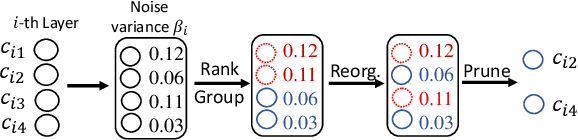
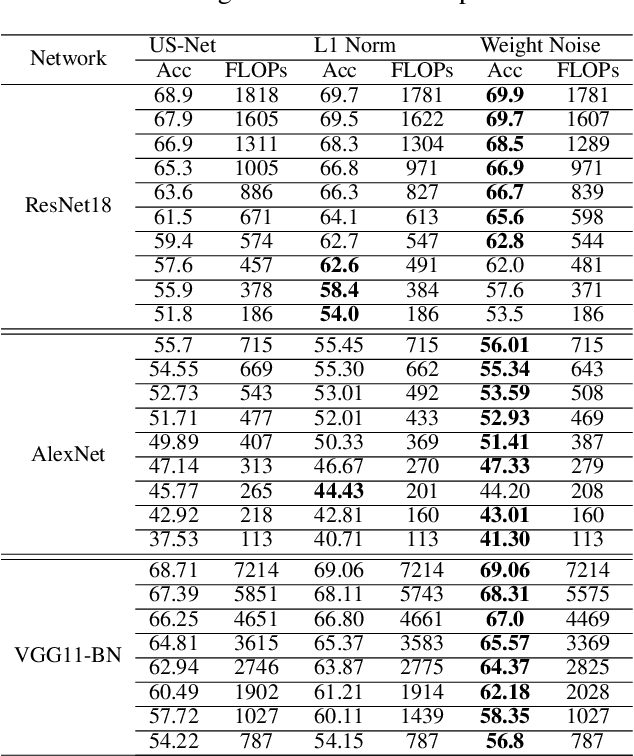
Many techniques have been developed, such as model compression, to make Deep Neural Networks (DNNs) inference more efficiently. Nevertheless, DNNs still lack excellent run-time dynamic inference capability to enable users trade-off accuracy and computation complexity (i.e., latency on target hardware) after model deployment, based on dynamic requirements and environments. Such research direction recently draws great attention, where one realization is to train the target DNN through a multiple-term objective function, which consists of cross-entropy terms from multiple sub-nets. Our investigation in this work show that the performance of dynamic inference highly relies on the quality of sub-net sampling. With objective to construct a dynamic DNN and search multiple high quality sub-nets with minimal searching cost, we propose a progressive sub-net searching framework, which is embedded with several effective techniques, including trainable noise ranking, channel group and fine-tuning threshold setting, sub-nets re-selection. The proposed framework empowers the target DNN with better dynamic inference capability, which outperforms prior works on both CIFAR-10 and ImageNet dataset via comprehensive experiments on different network structures. Taken ResNet18 as an example, our proposed method achieves much better dynamic inference accuracy compared with prior popular Universally-Slimmable-Network by 4.4%-maximally and 2.3%-averagely in ImageNet dataset with the same model size.
KSM: Fast Multiple Task Adaption via Kernel-wise Soft Mask Learning
Sep 11, 2020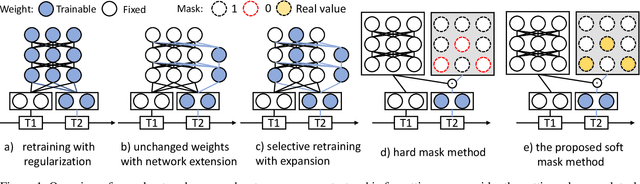

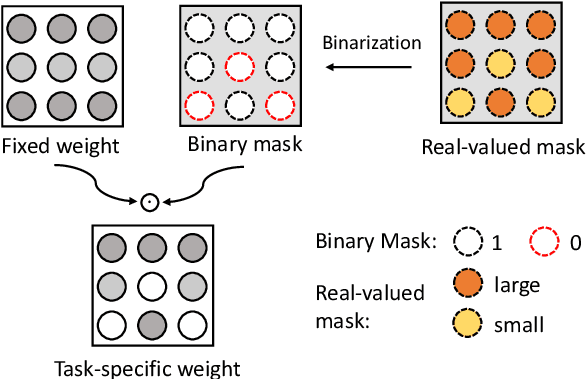
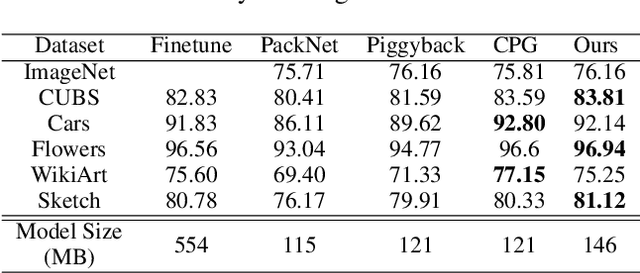
Deep Neural Networks (DNN) could forget the knowledge about earlier tasks when learning new tasks, and this is known as \textit{catastrophic forgetting}. While recent continual learning methods are capable of alleviating the catastrophic problem on toy-sized datasets, some issues still remain to be tackled when applying them in real-world problems. Recently, the fast mask-based learning method (e.g. piggyback \cite{mallya2018piggyback}) is proposed to address these issues by learning only a binary element-wise mask in a fast manner, while keeping the backbone model fixed. However, the binary mask has limited modeling capacity for new tasks. A more recent work \cite{hung2019compacting} proposes a compress-grow-based method (CPG) to achieve better accuracy for new tasks by partially training backbone model, but with order-higher training cost, which makes it infeasible to be deployed into popular state-of-the-art edge-/mobile-learning. The primary goal of this work is to simultaneously achieve fast and high-accuracy multi task adaption in continual learning setting. Thus motivated, we propose a new training method called \textit{kernel-wise Soft Mask} (KSM), which learns a kernel-wise hybrid binary and real-value soft mask for each task, while using the same backbone model. Such a soft mask can be viewed as a superposition of a binary mask and a properly scaled real-value tensor, which offers a richer representation capability without low-level kernel support to meet the objective of low hardware overhead. We validate KSM on multiple benchmark datasets against recent state-of-the-art methods (e.g. Piggyback, Packnet, CPG, etc.), which shows good improvement in both accuracy and training cost.
T-BFA: Targeted Bit-Flip Adversarial Weight Attack
Jul 24, 2020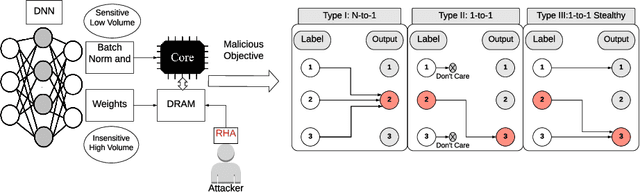
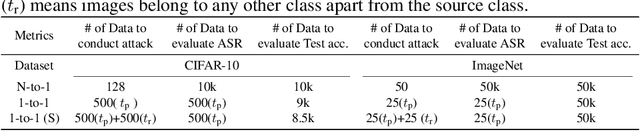
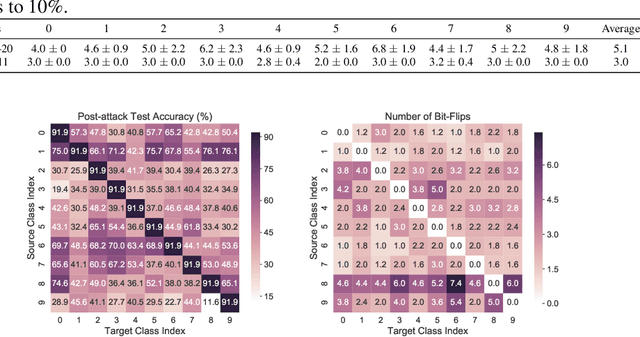

Deep Neural Network (DNN) attacks have mostly been conducted through adversarial input example generation. Recent work on adversarial attack of DNNweights, especially, Bit-Flip based adversarial weight Attack (BFA) has proved to be very powerful. BFA is an un-targeted attack that can classify all inputs into a random output class by flipping a very small number of weight bits stored in computer memory. This paper presents the first work on targeted adversarial weight attack for quantized DNN models. Specifically, we propose Targeted variants of BFA (T-BFA), which can intentionally mislead selected inputs to a target output class. The objective is achieved by identifying the weight bits that are highly associated with the classification of a targeted output through a novel class-dependant weight bit ranking algorithm. T-BFA performance has been successfully demonstrated on multiple network architectures for the image classification task. For example, by merely flipping 27 (out of 88 million) weight bits, T-BFA can misclassify all the images in Ibex class into Proboscis Monkey class (i.e., 100% attack success rate) on ImageNet dataset, while maintaining 59.35% validation accuracy on ResNet-18.
TBT: Targeted Neural Network Attack with Bit Trojan
Sep 10, 2019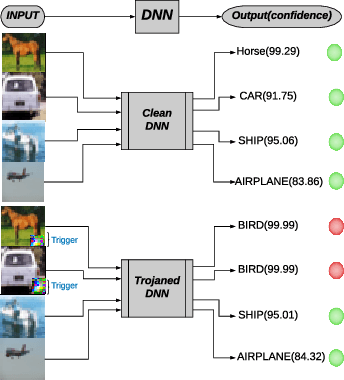
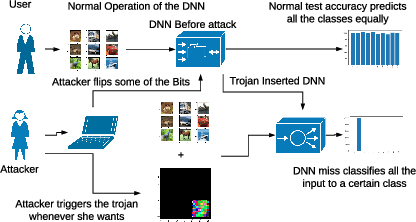
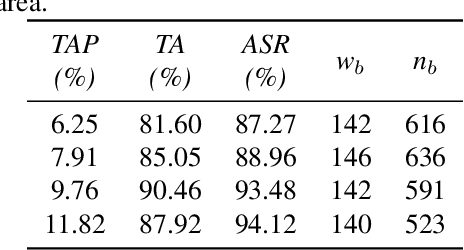
Security of modern Deep Neural Networks (DNNs) is under severe scrutiny as the deployment of these models become widespread in many intelligence-based applications. Most recently, DNNs are attacked through Trojan which can effectively infect the model during the training phase and get activated only through specific input patterns (i.e, trigger) during inference. However, in this work, for the first time, we propose a novel Targeted Bit Trojan(TBT), which eliminates the need for model re-training to insert the targeted Trojan. Our algorithm efficiently generates a trigger specifically designed to locate certain vulnerable bits of DNN weights stored in main memory (i.e., DRAM). The objective is that once the attacker flips these vulnerable bits, the network still operates with normal inference accuracy. However, when the attacker activates the trigger embedded with input images, the network classifies all the inputs to a certain target class. We demonstrate that flipping only several vulnerable bits founded by our method, using available bit-flip techniques (i.e, row-hammer), can transform a fully functional DNN model into a Trojan infected model. We perform extensive experiments of CIFAR-10, SVHN and ImageNet datasets on both VGG-16 and Resnet-18 architectures. Our proposed TBT could classify 93% of the test images to a target class with as little as 82 bit-flips out of 88 million weight bits on Resnet-18 for CIFAR10 dataset.
Non-structured DNN Weight Pruning Considered Harmful
Jul 03, 2019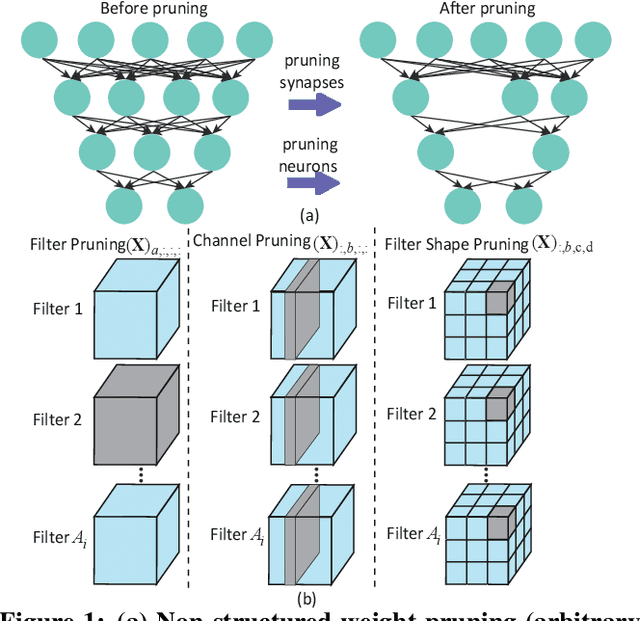
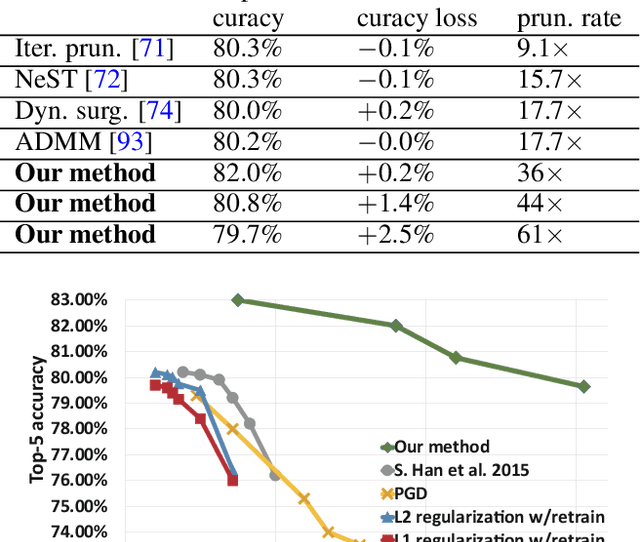
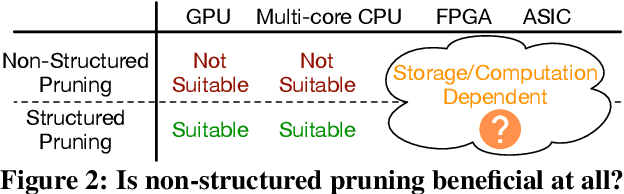
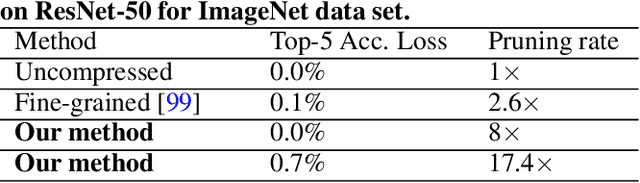
Large deep neural network (DNN) models pose the key challenge to energy efficiency due to the significantly higher energy consumption of off-chip DRAM accesses than arithmetic or SRAM operations. It motivates the intensive research on model compression with two main approaches. Weight pruning leverages the redundancy in the number of weights and can be performed in a non-structured, which has higher flexibility and pruning rate but incurs index accesses due to irregular weights, or structured manner, which preserves the full matrix structure with lower pruning rate. Weight quantization leverages the redundancy in the number of bits in weights. Compared to pruning, quantization is much more hardware-friendly, and has become a "must-do" step for FPGA and ASIC implementations. This paper provides a definitive answer to the question for the first time. First, we build ADMM-NN-S by extending and enhancing ADMM-NN, a recently proposed joint weight pruning and quantization framework. Second, we develop a methodology for fair and fundamental comparison of non-structured and structured pruning in terms of both storage and computation efficiency. Our results show that ADMM-NN-S consistently outperforms the prior art: (i) it achieves 348x, 36x, and 8x overall weight pruning on LeNet-5, AlexNet, and ResNet-50, respectively, with (almost) zero accuracy loss; (ii) we demonstrate the first fully binarized (for all layers) DNNs can be lossless in accuracy in many cases. These results provide a strong baseline and credibility of our study. Based on the proposed comparison framework, with the same accuracy and quantization, the results show that non-structrued pruning is not competitive in terms of both storage and computation efficiency. Thus, we conclude that non-structured pruning is considered harmful. We urge the community not to continue the DNN inference acceleration for non-structured sparsity.
Robust Sparse Regularization: Simultaneously Optimizing Neural Network Robustness and Compactness
May 30, 2019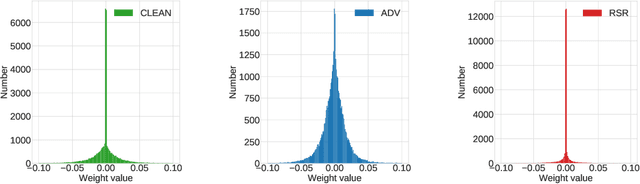
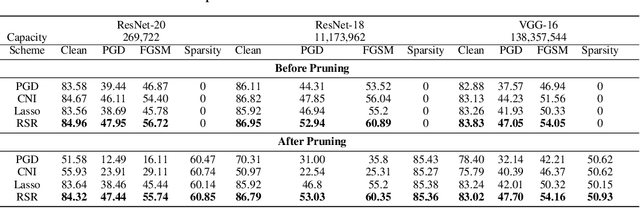
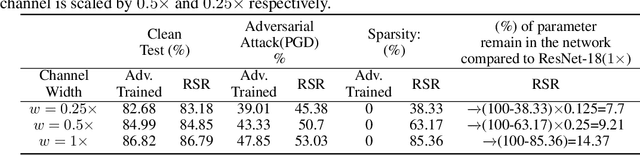
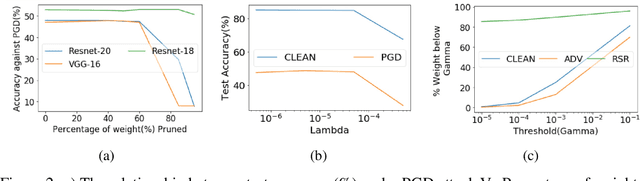
Deep Neural Network (DNN) trained by the gradient descent method is known to be vulnerable to maliciously perturbed adversarial input, aka. adversarial attack. As one of the countermeasures against adversarial attack, increasing the model capacity for DNN robustness enhancement was discussed and reported as an effective approach by many recent works. In this work, we show that shrinking the model size through proper weight pruning can even be helpful to improve the DNN robustness under adversarial attack. For obtaining a simultaneously robust and compact DNN model, we propose a multi-objective training method called Robust Sparse Regularization (RSR), through the fusion of various regularization techniques, including channel-wise noise injection, lasso weight penalty, and adversarial training. We conduct extensive experiments across popular ResNet-20, ResNet-18 and VGG-16 DNN architectures to demonstrate the effectiveness of RSR against popular white-box (i.e., PGD and FGSM) and black-box attacks. Thanks to RSR, 85% weight connections of ResNet-18 can be pruned while still achieving 0.68% and 8.72% improvement in clean- and perturbed-data accuracy respectively on CIFAR-10 dataset, in comparison to its PGD adversarial training baseline.
Bit-Flip Attack: Crushing Neural Network with Progressive Bit Search
Apr 07, 2019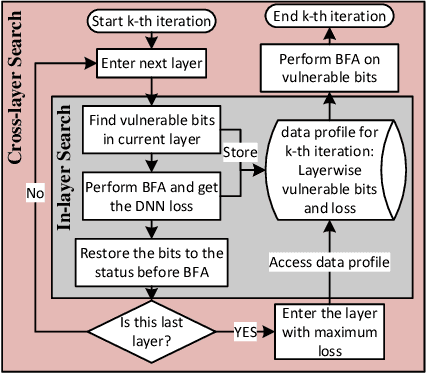
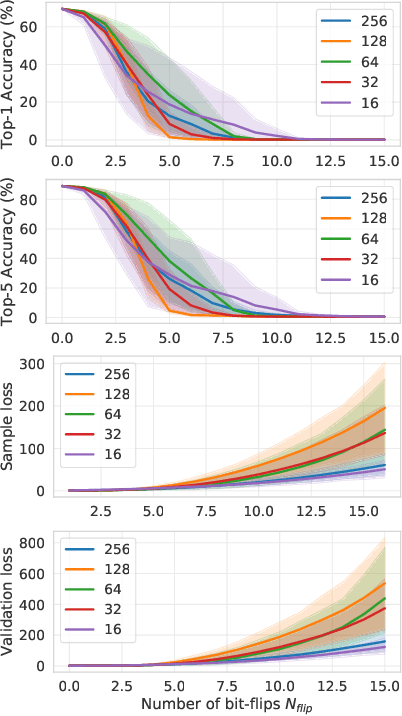
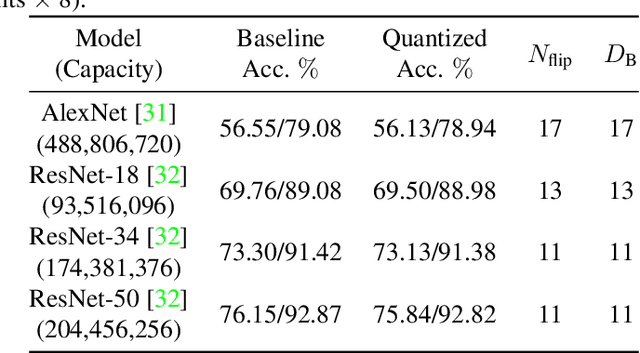
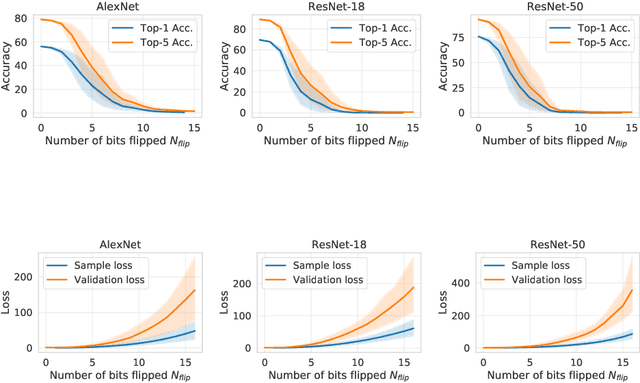
Several important security issues of Deep Neural Network (DNN) have been raised recently associated with different applications and components. The most widely investigated security concern of DNN is from its malicious input, a.k.a adversarial example. Nevertheless, the security challenge of DNN's parameters is not well explored yet. In this work, we are the first to propose a novel DNN weight attack methodology called Bit-Flip Attack (BFA) which can crush a neural network through maliciously flipping extremely small amount of bits within its weight storage memory system (i.e., DRAM). The bit-flip operations could be conducted through well-known Row-Hammer attack, while our main contribution is to develop an algorithm to identify the most vulnerable bits of DNN weight parameters (stored in memory as binary bits), that could maximize the accuracy degradation with a minimum number of bit-flips. Our proposed BFA utilizes a Progressive Bit Search (PBS) method which combines gradient ranking and progressive search to identify the most vulnerable bit to be flipped. With the aid of PBS, we can successfully attack a ResNet-18 fully malfunction (i.e., top-1 accuracy degrade from 69.8% to 0.1%) only through 13 bit-flips out of 93 million bits, while randomly flipping 100 bits merely degrades the accuracy by less than 1%.