 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecQuant: Spectral Decomposition and Adaptive Truncation for Ultra-Low-Bit LLMs Quantization
Nov 11, 2025



The emergence of accurate open large language models (LLMs) has sparked a push for advanced quantization techniques to enable efficient deployment on end-user devices. In this paper, we revisit the challenge of extreme LLM compression -- targeting ultra-low-bit quantization for both activations and weights -- from a Fourier frequency domain perspective. We propose SpecQuant, a two-stage framework that tackles activation outliers and cross-channel variance. In the first stage, activation outliers are smoothed and transferred into the weight matrix to simplify downstream quantization. In the second stage, we apply channel-wise low-frequency Fourier truncation to suppress high-frequency components while preserving essential signal energy, improving quantization robustness. Our method builds on the principle that most of the weight energy is concentrated in low-frequency components, which can be retained with minimal impact on model accuracy. To enable runtime adaptability, we introduce a lightweight truncation module during inference that adjusts truncation thresholds based on channel characteristics. On LLaMA-3 8B, SpecQuant achieves 4-bit quantization for both weights and activations, narrowing the zero-shot accuracy gap to only 1.5% compared to full precision, while delivering 2 times faster inference and 3times lower memory usage.
QUARK: Quantization-Enabled Circuit Sharing for Transformer Acceleration by Exploiting Common Patterns in Nonlinear Operations
Nov 10, 2025Transformer-based models have revolutionized computer vision (CV) and natural language processing (NLP) by achieving state-of-the-art performance across a range of benchmarks. However, nonlinear operations in models significantly contribute to inference latency, presenting unique challenges for efficient hardware acceleration. To this end, we propose QUARK, a quantization-enabled FPGA acceleration framework that leverages common patterns in nonlinear operations to enable efficient circuit sharing, thereby reducing hardware resource requirements. QUARK targets all nonlinear operations within Transformer-based models, achieving high-performance approximation through a novel circuit-sharing design tailored to accelerate these operations. Our evaluation demonstrates that QUARK significantly reduces the computational overhead of nonlinear operators in mainstream Transformer architectures, achieving up to a 1.96 times end-to-end speedup over GPU implementations. Moreover, QUARK lowers the hardware overhead of nonlinear modules by more than 50% compared to prior approaches, all while maintaining high model accuracy -- and even substantially boosting accuracy under ultra-low-bit quantization.
SME: ReRAM-based Sparse-Multiplication-Engine to Squeeze-Out Bit Sparsity of Neural Network
Mar 02, 2021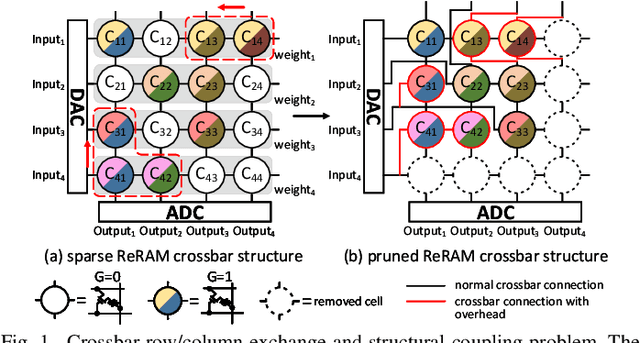
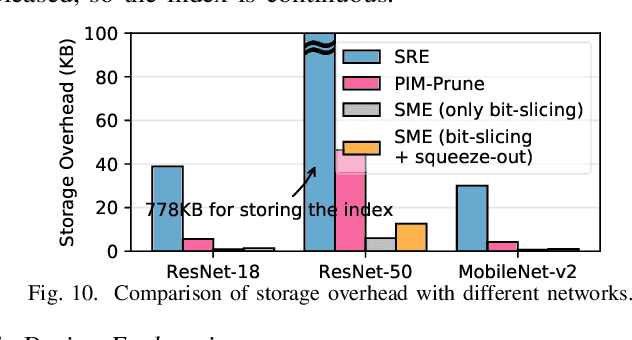
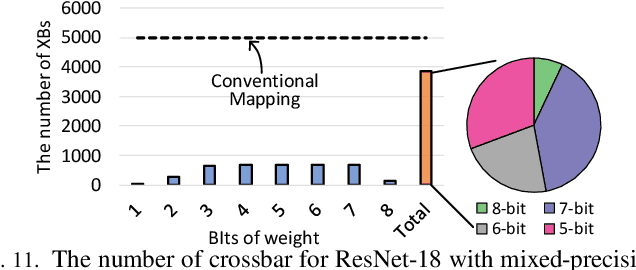
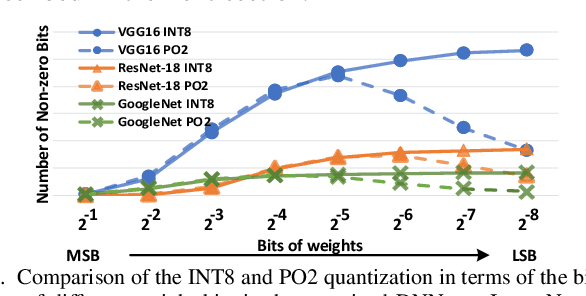
Resistive Random-Access-Memory (ReRAM) crossbar is a promising technique for deep neural network (DNN) accelerators, thanks to its in-memory and in-situ analog computing abilities for Vector-Matrix Multiplication-and-Accumulations (VMMs). However, it is challenging for crossbar architecture to exploit the sparsity in the DNN. It inevitably causes complex and costly control to exploit fine-grained sparsity due to the limitation of tightly-coupled crossbar structure. As the countermeasure, we developed a novel ReRAM-based DNN accelerator, named Sparse-Multiplication-Engine (SME), based on a hardware and software co-design framework. First, we orchestrate the bit-sparse pattern to increase the density of bit-sparsity based on existing quantization methods. Second, we propose a novel weigh mapping mechanism to slice the bits of a weight across the crossbars and splice the activation results in peripheral circuits. This mechanism can decouple the tightly-coupled crossbar structure and cumulate the sparsity in the crossbar. Finally, a superior squeeze-out scheme empties the crossbars mapped with highly-sparse non-zeros from the previous two steps. We design the SME architecture and discuss its use for other quantization methods and different ReRAM cell technologies. Compared with prior state-of-the-art designs, the SME shrinks the use of crossbars up to 8.7x and 2.1x using Resent-50 and MobileNet-v2, respectively, with less than 0.3% accuracy drop on ImageNet.