 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Assistant to Double Agent: Formalizing and Benchmarking Attacks on OpenClaw for Personalized Local AI Agent
Feb 09, 2026Although large language model (LLM)-based agents, exemplified by OpenClaw, are increasingly evolving from task-oriented systems into personalized AI assistants for solving complex real-world tasks, their practical deployment also introduces severe security risks. However, existing agent security research and evaluation frameworks primarily focus on synthetic or task-centric settings, and thus fail to accurately capture the attack surface and risk propagation mechanisms of personalized agents in real-world deployments. To address this gap, we propose Personalized Agent Security Bench (PASB), an end-to-end security evaluation framework tailored for real-world personalized agents. Building upon existing agent attack paradigms, PASB incorporates personalized usage scenarios, realistic toolchains, and long-horizon interactions, enabling black-box, end-to-end security evaluation on real systems. Using OpenClaw as a representative case study, we systematically evaluate its security across multiple personalized scenarios, tool capabilities, and attack types. Our results indicate that OpenClaw exhibits critical vulnerabilities at different execution stages, including user prompt processing, tool usage, and memory retrieval, highlighting substantial security risks in personalized agent deployments. The code for the proposed PASB framework is available at https://github.com/AstorYH/PASB.
MLLM Machine Unlearning via Visual Knowledge Distillation
Dec 12, 2025Recently, machine unlearning approaches have been proposed to remove sensitive information from well-trained large models. However, most existing methods are tailored for LLMs, while MLLM-oriented unlearning remains at its early stage. Inspired by recent studies exploring the internal mechanisms of MLLMs, we propose to disentangle the visual and textual knowledge embedded within MLLMs and introduce a dedicated approach to selectively erase target visual knowledge while preserving textual knowledge. Unlike previous unlearning methods that rely on output-level supervision, our approach introduces a Visual Knowledge Distillation (VKD) scheme, which leverages intermediate visual representations within the MLLM as supervision signals. This design substantially enhances both unlearning effectiveness and model utility. Moreover, since our method only fine-tunes the visual components of the MLLM, it offers significant efficiency advantages. Extensive experiments demonstrate that our approach outperforms state-of-the-art unlearning methods in terms of both effectiveness and efficiency. Moreover, we are the first to evaluate the robustness of MLLM unlearning against relearning attacks.
A Review of Machine Learning for Cavitation Intensity Recognition in Complex Industrial Systems
Nov 19, 2025Cavitation intensity recognition (CIR) is a critical technology for detecting and evaluating cavitation phenomena in hydraulic machinery, with significant implications for operational safety, performance optimization, and maintenance cost reduction in complex industrial systems. Despite substantial research progress, a comprehensive review that systematically traces the development trajectory and provides explicit guidance for future research is still lacking. To bridge this gap, this paper presents a thorough review and analysis of hundreds of publications on intelligent CIR across various types of mechanical equipment from 2002 to 2025, summarizing its technological evolution and offering insights for future development. The early stages are dominated by traditional machine learning approaches that relied on manually engineered features under the guidance of domain expert knowledge. The advent of deep learning has driven the development of end-to-end models capable of automatically extracting features from multi-source signals, thereby significantly improving recognition performance and robustness. Recently, physical informed diagnostic models have been proposed to embed domain knowledge into deep learning models, which can enhance interpretability and cross-condition generalization. In the future, transfer learning, multi-modal fusion, lightweight network architectures, and the deployment of industrial agents are expected to propel CIR technology into a new stage, addressing challenges in multi-source data acquisition, standardized evaluation, and industrial implementation. The paper aims to systematically outline the evolution of CIR technology and highlight the emerging trend of integrating deep learning with physical knowledge. This provides a significant reference for researchers and practitioners in the field of intelligent cavitation diagnosis in complex industrial systems.
Towards Aligned Data Forgetting via Twin Machine Unlearning
Jan 15, 2025Modern privacy regulations have spurred the evolution of machine unlearning, a technique enabling a trained model to efficiently forget specific training data. In prior unlearning methods, the concept of "data forgetting" is often interpreted and implemented as achieving zero classification accuracy on such data. Nevertheless, the authentic aim of machine unlearning is to achieve alignment between the unlearned model and the gold model, i.e., encouraging them to have identical classification accuracy. On the other hand, the gold model often exhibits non-zero classification accuracy due to its generalization ability. To achieve aligned data forgetting, we propose a Twin Machine Unlearning (TMU) approach, where a twin unlearning problem is defined corresponding to the original unlearning problem. Consequently, the generalization-label predictor trained on the twin problem can be transferred to the original problem, facilitating aligned data forgetting. Comprehensive empirical experiments illustrate that our approach significantly enhances the alignment between the unlearned model and the gold model.
Towards Aligned Data Removal via Twin Machine Unlearning
Aug 21, 2024



Modern privacy regulations have spurred the evolution of machine unlearning, a technique that enables the removal of data from an already trained ML model without requiring retraining from scratch. Previous unlearning methods tend to induce the model to achieve lowest classification accuracy on the removal data. Nonetheless, the authentic objective of machine unlearning is to align the unlearned model with the gold model, i.e., achieving the same classification accuracy as the gold model. For this purpose, we present a Twin Machine Unlearning (TMU) approach, where a twin unlearning problem is defined corresponding to the original unlearning problem. As a results, the generalization-label predictor trained on the twin problem can be transferred to the original problem, facilitating aligned data removal. Comprehensive empirical experiments illustrate that our approach significantly enhances the alignment between the unlearned model and the gold model. Meanwhile, our method allows data removal without compromising the model accuracy.
Interpreting and Mitigating Hallucination in MLLMs through Multi-agent Debate
Jul 30, 2024MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination. Previous methods focus on determining whether a generated output is hallucinated, without identifying which image region leads to the hallucination or interpreting why such hallucinations occur. In this paper, we argue that hallucination in MLLMs is partially due to a lack of slow-thinking and divergent-thinking in these models. To address this, we propose adopting a self-reflection scheme to promote slow-thinking. Furthermore, we consider eliminating hallucination as a complex reasoning task and propose a multi-agent debate approach to encourage divergent-thinking. Consequently, our approach can not only mitigate hallucinations but also interpret why they occur and detail the specifics of hallucination. In addition, we propose to distinguish creativity from hallucination in the context of MLLMs, and illustrate how to evaluate MLLMs' creativity capability. Extensive experiments on various benchmarks demonstrate that our approach exhibits generalized hallucinations-mitigating performance across several MLLMs.
Efficient LLM-Jailbreaking by Introducing Visual Modality
May 30, 2024This paper focuses on jailbreaking attacks against large language models (LLMs), eliciting them to generate objectionable content in response to harmful user queries. Unlike previous LLM-jailbreaks that directly orient to LLMs, our approach begins by constructing a multimodal large language model (MLLM) through the incorporation of a visual module into the target LLM. Subsequently, we conduct an efficient MLLM-jailbreak to generate jailbreaking embeddings embJS. Finally, we convert the embJS into text space to facilitate the jailbreaking of the target LLM. Compared to direct LLM-jailbreaking, our approach is more efficient, as MLLMs are more vulnerable to jailbreaking than pure LLM. Additionally, to improve the attack success rate (ASR) of jailbreaking, we propose an image-text semantic matching scheme to identify a suitable initial input. Extensive experiments demonstrate that our approach surpasses current state-of-the-art methods in terms of both efficiency and effectiveness. Moreover, our approach exhibits superior cross-class jailbreaking capabilities.
Towards Unified Robustness Against Both Backdoor and Adversarial Attacks
May 28, 2024Deep Neural Networks (DNNs) are known to be vulnerable to both backdoor and adversarial attacks. In the literature, these two types of attacks are commonly treated as distinct robustness problems and solved separately, since they belong to training-time and inference-time attacks respectively. However, this paper revealed that there is an intriguing connection between them: (1) planting a backdoor into a model will significantly affect the model's adversarial examples; (2) for an infected model, its adversarial examples have similar features as the triggered images. Based on these observations, a novel Progressive Unified Defense (PUD) algorithm is proposed to defend against backdoor and adversarial attacks simultaneously. Specifically, our PUD has a progressive model purification scheme to jointly erase backdoors and enhance the model's adversarial robustness. At the early stage, the adversarial examples of infected models are utilized to erase backdoors. With the backdoor gradually erased, our model purification can naturally turn into a stage to boost the model's robustness against adversarial attacks. Besides, our PUD algorithm can effectively identify poisoned images, which allows the initial extra dataset not to be completely clean. Extensive experimental results show that, our discovered connection between backdoor and adversarial attacks is ubiquitous, no matter what type of backdoor attack. The proposed PUD outperforms the state-of-the-art backdoor defense, including the model repairing-based and data filtering-based methods. Besides, it also has the ability to compete with the most advanced adversarial defense methods.
Jailbreaking Attack against Multimodal Large Language Model
Feb 04, 2024This paper focuses on jailbreaking attacks against multi-modal large language models (MLLMs), seeking to elicit MLLMs to generate objectionable responses to harmful user queries. A maximum likelihood-based algorithm is proposed to find an \emph{image Jailbreaking Prompt} (imgJP), enabling jailbreaks against MLLMs across multiple unseen prompts and images (i.e., data-universal property). Our approach exhibits strong model-transferability, as the generated imgJP can be transferred to jailbreak various models, including MiniGPT-v2, LLaVA, InstructBLIP, and mPLUG-Owl2, in a black-box manner. Moreover, we reveal a connection between MLLM-jailbreaks and LLM-jailbreaks. As a result, we introduce a construction-based method to harness our approach for LLM-jailbreaks, demonstrating greater efficiency than current state-of-the-art methods. The code is available here. \textbf{Warning: some content generated by language models may be offensive to some readers.}
Semantic-shape Adaptive Feature Modulation for Semantic Image Synthesis
Mar 31, 2022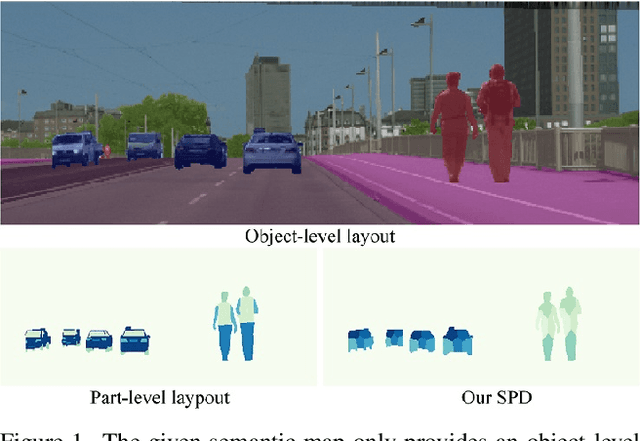
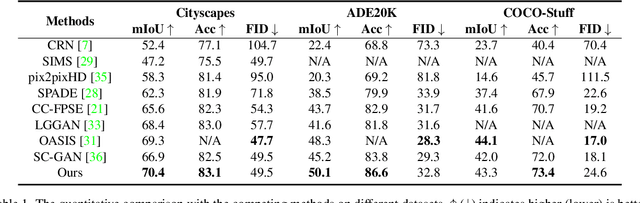
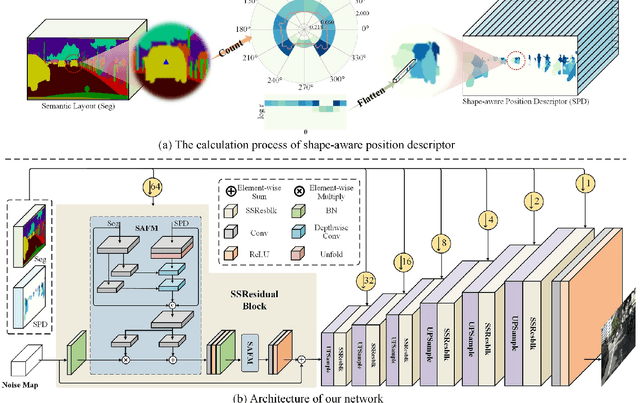
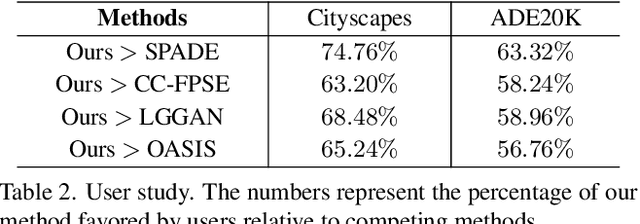
Recent years have witnessed substantial progress in semantic image synthesis, it is still challenging in synthesizing photo-realistic images with rich details. Most previous methods focus on exploiting the given semantic map, which just captures an object-level layout for an image. Obviously, a fine-grained part-level semantic layout will benefit object details generation, and it can be roughly inferred from an object's shape. In order to exploit the part-level layouts, we propose a Shape-aware Position Descriptor (SPD) to describe each pixel's positional feature, where object shape is explicitly encoded into the SPD feature. Furthermore, a Semantic-shape Adaptive Feature Modulation (SAFM) block is proposed to combine the given semantic map and our positional features to produce adaptively modulated features. Extensive experiments demonstrate that the proposed SPD and SAFM significantly improve the generation of objects with rich details. Moreover, our method performs favorably against the SOTA methods in terms of quantitative and qualitative evaluation. The source code and model are available at https://github.com/cszy98/SAFM.