 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Low-Rank Matrix Contextual Bandits with Graph Information
Jul 23, 2025The matrix contextual bandit (CB), as an extension of the well-known multi-armed bandit, is a powerful framework that has been widely applied in sequential decision-making scenarios involving low-rank structure. In many real-world scenarios, such as online advertising and recommender systems, additional graph information often exists beyond the low-rank structure, that is, the similar relationships among users/items can be naturally captured through the connectivity among nodes in the corresponding graphs. However, existing matrix CB methods fail to explore such graph information, and thereby making them difficult to generate effective decision-making policies. To fill in this void, we propose in this paper a novel matrix CB algorithmic framework that builds upon the classical upper confidence bound (UCB) framework. This new framework can effectively integrate both the low-rank structure and graph information in a unified manner. Specifically, it involves first solving a joint nuclear norm and matrix Laplacian regularization problem, followed by the implementation of a graph-based generalized linear version of the UCB algorithm. Rigorous theoretical analysis demonstrates that our procedure outperforms several popular alternatives in terms of cumulative regret bound, owing to the effective utilization of graph information. A series of synthetic and real-world data experiments are conducted to further illustrate the merits of our procedure.
RecurrentGPT: Interactive Generation of (Arbitrarily) Long Text
May 22, 2023



The fixed-size context of Transformer makes GPT models incapable of generating arbitrarily long text. In this paper, we introduce RecurrentGPT, a language-based simulacrum of the recurrence mechanism in RNNs. RecurrentGPT is built upon a large language model (LLM) such as ChatGPT and uses natural language to simulate the Long Short-Term Memory mechanism in an LSTM. At each timestep, RecurrentGPT generates a paragraph of text and updates its language-based long-short term memory stored on the hard drive and the prompt, respectively. This recurrence mechanism enables RecurrentGPT to generate texts of arbitrary length without forgetting. Since human users can easily observe and edit the natural language memories, RecurrentGPT is interpretable and enables interactive generation of long text. RecurrentGPT is an initial step towards next-generation computer-assisted writing systems beyond local editing suggestions. In addition to producing AI-generated content (AIGC), we also demonstrate the possibility of using RecurrentGPT as an interactive fiction that directly interacts with consumers. We call this usage of generative models by ``AI As Contents'' (AIAC), which we believe is the next form of conventional AIGC. We further demonstrate the possibility of using RecurrentGPT to create personalized interactive fiction that directly interacts with readers instead of interacting with writers. More broadly, RecurrentGPT demonstrates the utility of borrowing ideas from popular model designs in cognitive science and deep learning for prompting LLMs. Our code is available at https://github.com/aiwaves-cn/RecurrentGPT and an online demo is available at https://www.aiwaves.org/recurrentgpt.
BOSH: An Efficient Meta Algorithm for Decision-based Attacks
Oct 14, 2019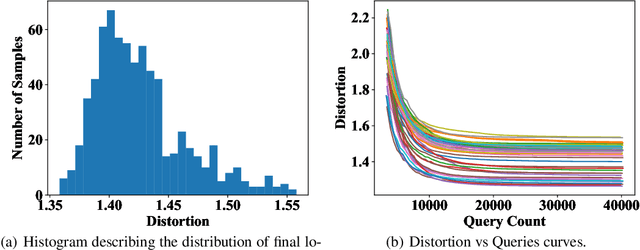
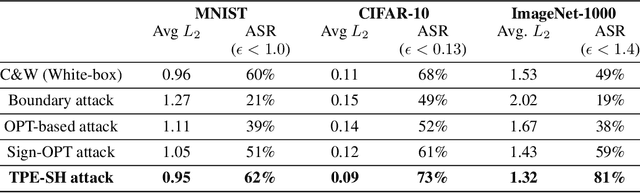
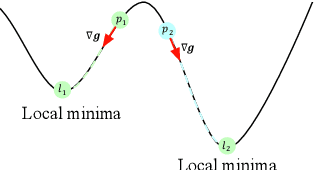
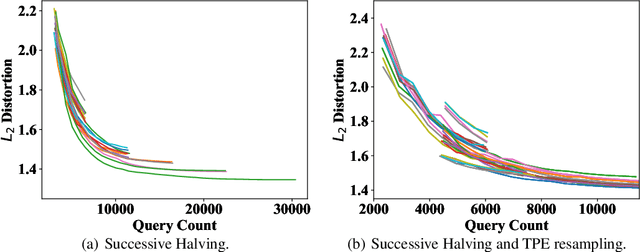
Adversarial example generation becomes a viable method for evaluating the robustness of a machine learning model. In this paper, we consider hard-label black-box attacks (a.k.a. decision-based attacks), which is a challenging setting that generates adversarial examples based on only a series of black-box hard-label queries. This type of attacks can be used to attack discrete and complex models, such as Gradient Boosting Decision Tree (GBDT) and detection-based defense models. Existing decision-based attacks based on iterative local updates often get stuck in a local minimum and fail to generate the optimal adversarial example with the smallest distortion. To remedy this issue, we propose an efficient meta algorithm called BOSH-attack, which tremendously improves existing algorithms through Bayesian Optimization (BO) and Successive Halving (SH). In particular, instead of traversing a single solution path when searching an adversarial example, we maintain a pool of solution paths to explore important regions. We show empirically that the proposed algorithm converges to a better solution than existing approaches, while the query count is smaller than applying multiple random initializations by a factor of 10.
Cross-Modal Interaction Networks for Query-Based Moment Retrieval in Videos
Jun 06, 2019
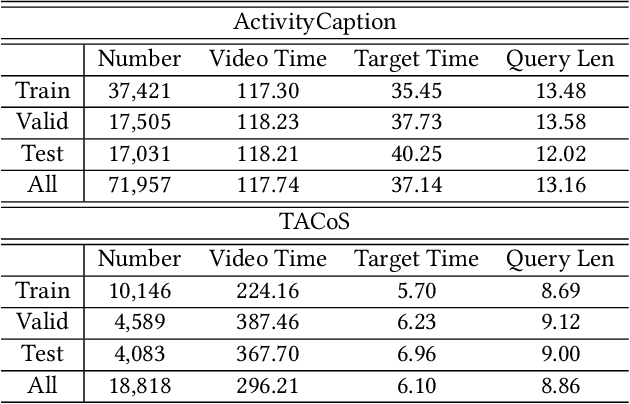
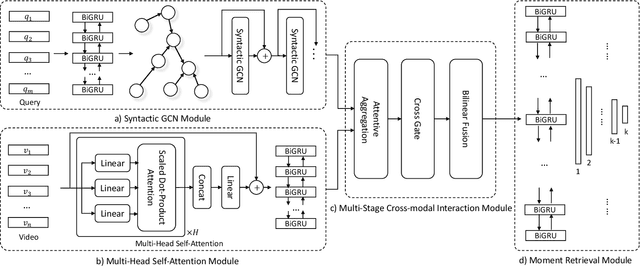
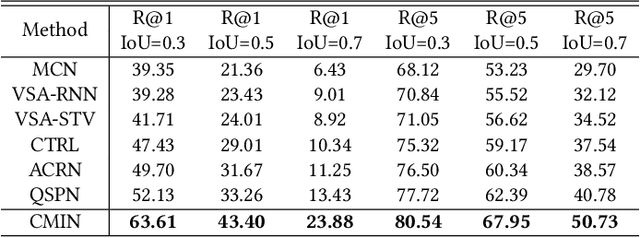
Query-based moment retrieval aims to localize the most relevant moment in an untrimmed video according to the given natural language query. Existing works often only focus on one aspect of this emerging task, such as the query representation learning, video context modeling or multi-modal fusion, thus fail to develop a comprehensive system for further performance improvement. In this paper, we introduce a novel Cross-Modal Interaction Network (CMIN) to consider multiple crucial factors for this challenging task, including (1) the syntactic structure of natural language queries; (2) long-range semantic dependencies in video context and (3) the sufficient cross-modal interaction. Specifically, we devise a syntactic GCN to leverage the syntactic structure of queries for fine-grained representation learning, propose a multi-head self-attention to capture long-range semantic dependencies from video context, and next employ a multi-stage cross-modal interaction to explore the potential relations of video and query contents. The extensive experiments demonstrate the effectiveness of our proposed method.