 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Transformer Attention Network for 3D Voxel Level Joint Segmentation and Motion Prediction in Point Cloud
Feb 28, 2022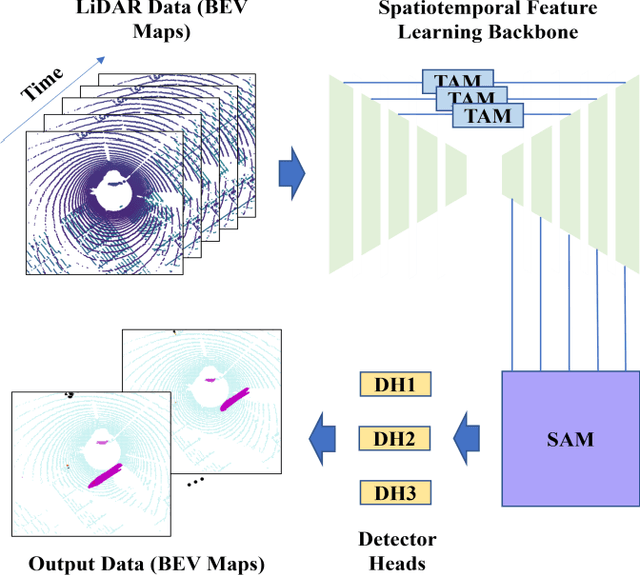
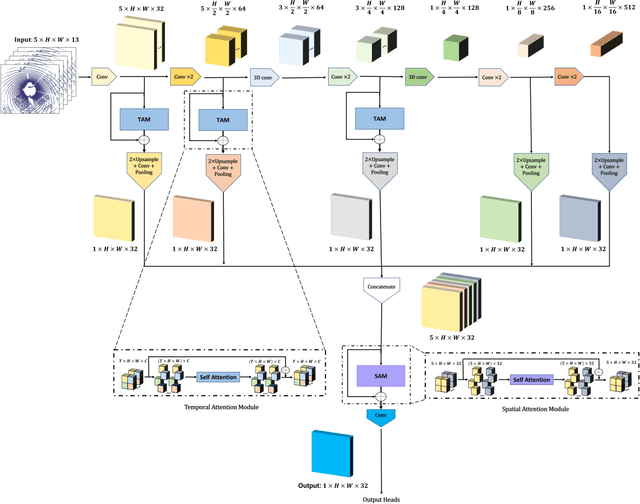
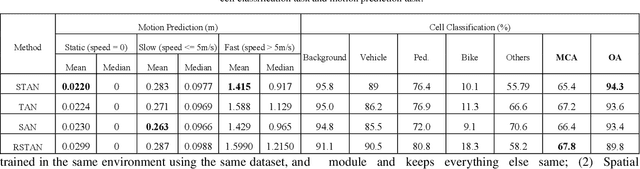
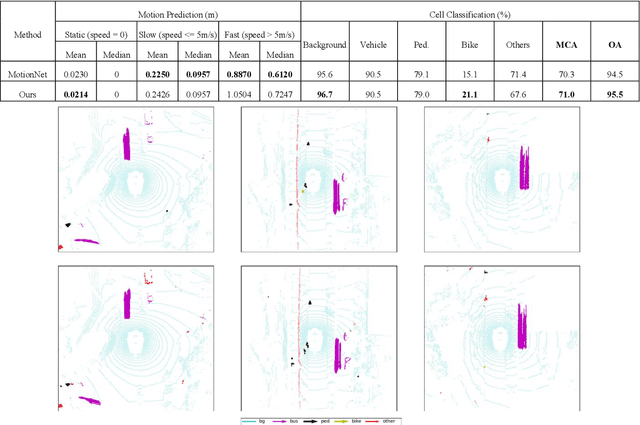
Environment perception including detection, classification, tracking, and motion prediction are key enablers for automated driving systems and intelligent transportation applications. Fueled by the advances in sensing technologies and machine learning techniques, LiDAR-based sensing systems have become a promising solution. The current challenges of this solution are how to effectively combine different perception tasks into a single backbone and how to efficiently learn the spatiotemporal features directly from point cloud sequences. In this research, we propose a novel spatiotemporal attention network based on a transformer self-attention mechanism for joint semantic segmentation and motion prediction within a point cloud at the voxel level. The network is trained to simultaneously outputs the voxel level class and predicted motion by learning directly from a sequence of point cloud datasets. The proposed backbone includes both a temporal attention module (TAM) and a spatial attention module (SAM) to learn and extract the complex spatiotemporal features. This approach has been evaluated with the nuScenes dataset, and promising performance has been achieved.
End-to-End Vision-Based Adaptive Cruise Control Using Deep Reinforcement Learning
Jan 24, 2020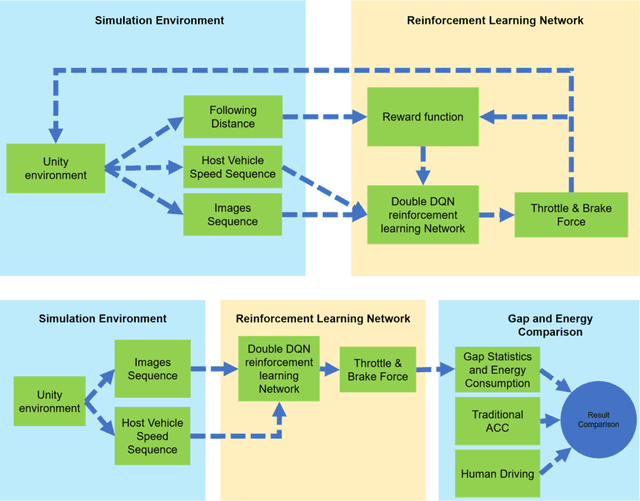
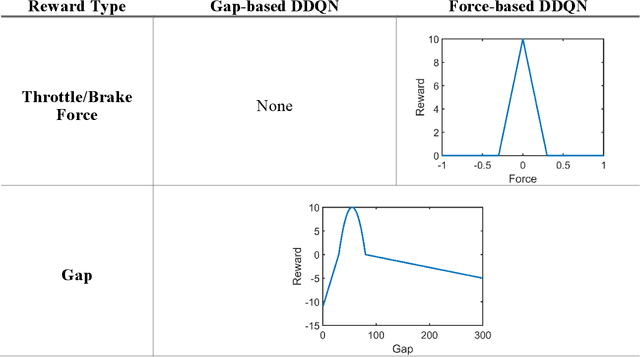

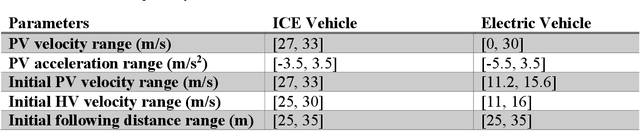
This paper presented a deep reinforcement learning method named Double Deep Q-networks to design an end-to-end vision-based adaptive cruise control (ACC) system. A simulation environment of a highway scene was set up in Unity, which is a game engine that provided both physical models of vehicles and feature data for training and testing. Well-designed reward functions associated with the following distance and throttle/brake force were implemented in the reinforcement learning model for both internal combustion engine (ICE) vehicles and electric vehicles (EV) to perform adaptive cruise control. The gap statistics and total energy consumption are evaluated for different vehicle types to explore the relationship between reward functions and powertrain characteristics. Compared with the traditional radar-based ACC systems or human-in-the-loop simulation, the proposed vision-based ACC system can generate either a better gap regulated trajectory or a smoother speed trajectory depending on the preset reward function. The proposed system can be well adaptive to different speed trajectories of the preceding vehicle and operated in real-time.
Vision-Based Lane-Changing Behavior Detection Using Deep Residual Neural Network
Nov 08, 2019

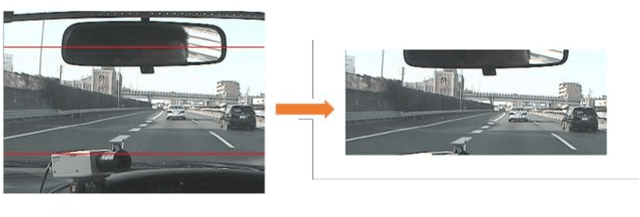
Accurate lane localization and lane change detection are crucial in advanced driver assistance systems and autonomous driving systems for safer and more efficient trajectory planning. Conventional localization devices such as Global Positioning System only provide road-level resolution for car navigation, which is incompetent to assist in lane-level decision making. The state of art technique for lane localization is to use Light Detection and Ranging sensors to correct the global localization error and achieve centimeter-level accuracy, but the real-time implementation and popularization for LiDAR is still limited by its computational burden and current cost. As a cost-effective alternative, vision-based lane change detection has been highly regarded for affordable autonomous vehicles to support lane-level localization. A deep learning-based computer vision system is developed to detect the lane change behavior using the images captured by a front-view camera mounted on the vehicle and data from the inertial measurement unit for highway driving. Testing results on real-world driving data have shown that the proposed method is robust with real-time working ability and could achieve around 87% lane change detection accuracy. Compared to the average human reaction to visual stimuli, the proposed computer vision system works 9 times faster, which makes it capable of helping make life-saving decisions in time.
Deep learning-based color holographic microscopy
Jul 15, 2019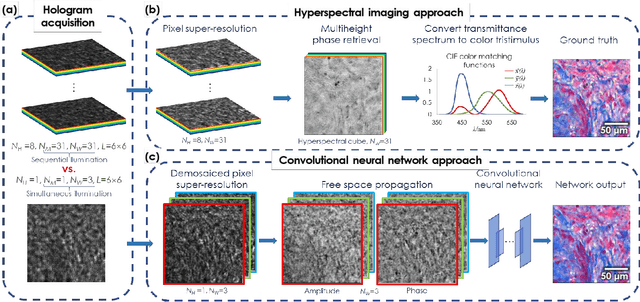
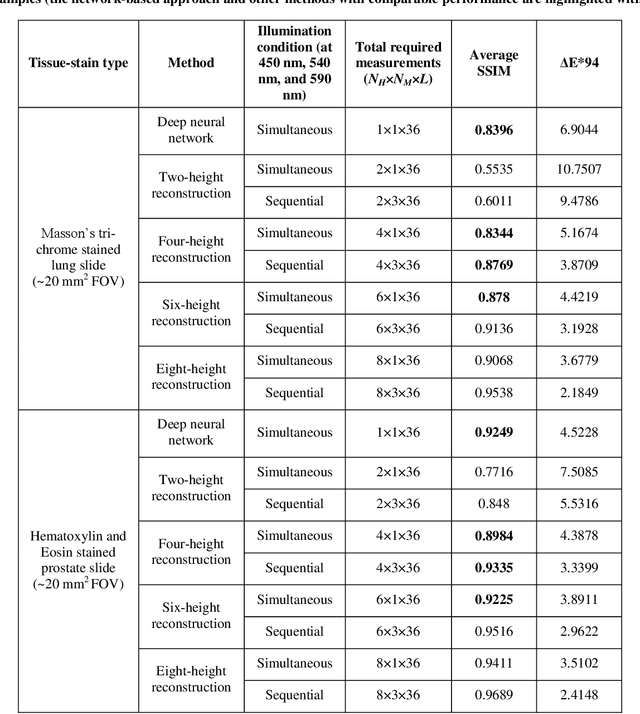
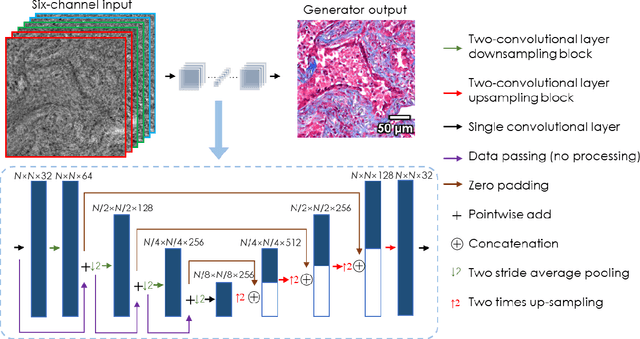
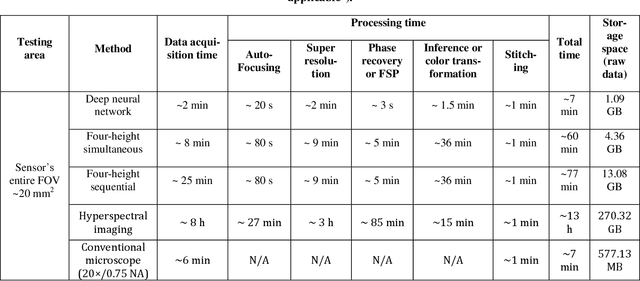
We report a framework based on a generative adversarial network (GAN) that performs high-fidelity color image reconstruction using a single hologram of a sample that is illuminated simultaneously by light at three different wavelengths. The trained network learns to eliminate missing-phase-related artifacts, and generates an accurate color transformation for the reconstructed image. Our framework is experimentally demonstrated using lung and prostate tissue sections that are labeled with different histological stains. This framework is envisaged to be applicable to point-of-care histopathology, and presents a significant improvement in the throughput of coherent microscopy systems given that only a single hologram of the specimen is required for accurate color imaging.
* 25 pages, 8 Figures, 2 Tables
Deep learning-based super-resolution in coherent imaging systems
Oct 15, 2018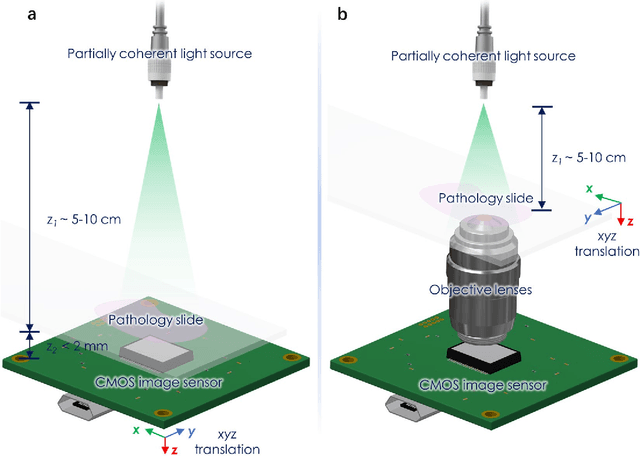

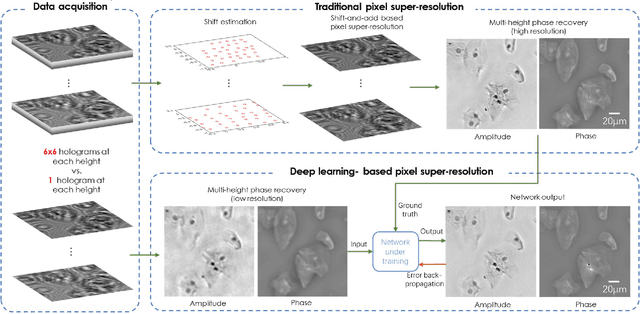
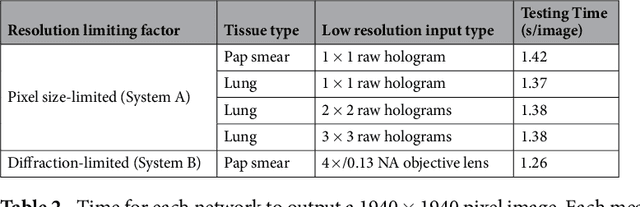
We present a deep learning framework based on a generative adversarial network (GAN) to perform super-resolution in coherent imaging systems. We demonstrate that this framework can enhance the resolution of both pixel size-limited and diffraction-limited coherent imaging systems. We experimentally validated the capabilities of this deep learning-based coherent imaging approach by super-resolving complex images acquired using a lensfree on-chip holographic microscope, the resolution of which was pixel size-limited. Using the same GAN-based approach, we also improved the resolution of a lens-based holographic imaging system that was limited in resolution by the numerical aperture of its objective lens. This deep learning-based super-resolution framework can be broadly applied to enhance the space-bandwidth product of coherent imaging systems using image data and convolutional neural networks, and provides a rapid, non-iterative method for solving inverse image reconstruction or enhancement problems in optics.
PhaseStain: Digital staining of label-free quantitative phase microscopy images using deep learning
Jul 20, 2018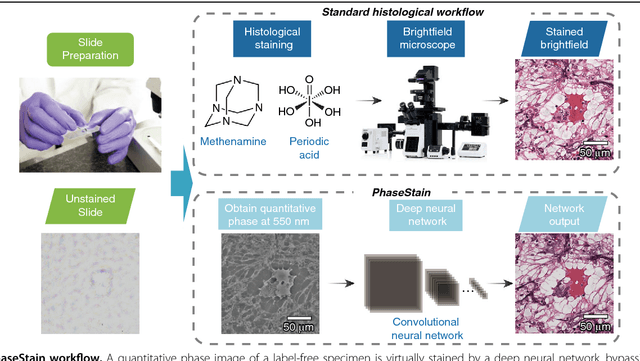


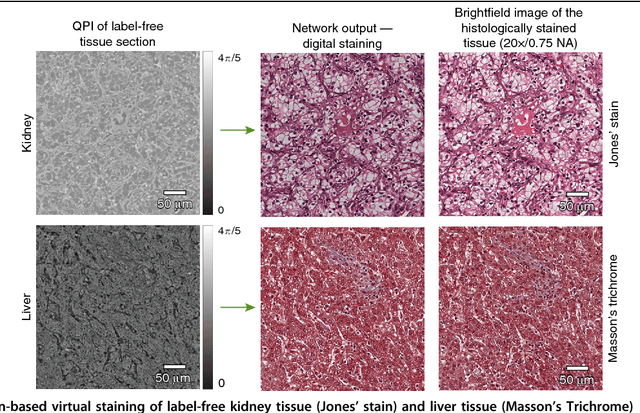
Using a deep neural network, we demonstrate a digital staining technique, which we term PhaseStain, to transform quantitative phase images (QPI) of labelfree tissue sections into images that are equivalent to brightfield microscopy images of the same samples that are histochemically stained. Through pairs of image data (QPI and the corresponding brightfield images, acquired after staining) we train a generative adversarial network (GAN) and demonstrate the effectiveness of this virtual staining approach using sections of human skin, kidney and liver tissue, matching the brightfield microscopy images of the same samples stained with Hematoxylin and Eosin, Jones' stain, and Masson's trichrome stain, respectively. This digital staining framework might further strengthen various uses of labelfree QPI techniques in pathology applications and biomedical research in general, by eliminating the need for chemical staining, reducing sample preparation related costs and saving time. Our results provide a powerful example of some of the unique opportunities created by data driven image transformations enabled by deep learning.
Deep learning-based virtual histology staining using auto-fluorescence of label-free tissue
Mar 30, 2018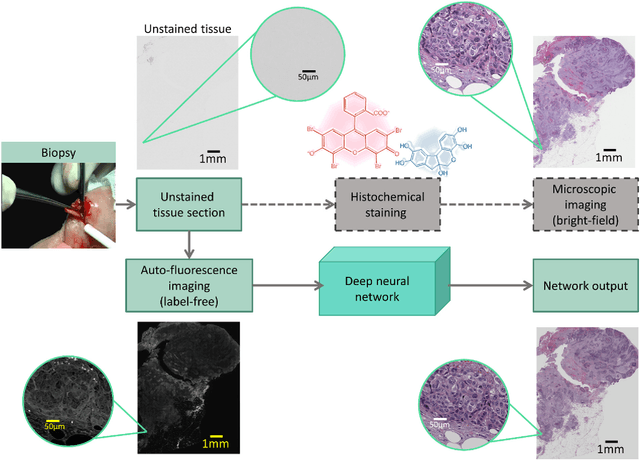
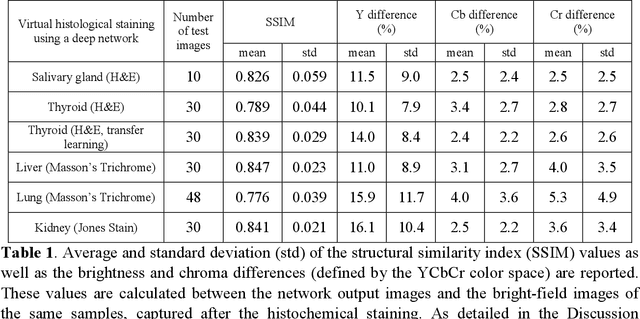
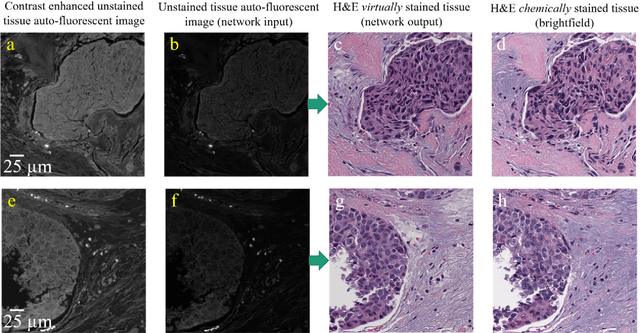
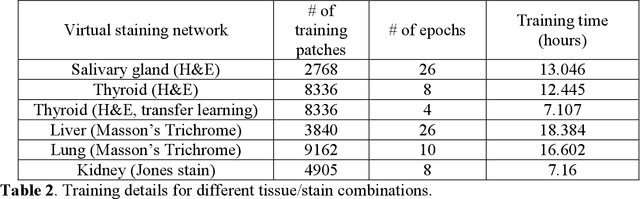
Histological analysis of tissue samples is one of the most widely used methods for disease diagnosis. After taking a sample from a patient, it goes through a lengthy and laborious preparation, which stains the tissue to visualize different histological features under a microscope. Here, we demonstrate a label-free approach to create a virtually-stained microscopic image using a single wide-field auto-fluorescence image of an unlabeled tissue sample, bypassing the standard histochemical staining process, saving time and cost. This method is based on deep learning, and uses a convolutional neural network trained using a generative adversarial network model to transform an auto-fluorescence image of an unlabeled tissue section into an image that is equivalent to the bright-field image of the stained-version of the same sample. We validated this method by successfully creating virtually-stained microscopic images of human tissue samples, including sections of salivary gland, thyroid, kidney, liver and lung tissue, also covering three different stains. This label-free virtual-staining method eliminates cumbersome and costly histochemical staining procedures, and would significantly simplify tissue preparation in pathology and histology fields.
Extended depth-of-field in holographic image reconstruction using deep learning based auto-focusing and phase-recovery
Mar 21, 2018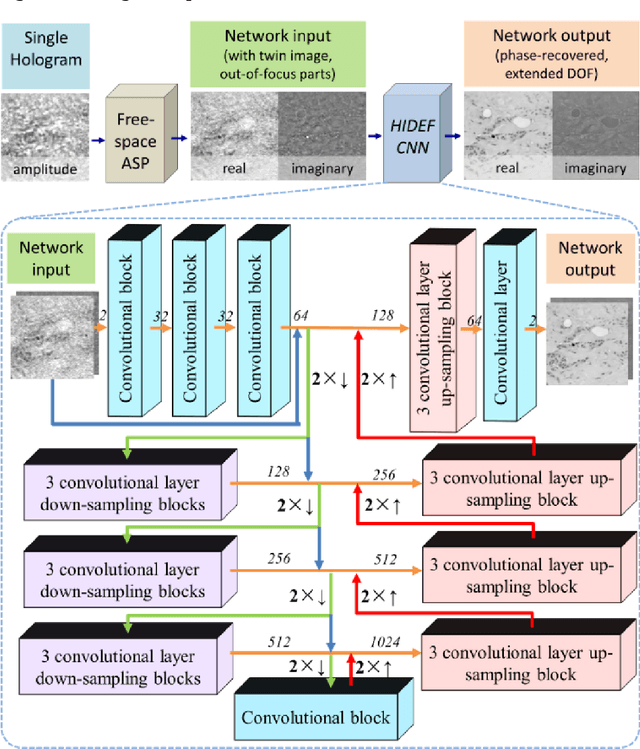
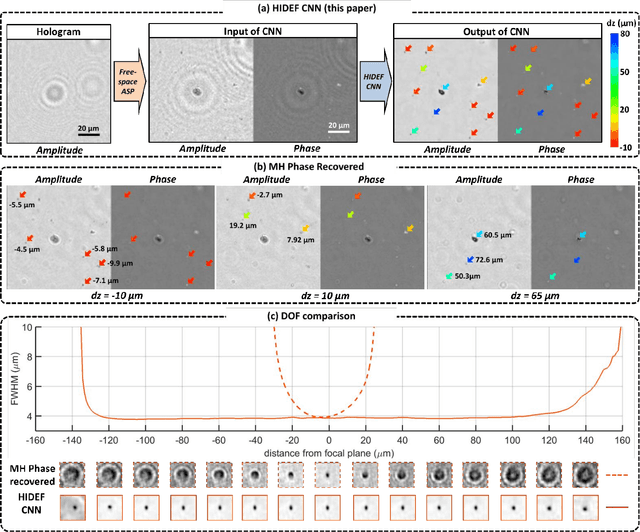

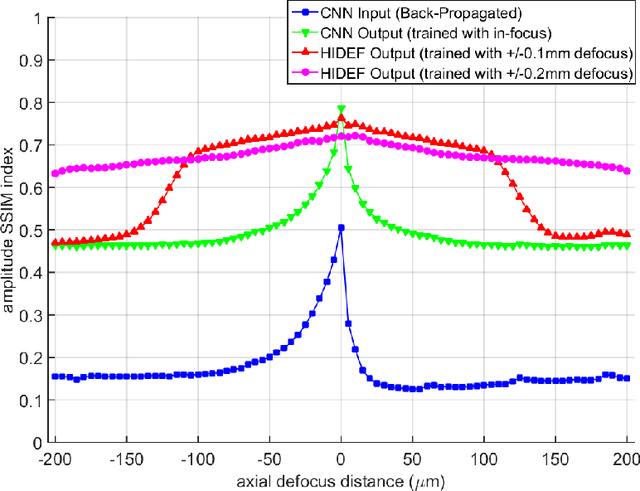
Holography encodes the three dimensional (3D) information of a sample in the form of an intensity-only recording. However, to decode the original sample image from its hologram(s), auto-focusing and phase-recovery are needed, which are in general cumbersome and time-consuming to digitally perform. Here we demonstrate a convolutional neural network (CNN) based approach that simultaneously performs auto-focusing and phase-recovery to significantly extend the depth-of-field (DOF) in holographic image reconstruction. For this, a CNN is trained by using pairs of randomly de-focused back-propagated holograms and their corresponding in-focus phase-recovered images. After this training phase, the CNN takes a single back-propagated hologram of a 3D sample as input to rapidly achieve phase-recovery and reconstruct an in focus image of the sample over a significantly extended DOF. This deep learning based DOF extension method is non-iterative, and significantly improves the algorithm time-complexity of holographic image reconstruction from O(nm) to O(1), where n refers to the number of individual object points or particles within the sample volume, and m represents the focusing search space within which each object point or particle needs to be individually focused. These results highlight some of the unique opportunities created by data-enabled statistical image reconstruction methods powered by machine learning, and we believe that the presented approach can be broadly applicable to computationally extend the DOF of other imaging modalities.
Deep learning enhanced mobile-phone microscopy
Dec 12, 2017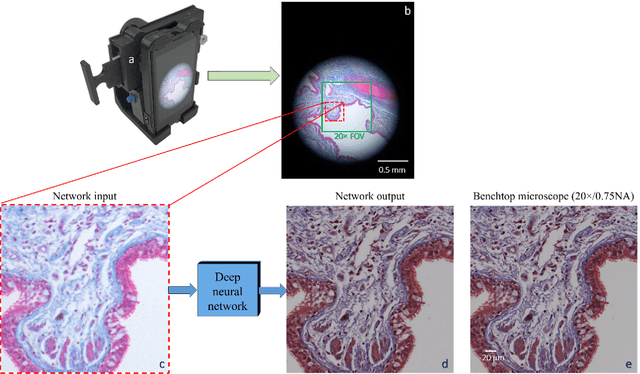
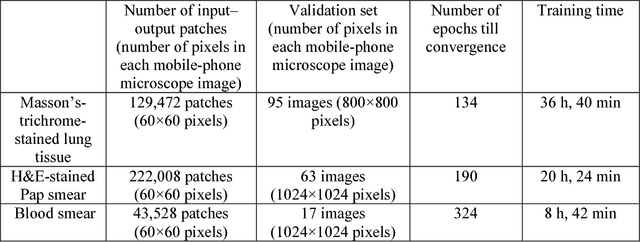
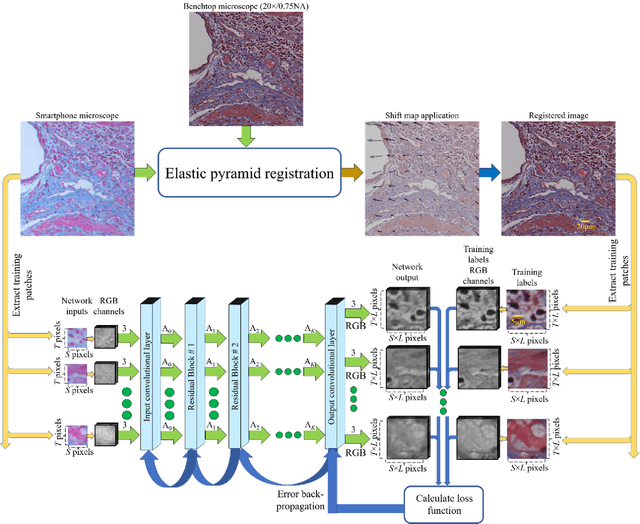
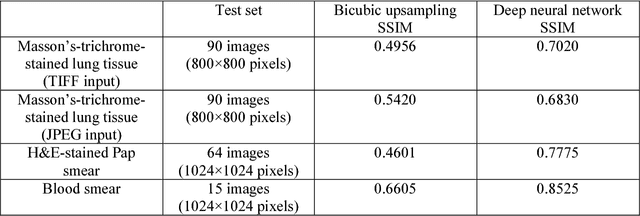
Mobile-phones have facilitated the creation of field-portable, cost-effective imaging and sensing technologies that approach laboratory-grade instrument performance. However, the optical imaging interfaces of mobile-phones are not designed for microscopy and produce spatial and spectral distortions in imaging microscopic specimens. Here, we report on the use of deep learning to correct such distortions introduced by mobile-phone-based microscopes, facilitating the production of high-resolution, denoised and colour-corrected images, matching the performance of benchtop microscopes with high-end objective lenses, also extending their limited depth-of-field. After training a convolutional neural network, we successfully imaged various samples, including blood smears, histopathology tissue sections, and parasites, where the recorded images were highly compressed to ease storage and transmission for telemedicine applications. This method is applicable to other low-cost, aberrated imaging systems, and could offer alternatives for costly and bulky microscopes, while also providing a framework for standardization of optical images for clinical and biomedical applications.