 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Transformer Attention Network for 3D Voxel Level Joint Segmentation and Motion Prediction in Point Cloud
Feb 28, 2022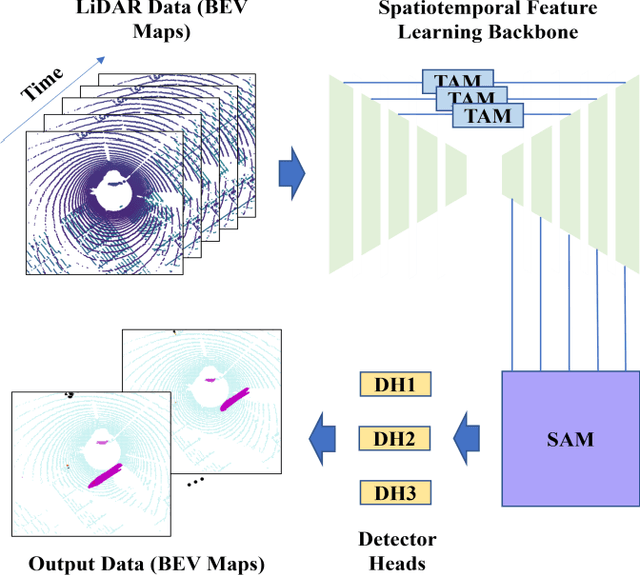
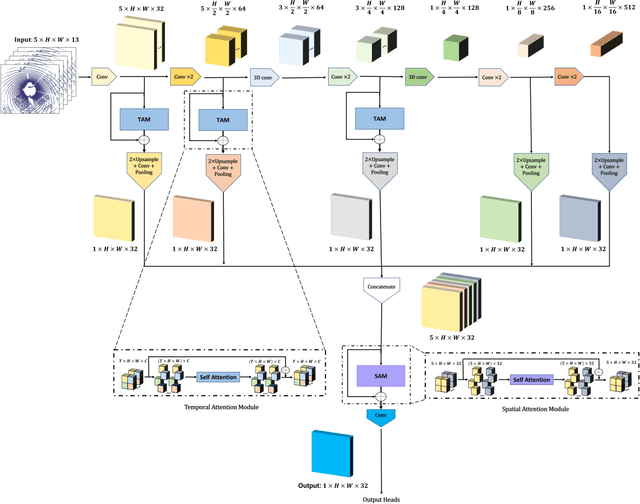
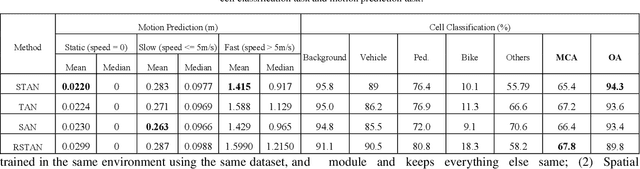
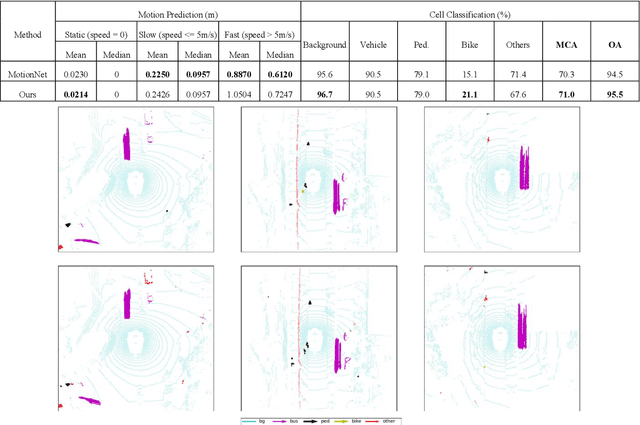
Environment perception including detection, classification, tracking, and motion prediction are key enablers for automated driving systems and intelligent transportation applications. Fueled by the advances in sensing technologies and machine learning techniques, LiDAR-based sensing systems have become a promising solution. The current challenges of this solution are how to effectively combine different perception tasks into a single backbone and how to efficiently learn the spatiotemporal features directly from point cloud sequences. In this research, we propose a novel spatiotemporal attention network based on a transformer self-attention mechanism for joint semantic segmentation and motion prediction within a point cloud at the voxel level. The network is trained to simultaneously outputs the voxel level class and predicted motion by learning directly from a sequence of point cloud datasets. The proposed backbone includes both a temporal attention module (TAM) and a spatial attention module (SAM) to learn and extract the complex spatiotemporal features. This approach has been evaluated with the nuScenes dataset, and promising performance has been achieved.