 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAxiomOcean: Forecasting the Three-Dimensional Structure of the Upper Ocean
May 11, 2026Short-term ocean forecast skill depends strongly on the three-dimensional ocean structure of the upper ocean, which governs stratification, subsurface heat storage, and the response of the ocean to atmospheric forcing. However, AI ocean forecasting models often fail to preserve this vertical structure, resulting in over-smoothed subsurface features and weak physical consistency under strong forcing. Here, we present AxiomOcean, a global AI ocean forecasting model that explicitly represents vertical hierarchy and cross-layer dependence within the water column. By combining a fully three-dimensional encoder-backbone-decoder architecture with surface atmospheric forcing, AxiomOcean jointly predicts upper-ocean temperature, salinity, and three-dimensional currents at global 1/12° resolution down to 643 m depth. In 10-day forecasts, AxiomOcean outperforms an advanced AI comparison model across variables and lead times, reducing day-1 RMSE by approximately 20 to 35% while maintaining higher anomaly correlation. The gain is not achieved through excessive smoothing: AxiomOcean better preserves eddy kinetic energy, temperature and salinity variance. Its advantage also extends through the water column and remains evident across the equatorial Pacific, Kuroshio Extension, and Southern Ocean, yielding a more realistic reconstruction of upper-ocean heat content. These results show that explicitly preserving upper-ocean three-dimensional structure can improve both forecast accuracy and physical fidelity in AI ocean prediction.
STeInFormer: Spatial-Temporal Interaction Transformer Architecture for Remote Sensing Change Detection
Dec 23, 2024Convolutional neural networks and attention mechanisms have greatly benefited remote sensing change detection (RSCD) because of their outstanding discriminative ability. Existent RSCD methods often follow a paradigm of using a non-interactive Siamese neural network for multi-temporal feature extraction and change detection heads for feature fusion and change representation. However, this paradigm lacks the contemplation of the characteristics of RSCD in temporal and spatial dimensions, and causes the drawback on spatial-temporal interaction that hinders high-quality feature extraction. To address this problem, we present STeInFormer, a spatial-temporal interaction Transformer architecture for multi-temporal feature extraction, which is the first general backbone network specifically designed for RSCD. In addition, we propose a parameter-free multi-frequency token mixer to integrate frequency-domain features that provide spectral information for RSCD. Experimental results on three datasets validate the effectiveness of the proposed method, which can outperform the state-of-the-art methods and achieve the most satisfactory efficiency-accuracy trade-off. Code is available at https://github.com/xwmaxwma/rschange.
ShapefileGPT: A Multi-Agent Large Language Model Framework for Automated Shapefile Processing
Oct 16, 2024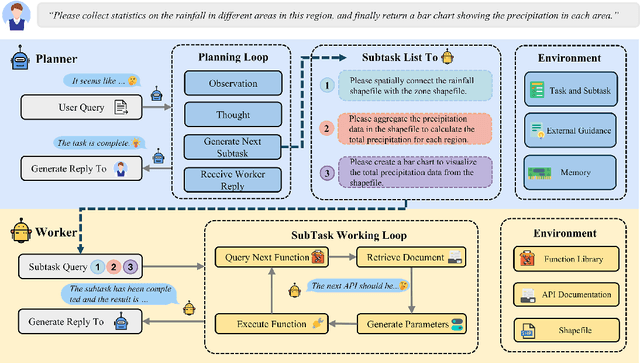


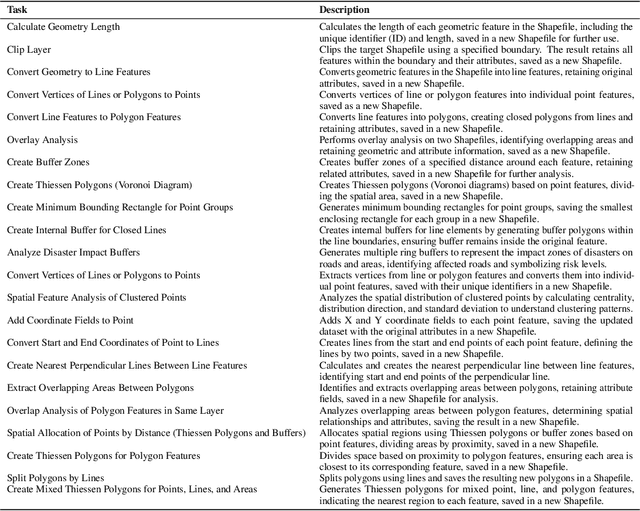
Vector data is one of the two core data structures in geographic information science (GIS), essential for accurately storing and representing geospatial information. Shapefile, the most widely used vector data format, has become the industry standard supported by all major geographic information systems. However, processing this data typically requires specialized GIS knowledge and skills, creating a barrier for researchers from other fields and impeding interdisciplinary research in spatial data analysis. Moreover, while large language models (LLMs) have made significant advancements in natural language processing and task automation, they still face challenges in handling the complex spatial and topological relationships inherent in GIS vector data. To address these challenges, we propose ShapefileGPT, an innovative framework powered by LLMs, specifically designed to automate Shapefile tasks. ShapefileGPT utilizes a multi-agent architecture, in which the planner agent is responsible for task decomposition and supervision, while the worker agent executes the tasks. We developed a specialized function library for handling Shapefiles and provided comprehensive API documentation, enabling the worker agent to operate Shapefiles efficiently through function calling. For evaluation, we developed a benchmark dataset based on authoritative textbooks, encompassing tasks in categories such as geometric operations and spatial queries. ShapefileGPT achieved a task success rate of 95.24%, outperforming the GPT series models. In comparison to traditional LLMs, ShapefileGPT effectively handles complex vector data analysis tasks, overcoming the limitations of traditional LLMs in spatial analysis. This breakthrough opens new pathways for advancing automation and intelligence in the GIS field, with significant potential in interdisciplinary data analysis and application contexts.
ControlCity: A Multimodal Diffusion Model Based Approach for Accurate Geospatial Data Generation and Urban Morphology Analysis
Sep 25, 2024



Volunteer Geographic Information (VGI), with its rich variety, large volume, rapid updates, and diverse sources, has become a critical source of geospatial data. However, VGI data from platforms like OSM exhibit significant quality heterogeneity across different data types, particularly with urban building data. To address this, we propose a multi-source geographic data transformation solution, utilizing accessible and complete VGI data to assist in generating urban building footprint data. We also employ a multimodal data generation framework to improve accuracy. First, we introduce a pipeline for constructing an 'image-text-metadata-building footprint' dataset, primarily based on road network data and supplemented by other multimodal data. We then present ControlCity, a geographic data transformation method based on a multimodal diffusion model. This method first uses a pre-trained text-to-image model to align text, metadata, and building footprint data. An improved ControlNet further integrates road network and land-use imagery, producing refined building footprint data. Experiments across 22 global cities demonstrate that ControlCity successfully simulates real urban building patterns, achieving state-of-the-art performance. Specifically, our method achieves an average FID score of 50.94, reducing error by 71.01% compared to leading methods, and a MIoU score of 0.36, an improvement of 38.46%. Additionally, our model excels in tasks like urban morphology transfer, zero-shot city generation, and spatial data completeness assessment. In the zero-shot city task, our method accurately predicts and generates similar urban structures, demonstrating strong generalization. This study confirms the effectiveness of our approach in generating urban building footprint data and capturing complex city characteristics.
Evaluating Large Language Models on Spatial Tasks: A Multi-Task Benchmarking Study
Aug 26, 2024



The advent of large language models such as ChatGPT, Gemini, and others has underscored the importance of evaluating their diverse capabilities, ranging from natural language understanding to code generation. However, their performance on spatial tasks has not been comprehensively assessed. This study addresses this gap by introducing a novel multi-task spatial evaluation dataset, designed to systematically explore and compare the performance of several advanced models on spatial tasks. The dataset encompasses twelve distinct task types, including spatial understanding and path planning, each with verified, accurate answers. We evaluated multiple models, including OpenAI's gpt-3.5-turbo, gpt-4o, and ZhipuAI's glm-4, through a two-phase testing approach. Initially, we conducted zero-shot testing, followed by categorizing the dataset by difficulty and performing prompt tuning tests. Results indicate that gpt-4o achieved the highest overall accuracy in the first phase, with an average of 71.3%. Although moonshot-v1-8k slightly underperformed overall, it surpassed gpt-4o in place name recognition tasks. The study also highlights the impact of prompt strategies on model performance in specific tasks. For example, the Chain-of-Thought (COT) strategy increased gpt-4o's accuracy in path planning from 12.4% to 87.5%, while a one-shot strategy enhanced moonshot-v1-8k's accuracy in mapping tasks from 10.1% to 76.3%.
LOGCAN++: Adaptive Local-global class-aware network for semantic segmentation of remote sensing imagery
Jul 02, 2024



Remote sensing images usually characterized by complex backgrounds, scale and orientation variations, and large intra-class variance. General semantic segmentation methods usually fail to fully investigate the above issues, and thus their performances on remote sensing image segmentation are limited. In this paper, we propose our LOGCAN++, a semantic segmentation model customized for remote sensing images, which is made up of a Global Class Awareness (GCA) module and several Local Class Awareness (LCA) modules. The GCA module captures global representations for class-level context modeling to reduce the interference of background noise. The LCA module generates local class representations as intermediate perceptual elements to indirectly associate pixels with the global class representations, targeting at dealing with the large intra-class variance problem. In particular, we introduce affine transformations in the LCA module for adaptive extraction of local class representations to effectively tolerate scale and orientation variations in remotely sensed images. Extensive experiments on three benchmark datasets show that our LOGCAN++ outperforms current mainstream general and remote sensing semantic segmentation methods and achieves a better trade-off between speed and accuracy. Code is available at https://github.com/xwmaxwma/rssegmentation.
LOGCAN++: Local-global class-aware network for semantic segmentation of remote sensing images
Jun 24, 2024Remote sensing images usually characterized by complex backgrounds, scale and orientation variations, and large intra-class variance. General semantic segmentation methods usually fail to fully investigate the above issues, and thus their performances on remote sensing image segmentation are limited. In this paper, we propose our LOGCAN++, a semantic segmentation model customized for remote sensing images, which is made up of a Global Class Awareness (GCA) module and several Local Class Awareness (LCA) modules. The GCA module captures global representations for class-level context modeling to reduce the interference of background noise. The LCA module generates local class representations as intermediate perceptual elements to indirectly associate pixels with the global class representations, targeting at dealing with the large intra-class variance problem. In particular, we introduce affine transformations in the LCA module for adaptive extraction of local class representations to effectively tolerate scale and orientation variations in remotely sensed images. Extensive experiments on three benchmark datasets show that our LOGCAN++ outperforms current mainstream general and remote sensing semantic segmentation methods and achieves a better trade-off between speed and accuracy. Code is available at https://github.com/xwmaxwma/rssegmentation.
Group-Aware Graph Neural Network for Nationwide City Air Quality Forecasting
Aug 27, 2021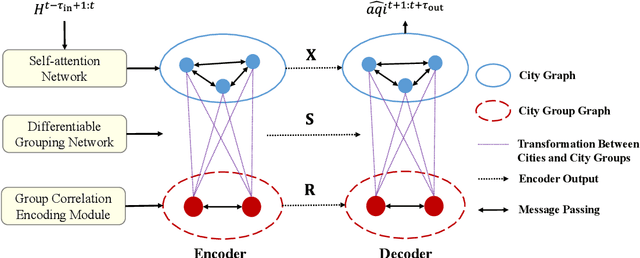
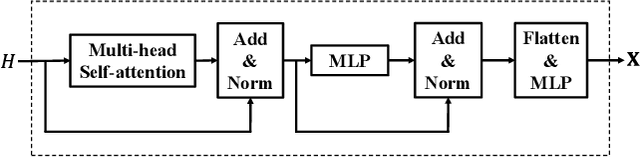
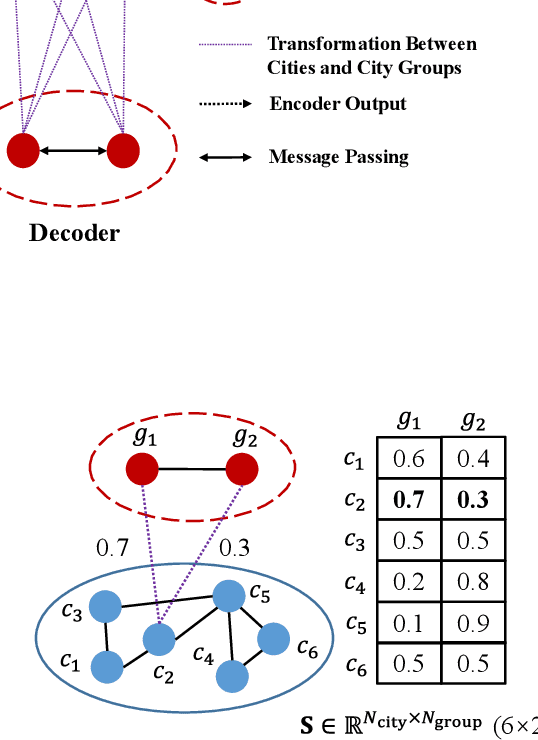
The problem of air pollution threatens public health. Air quality forecasting can provide the air quality index hours or even days later, which can help the public to prevent air pollution in advance. Previous works focus on citywide air quality forecasting and cannot solve nationwide city forecasting problem, whose difficulties lie in capturing the latent dependencies between geographically distant but highly correlated cities. In this paper, we propose the group-aware graph neural network (GAGNN), a hierarchical model for nationwide city air quality forecasting. The model constructs a city graph and a city group graph to model the spatial and latent dependencies between cities, respectively. GAGNN introduces differentiable grouping network to discover the latent dependencies among cities and generate city groups. Based on the generated city groups, a group correlation encoding module is introduced to learn the correlations between them, which can effectively capture the dependencies between city groups. After the graph construction, GAGNN implements message passing mechanism to model the dependencies between cities and city groups. The evaluation experiments on Chinese city air quality dataset indicate that our GAGNN outperforms existing forecasting models.