 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReDON: Recurrent Diffractive Optical Neural Processor with Reconfigurable Self-Modulated Nonlinearity
Mar 02, 2026Diffractive optical neural networks (DONNs) have demonstrated unparalleled energy efficiency and parallelism by processing information directly in the optical domain. However, their computational expressivity is constrained by static, passive diffractive phase masks that lack efficient nonlinear responses and reprogrammability. To address these limitations, we introduce the Recurrent Diffractive Optical Neural Processor (ReDON), a novel architecture featuring reconfigurable, recurrent self-modulated nonlinearity. This mechanism enables dynamic, input-dependent optical transmission through in-situ electro-optic self-modulation, providing a highly efficient and reprogrammable approach to optical computation. Inspired by the gated linear unit (GLU) used in large language models, ReDON senses a fraction of the propagating optical field and modulates its phase or intensity via a lightweight parametric function, enabling effective nonlinearity with minimal inference overhead. As a non-von Neumann architecture in which the primary weighting elements (metasurfaces) remain fixed, ReDON substantially extends the nonlinear representational capacity and task adaptability of conventional DONNs through recurrent optical hardware reuse and dynamically tunable nonlinearity. We systematically investigate various self-modulation configurations to characterize the trade-offs between hardware efficiency and computational expressivity. On image recognition and segmentation benchmarks, ReDON improves test accuracy and mean intersection-over-union (mIoU) by up to 20% compared with prior DONNs employing either optical or digital nonlinearities at comparable model complexity and negligible additional power consumption. This work establishes a new paradigm for reconfigurable nonlinear optical computing, uniting recurrence and self-modulation within non-von Neumann analog processors.
SP2RINT: Spatially-Decoupled Physics-Inspired Progressive Inverse Optimization for Scalable, PDE-Constrained Meta-Optical Neural Network Training
May 23, 2025DONNs harness the physics of light propagation for efficient analog computation, with applications in AI and signal processing. Advances in nanophotonic fabrication and metasurface-based wavefront engineering have opened new pathways to realize high-capacity DONNs across various spectral regimes. Training such DONN systems to determine the metasurface structures remains challenging. Heuristic methods are fast but oversimplify metasurfaces modulation, often resulting in physically unrealizable designs and significant performance degradation. Simulation-in-the-loop training methods directly optimize a physically implementable metasurface using adjoint methods during end-to-end DONN training, but are inherently computationally prohibitive and unscalable.To address these limitations, we propose SP2RINT, a spatially decoupled, progressive training framework that formulates DONN training as a PDE-constrained learning problem. Metasurface responses are first relaxed into freely trainable transfer matrices with a banded structure. We then progressively enforce physical constraints by alternating between transfer matrix training and adjoint-based inverse design, avoiding per-iteration PDE solves while ensuring final physical realizability. To further reduce runtime, we introduce a physics-inspired, spatially decoupled inverse design strategy based on the natural locality of field interactions. This approach partitions the metasurface into independently solvable patches, enabling scalable and parallel inverse design with system-level calibration. Evaluated across diverse DONN training tasks, SP2RINT achieves digital-comparable accuracy while being 1825 times faster than simulation-in-the-loop approaches. By bridging the gap between abstract DONN models and implementable photonic hardware, SP2RINT enables scalable, high-performance training of physically realizable meta-optical neural systems.
DeepPointMap: Advancing LiDAR SLAM with Unified Neural Descriptors
Dec 05, 2023



Point clouds have shown significant potential in various domains, including Simultaneous Localization and Mapping (SLAM). However, existing approaches either rely on dense point clouds to achieve high localization accuracy or use generalized descriptors to reduce map size. Unfortunately, these two aspects seem to conflict with each other. To address this limitation, we propose a unified architecture, DeepPointMap, achieving excellent preference on both aspects. We utilize neural network to extract highly representative and sparse neural descriptors from point clouds, enabling memory-efficient map representation and accurate multi-scale localization tasks (e.g., odometry and loop-closure). Moreover, we showcase the versatility of our framework by extending it to more challenging multi-agent collaborative SLAM. The promising results obtained in these scenarios further emphasize the effectiveness and potential of our approach.
SEdroid: A Robust Android Malware Detector using Selective Ensemble Learning
Sep 06, 2019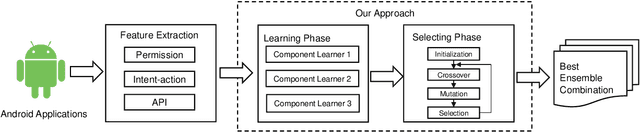
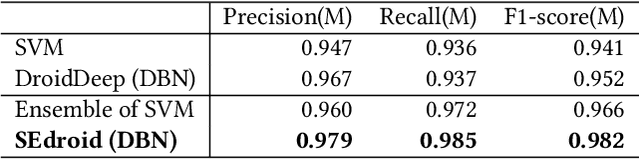
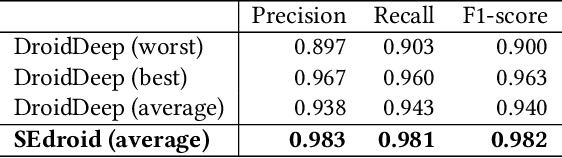
For the dramatic increase of Android malware and low efficiency of manual check process, deep learning methods started to be an auxiliary means for Android malware detection these years. However, these models are highly dependent on the quality of datasets, and perform unsatisfactory results when the quality of training data is not good enough. In the real world, the quality of datasets without manually check cannot be guaranteed, even Google Play may contain malicious applications, which will cause the trained model failure. To address the challenge, we propose a robust Android malware detection approach based on selective ensemble learning, trying to provide an effective solution not that limited to the quality of datasets. The proposed model utilizes genetic algorithm to help find the best combination of the component learners and improve robustness of the model. Our results show that the proposed approach achieves a more robust performance than other approaches in the same area.