 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEARL: Entropy-Aware RL Alignment of LLMs for Reliable RTL Code Generation
Nov 15, 2025Recent advances in large language models (LLMs) have demonstrated significant potential in hardware design automation, particularly in using natural language to synthesize Register-Transfer Level (RTL) code. Despite this progress, a gap remains between model capability and the demands of real-world RTL design, including syntax errors, functional hallucinations, and weak alignment to designer intent. Reinforcement Learning with Verifiable Rewards (RLVR) offers a promising approach to bridge this gap, as hardware provides executable and formally checkable signals that can be used to further align model outputs with design intent. However, in long, structured RTL code sequences, not all tokens contribute equally to functional correctness, and naïvely spreading gradients across all tokens dilutes learning signals. A key insight from our entropy analysis in RTL generation is that only a small fraction of tokens (e.g., always, if, assign, posedge) exhibit high uncertainty and largely influence control flow and module structure. To address these challenges, we present EARL, an Entropy-Aware Reinforcement Learning framework for Verilog generation. EARL performs policy optimization using verifiable reward signals and introduces entropy-guided selective updates that gate policy gradients to high-entropy tokens. This approach preserves training stability and concentrates gradient updates on functionally important regions of code. Our experiments on VerilogEval and RTLLM show that EARL improves functional pass rates over prior LLM baselines by up to 14.7%, while reducing unnecessary updates and improving training stability. These results indicate that focusing RL on critical, high-uncertainty tokens enables more reliable and targeted policy improvement for structured RTL code generation.
FedCoCo: A Memory Efficient Federated Self-supervised Framework for On-Device Visual Representation Learning
Dec 02, 2022



The ubiquity of edge devices has led to a growing amount of unlabeled data produced at the edge. Deep learning models deployed on edge devices are required to learn from these unlabeled data to continuously improve accuracy. Self-supervised representation learning has achieved promising performances using centralized unlabeled data. However, the increasing awareness of privacy protection limits centralizing the distributed unlabeled image data on edge devices. While federated learning has been widely adopted to enable distributed machine learning with privacy preservation, without a data selection method to efficiently select streaming data, the traditional federated learning framework fails to handle these huge amounts of decentralized unlabeled data with limited storage resources on edge. To address these challenges, we propose a Federated on-device Contrastive learning framework with Coreset selection, which we call FedCoCo, to automatically select a coreset that consists of the most representative samples into the replay buffer on each device. It preserves data privacy as each client does not share raw data while learning good visual representations. Experiments demonstrate the effectiveness and significance of the proposed method in visual representation learning.
Kernel based low-rank sparse model for single image super-resolution
Sep 27, 2018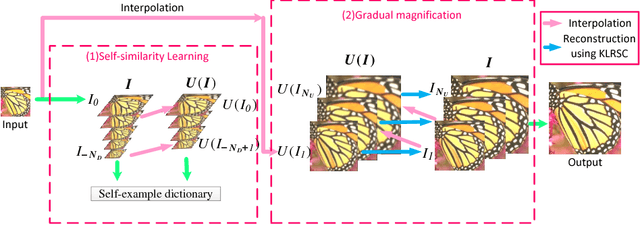
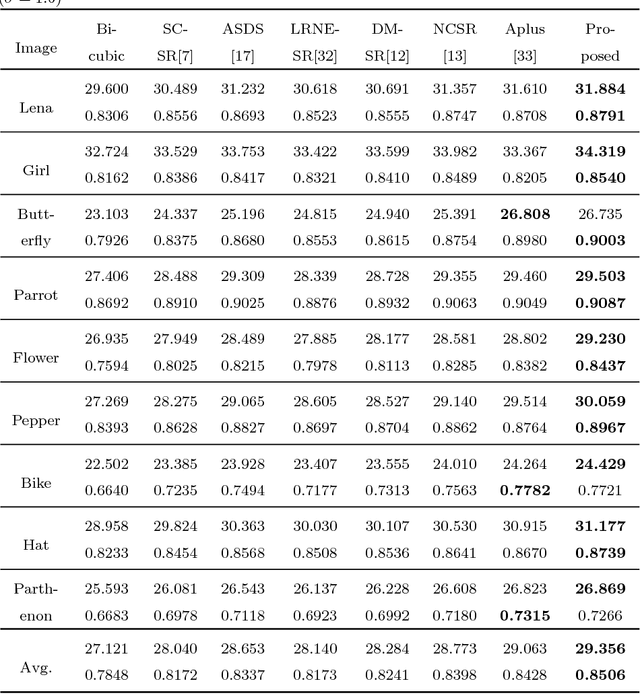
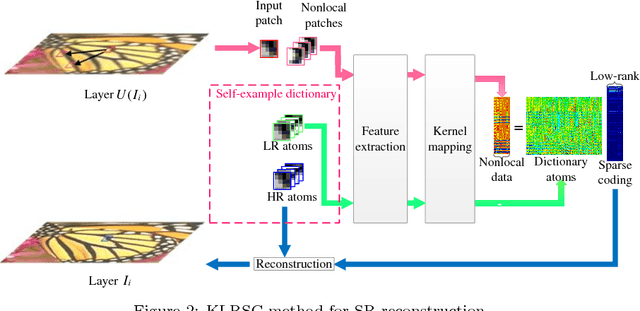
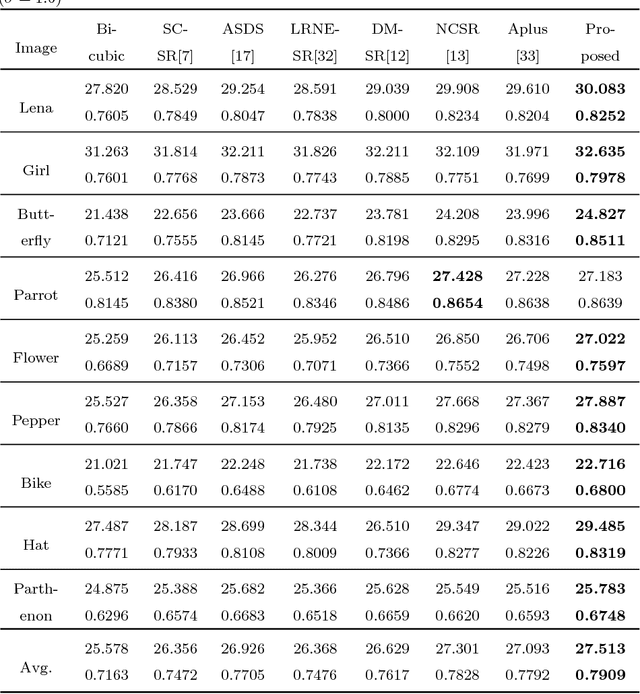
Self-similarity learning has been recognized as a promising method for single image super-resolution (SR) to produce high-resolution (HR) image in recent years. The performance of learning based SR reconstruction, however, highly depends on learned representation coeffcients. Due to the degradation of input image, conventional sparse coding is prone to produce unfaithful representation coeffcients. To this end, we propose a novel kernel based low-rank sparse model with self-similarity learning for single image SR which incorporates nonlocalsimilarity prior to enforce similar patches having similar representation weights. We perform a gradual magnification scheme, using self-examples extracted from the degraded input image and up-scaled versions. To exploit nonlocal-similarity, we concatenate the vectorized input patch and its nonlocal neighbors at different locations into a data matrix which consists of similar components. Then we map the nonlocal data matrix into a high-dimensional feature space by kernel method to capture their nonlinear structures. Under the assumption that the sparse coeffcients for the nonlocal data in the kernel space should be low-rank, we impose low-rank constraint on sparse coding to share similarities among representation coeffcients and remove outliers in order that stable weights for SR reconstruction can be obtained. Experimental results demonstrate the advantage of our proposed method in both visual quality and reconstruction error.