 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Joint Maximum Mean Discrepancy for Domain Adaptation
Jan 25, 2021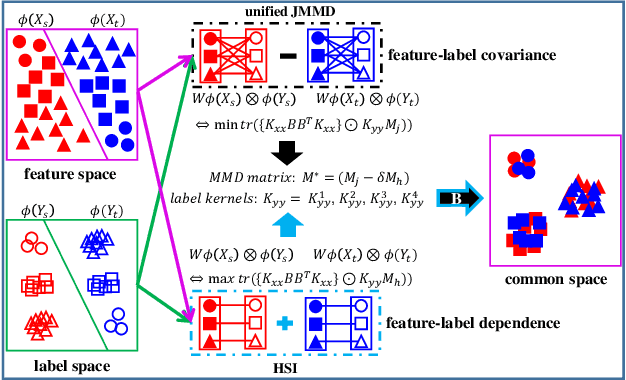
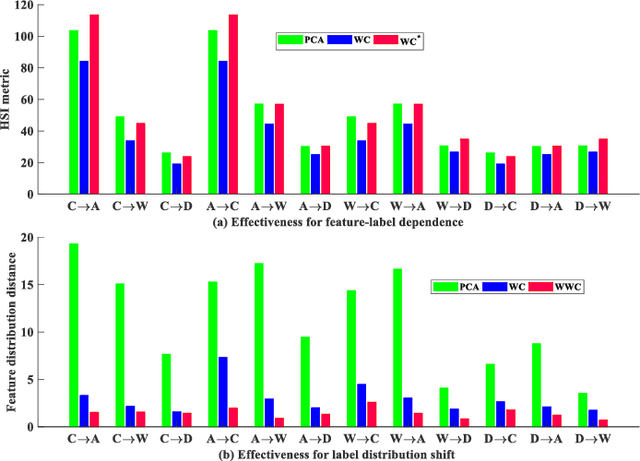
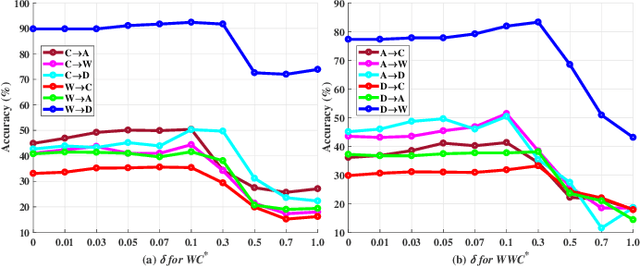
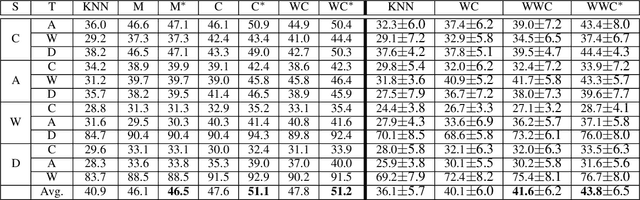
Domain adaptation has received a lot of attention in recent years, and many algorithms have been proposed with impressive progress. However, it is still not fully explored concerning the joint probability distribution (P(X, Y)) distance for this problem, since its empirical estimation derived from the maximum mean discrepancy (joint maximum mean discrepancy, JMMD) will involve complex tensor-product operator that is hard to manipulate. To solve this issue, this paper theoretically derives a unified form of JMMD that is easy to optimize, and proves that the marginal, class conditional and weighted class conditional probability distribution distances are our special cases with different label kernels, among which the weighted class conditional one not only can realize feature alignment across domains in the category level, but also deal with imbalance dataset using the class prior probabilities. From the revealed unified JMMD, we illustrate that JMMD degrades the feature-label dependence (discriminability) that benefits to classification, and it is sensitive to the label distribution shift when the label kernel is the weighted class conditional one. Therefore, we leverage Hilbert Schmidt independence criterion and propose a novel MMD matrix to promote the dependence, and devise a novel label kernel that is robust to label distribution shift. Finally, we conduct extensive experiments on several cross-domain datasets to demonstrate the validity and effectiveness of the revealed theoretical results.
Generative Partial Visual-Tactile Fused Object Clustering
Dec 28, 2020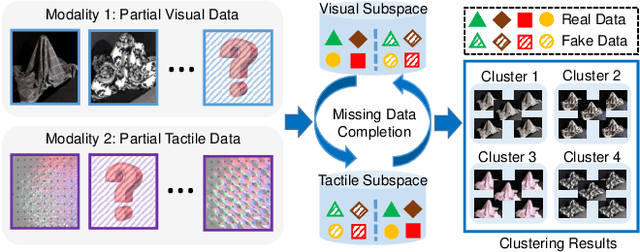
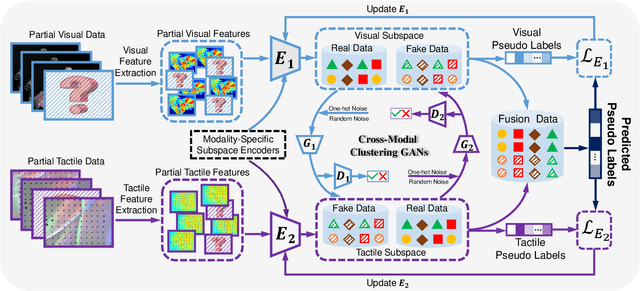
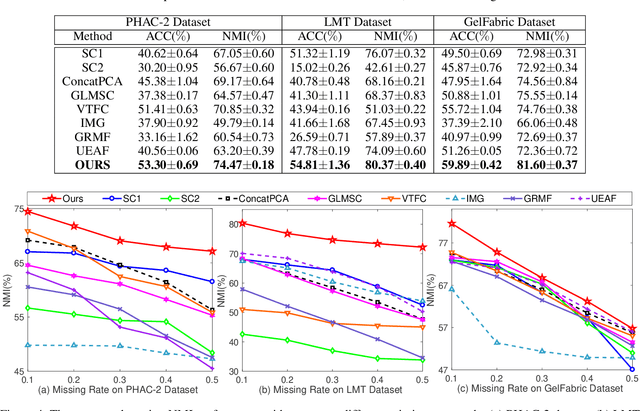
Visual-tactile fused sensing for object clustering has achieved significant progresses recently, since the involvement of tactile modality can effectively improve clustering performance. However, the missing data (i.e., partial data) issues always happen due to occlusion and noises during the data collecting process. This issue is not well solved by most existing partial multi-view clustering methods for the heterogeneous modality challenge. Naively employing these methods would inevitably induce a negative effect and further hurt the performance. To solve the mentioned challenges, we propose a Generative Partial Visual-Tactile Fused (i.e., GPVTF) framework for object clustering. More specifically, we first do partial visual and tactile features extraction from the partial visual and tactile data, respectively, and encode the extracted features in modality-specific feature subspaces. A conditional cross-modal clustering generative adversarial network is then developed to synthesize one modality conditioning on the other modality, which can compensate missing samples and align the visual and tactile modalities naturally by adversarial learning. To the end, two pseudo-label based KL-divergence losses are employed to update the corresponding modality-specific encoders. Extensive comparative experiments on three public visual-tactile datasets prove the effectiveness of our method.
Weakly-Supervised Cross-Domain Adaptation for Endoscopic Lesions Segmentation
Dec 08, 2020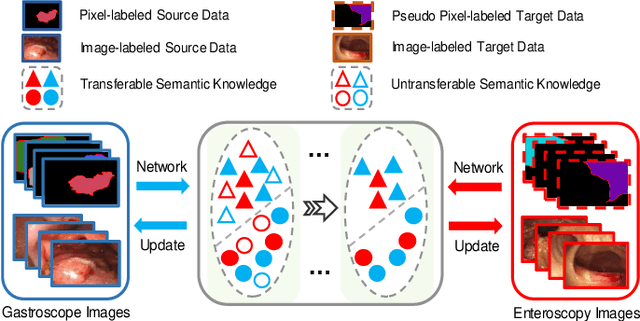
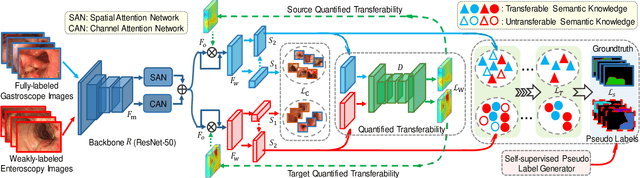
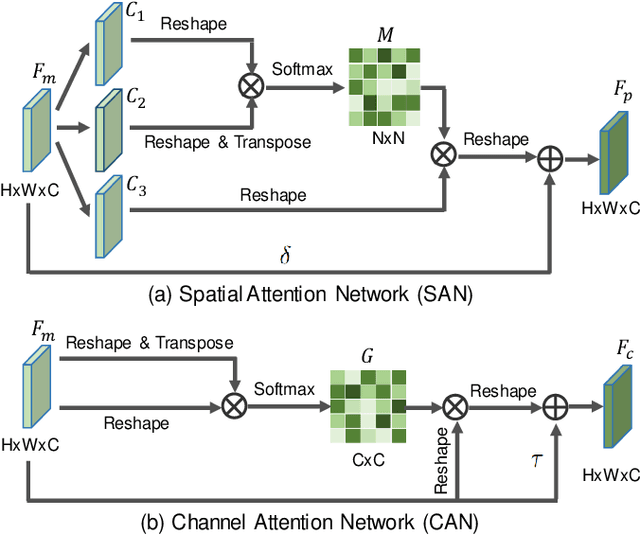
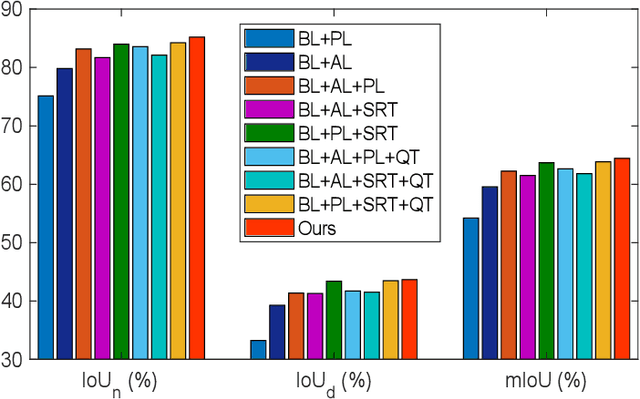
Weakly-supervised learning has attracted growing research attention on medical lesions segmentation due to significant saving in pixel-level annotation cost. However, 1) most existing methods require effective prior and constraints to explore the intrinsic lesions characterization, which only generates incorrect and rough prediction; 2) they neglect the underlying semantic dependencies among weakly-labeled target enteroscopy diseases and fully-annotated source gastroscope lesions, while forcefully utilizing untransferable dependencies leads to the negative performance. To tackle above issues, we propose a new weakly-supervised lesions transfer framework, which can not only explore transferable domain-invariant knowledge across different datasets, but also prevent the negative transfer of untransferable representations. Specifically, a Wasserstein quantified transferability framework is developed to highlight widerange transferable contextual dependencies, while neglecting the irrelevant semantic characterizations. Moreover, a novel selfsupervised pseudo label generator is designed to equally provide confident pseudo pixel labels for both hard-to-transfer and easyto-transfer target samples. It inhibits the enormous deviation of false pseudo pixel labels under the self-supervision manner. Afterwards, dynamically-searched feature centroids are aligned to narrow category-wise distribution shift. Comprehensive theoretical analysis and experiments show the superiority of our model on the endoscopic dataset and several public datasets.
Towards Fair Knowledge Transfer for Imbalanced Domain Adaptation
Oct 23, 2020
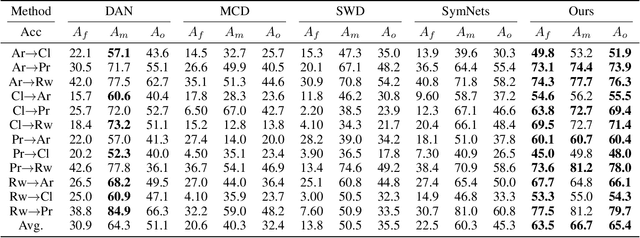
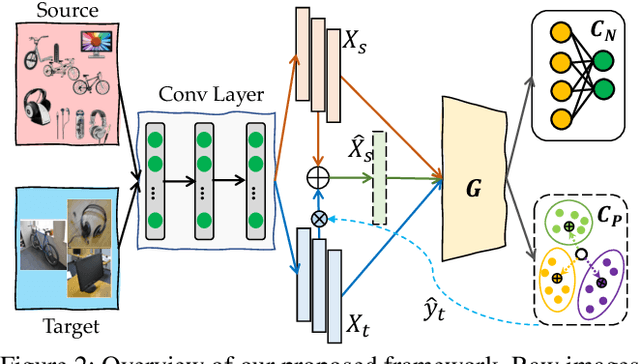
Domain adaptation (DA) becomes an up-and-coming technique to address the insufficient or no annotation issue by exploiting external source knowledge. Existing DA algorithms mainly focus on practical knowledge transfer through domain alignment. Unfortunately, they ignore the fairness issue when the auxiliary source is extremely imbalanced across different categories, which results in severe under-presented knowledge adaptation of minority source set. To this end, we propose a Towards Fair Knowledge Transfer (TFKT) framework to handle the fairness challenge in imbalanced cross-domain learning. Specifically, a novel cross-domain mixup generation is exploited to augment the minority source set with target information to enhance fairness. Moreover, dual distinct classifiers and cross-domain prototype alignment are developed to seek a more robust classifier boundary and mitigate the domain shift. Such three strategies are formulated into a unified framework to address the fairness issue and domain shift challenge. Extensive experiments over two popular benchmarks have verified the effectiveness of our proposed model by comparing to existing state-of-the-art DA models, and especially our model significantly improves over 20% on two benchmarks in terms of the overall accuracy.
Adversarial Dual Distinct Classifiers for Unsupervised Domain Adaptation
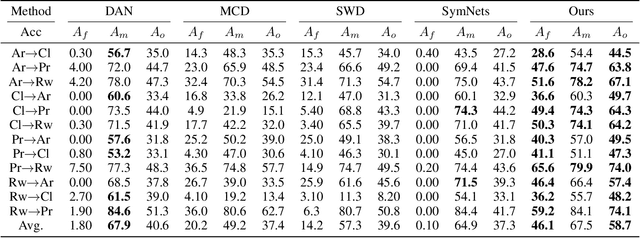
Aug 27, 2020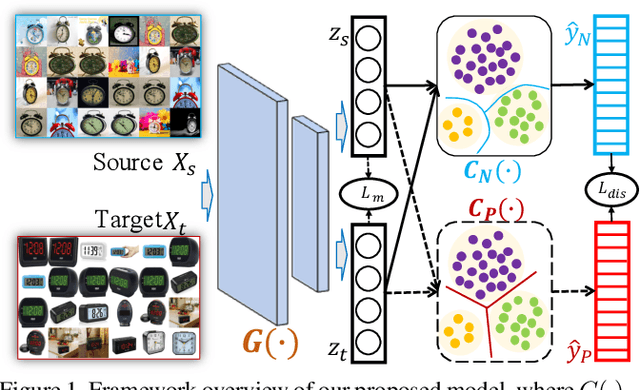
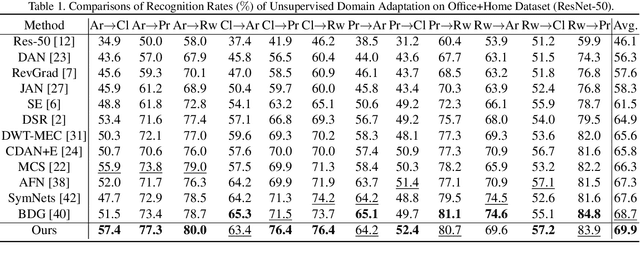
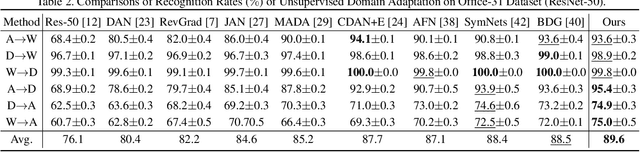
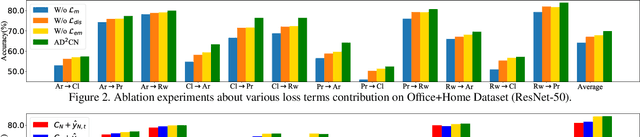
Unsupervised Domain adaptation (UDA) attempts to recognize the unlabeled target samples by building a learning model from a differently-distributed labeled source domain. Conventional UDA concentrates on extracting domain-invariant features through deep adversarial networks. However, most of them seek to match the different domain feature distributions, without considering the task-specific decision boundaries across various classes. In this paper, we propose a novel Adversarial Dual Distinct Classifiers Network (AD$^2$CN) to align the source and target domain data distribution simultaneously with matching task-specific category boundaries. To be specific, a domain-invariant feature generator is exploited to embed the source and target data into a latent common space with the guidance of discriminative cross-domain alignment. Moreover, we naturally design two different structure classifiers to identify the unlabeled target samples over the supervision of the labeled source domain data. Such dual distinct classifiers with various architectures can capture diverse knowledge of the target data structure from different perspectives. Extensive experimental results on several cross-domain visual benchmarks prove the model's effectiveness by comparing it with other state-of-the-art UDA.
Adaptively-Accumulated Knowledge Transfer for Partial Domain Adaptation
Aug 27, 2020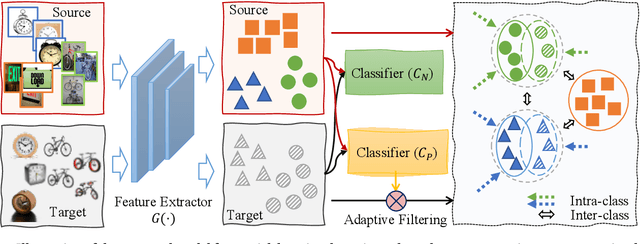
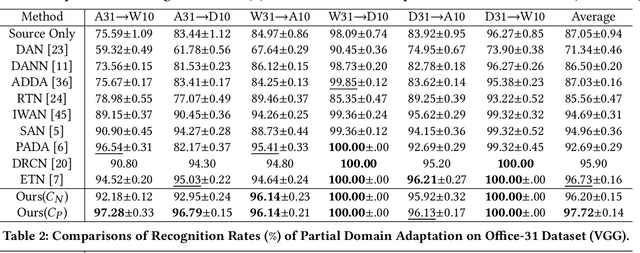
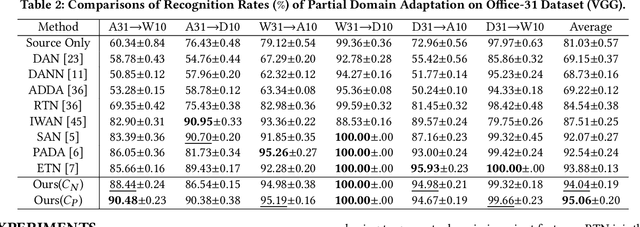
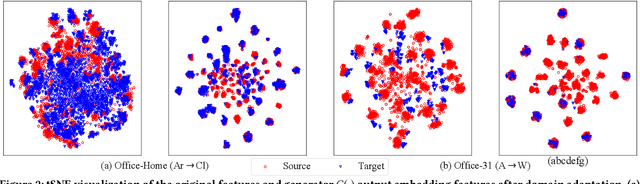
Partial domain adaptation (PDA) attracts appealing attention as it deals with a realistic and challenging problem when the source domain label space substitutes the target domain. Most conventional domain adaptation (DA) efforts concentrate on learning domain-invariant features to mitigate the distribution disparity across domains. However, it is crucial to alleviate the negative influence caused by the irrelevant source domain categories explicitly for PDA. In this work, we propose an Adaptively-Accumulated Knowledge Transfer framework (A$^2$KT) to align the relevant categories across two domains for effective domain adaptation. Specifically, an adaptively-accumulated mechanism is explored to gradually filter out the most confident target samples and their corresponding source categories, promoting positive transfer with more knowledge across two domains. Moreover, a dual distinct classifier architecture consisting of a prototype classifier and a multilayer perceptron classifier is built to capture intrinsic data distribution knowledge across domains from various perspectives. By maximizing the inter-class center-wise discrepancy and minimizing the intra-class sample-wise compactness, the proposed model is able to obtain more domain-invariant and task-specific discriminative representations of the shared categories data. Comprehensive experiments on several partial domain adaptation benchmarks demonstrate the effectiveness of our proposed model, compared with the state-of-the-art PDA methods.
Discriminative Cross-Domain Feature Learning for Partial Domain Adaptation
Aug 26, 2020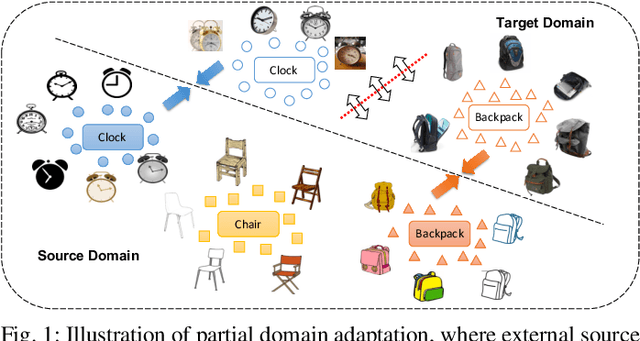

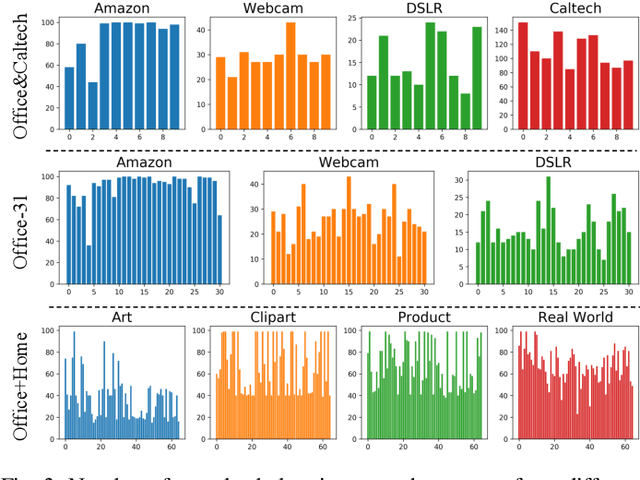
Partial domain adaptation aims to adapt knowledge from a larger and more diverse source domain to a smaller target domain with less number of classes, which has attracted appealing attention. Recent practice on domain adaptation manages to extract effective features by incorporating the pseudo labels for the target domain to better fight off the cross-domain distribution divergences. However, it is essential to align target data with only a small set of source data. In this paper, we develop a novel Discriminative Cross-Domain Feature Learning (DCDF) framework to iteratively optimize target labels with a cross-domain graph in a weighted scheme. Specifically, a weighted cross-domain center loss and weighted cross-domain graph propagation are proposed to couple unlabeled target data to related source samples for discriminative cross-domain feature learning, where irrelevant source centers will be ignored, to alleviate the marginal and conditional disparities simultaneously. Experimental evaluations on several popular benchmarks demonstrate the effectiveness of our proposed approach on facilitating the recognition for the unlabeled target domain, through comparing it to the state-of-the-art partial domain adaptation approaches.
Simultaneous Semantic Alignment Network for Heterogeneous Domain Adaptation
Aug 05, 2020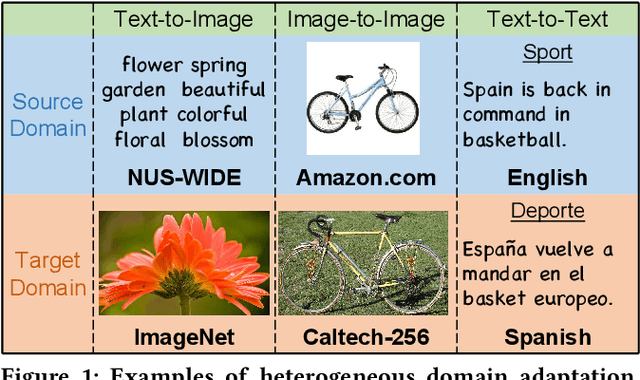
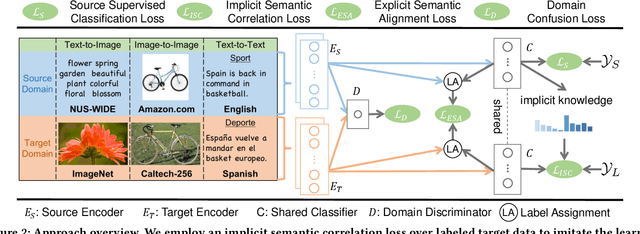
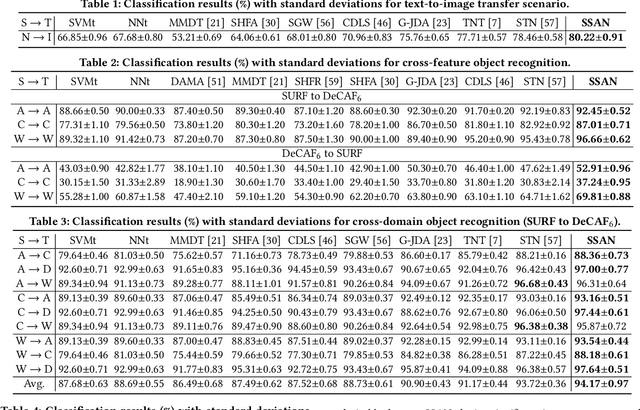
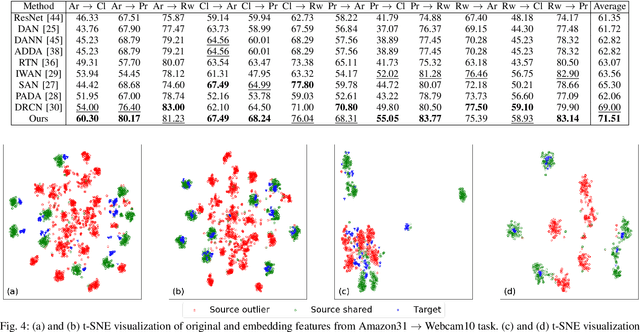
Heterogeneous domain adaptation (HDA) transfers knowledge across source and target domains that present heterogeneities e.g., distinct domain distributions and difference in feature type or dimension. Most previous HDA methods tackle this problem through learning a domain-invariant feature subspace to reduce the discrepancy between domains. However, the intrinsic semantic properties contained in data are under-explored in such alignment strategy, which is also indispensable to achieve promising adaptability. In this paper, we propose a Simultaneous Semantic Alignment Network (SSAN) to simultaneously exploit correlations among categories and align the centroids for each category across domains. In particular, we propose an implicit semantic correlation loss to transfer the correlation knowledge of source categorical prediction distributions to target domain. Meanwhile, by leveraging target pseudo-labels, a robust triplet-centroid alignment mechanism is explicitly applied to align feature representations for each category. Notably, a pseudo-label refinement procedure with geometric similarity involved is introduced to enhance the target pseudo-label assignment accuracy. Comprehensive experiments on various HDA tasks across text-to-image, image-to-image and text-to-text successfully validate the superiority of our SSAN against state-of-the-art HDA methods. The code is publicly available at https://github.com/BIT-DA/SSAN.
Rethink Maximum Mean Discrepancy for Domain Adaptation
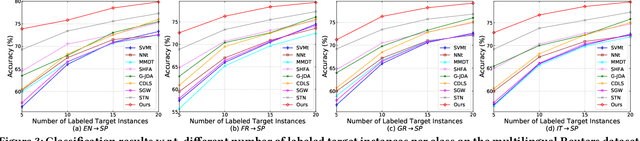
Jul 01, 2020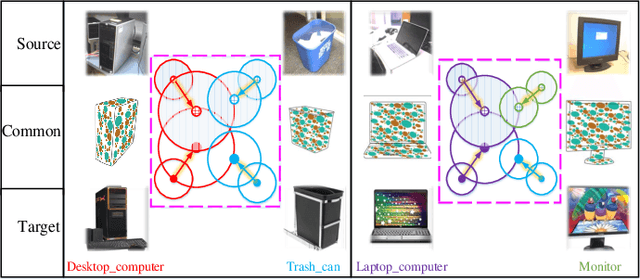
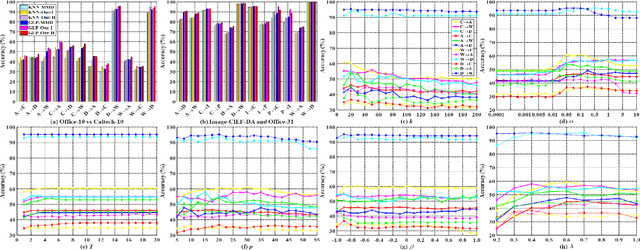
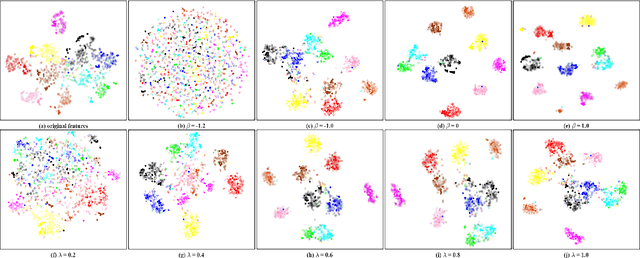

Existing domain adaptation methods aim to reduce the distributional difference between the source and target domains and respect their specific discriminative information, by establishing the Maximum Mean Discrepancy (MMD) and the discriminative distances. However, they usually accumulate to consider those statistics and deal with their relationships by estimating parameters blindly. This paper theoretically proves two essential facts: 1) minimizing the MMD equals to maximize the source and target intra-class distances respectively but jointly minimize their variance with some implicit weights, so that the feature discriminability degrades; 2) the relationship between the intra-class and inter-class distances is as one falls, another rises. Based on this, we propose a novel discriminative MMD. On one hand, we consider the intra-class and inter-class distances alone to remove a redundant parameter, and the revealed weights provide their approximate optimal ranges. On the other hand, we design two different strategies to boost the feature discriminability: 1) we directly impose a trade-off parameter on the implicit intra-class distance in MMD to regulate its change; 2) we impose the similar weights revealed in MMD on inter-class distance and maximize it, then a balanced factor could be introduced to quantitatively leverage the relative importance between the feature transferability and its discriminability. The experiments on several benchmark datasets not only prove the validity of theoretical results but also demonstrate that our approach could perform better than the comparative state-of-art methods substantially.
Mining Label Distribution Drift in Unsupervised Domain Adaptation
Jun 16, 2020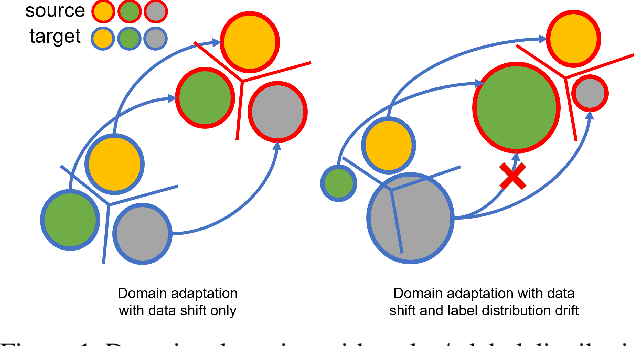
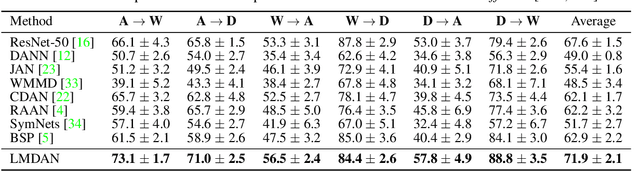
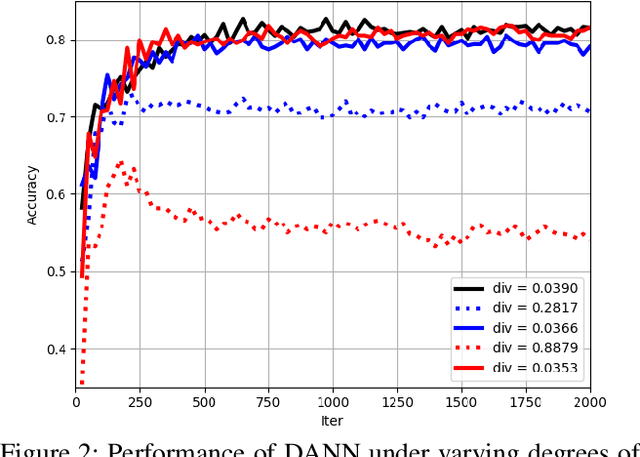
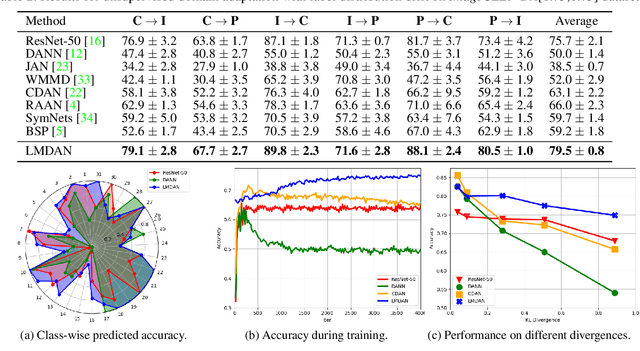
Unsupervised domain adaptation targets to transfer task knowledge from labeled source domain to related yet unlabeled target domain, and is catching extensive interests from academic and industrial areas. Although tremendous efforts along this direction have been made to minimize the domain divergence, unfortunately, most of existing methods only manage part of the picture by aligning feature representations from different domains. Beyond the discrepancy in feature space, the gap between known source label and unknown target label distribution, recognized as label distribution drift, is another crucial factor raising domain divergence, and has not been paid enough attention and well explored. From this point, in this paper, we first experimentally reveal how label distribution drift brings negative effects on current domain adaptation methods. Next, we propose Label distribution Matching Domain Adversarial Network (LMDAN) to handle data distribution shift and label distribution drift jointly. In LMDAN, label distribution drift problem is addressed by the proposed source samples weighting strategy, which select samples to contribute to positive adaptation and avoid negative effects brought by the mismatched in label distribution. Finally, different from general domain adaptation experiments, we modify domain adaptation datasets to create the considerable label distribution drift between source and target domain. Numerical results and empirical model analysis show that LMDAN delivers superior performance compared to other state-of-the-art domain adaptation methods under such scenarios.