 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrasound Vision-Language Alignment via Contrastive Learning
May 04, 2026Ultrasound foundation models have achieved strong performance on structured prediction tasks but remain exclusively vision-based, limiting zero-shot and few-shot transfer to novel tasks where task-specific annotation is scarce. We address this gap with EchoCare-CLIP, a CLIP-style dual-encoder contrastive framework that aligns ultrasound images with clinical text in a shared embedding space. We curate a multi-organ corpus of over 16K image-text pairs spanning breast, liver, lung, and thyroid, with over 78% of captions derived from expert-annotated reports, and complement the remainder with a three-tier template-based and LLM-based caption generation pipeline. We evaluate model configurations spanning two text encoder families (CLIP, BioClinicalBERT) and two caption strategies (template-based, LLM-generated) against OpenAI CLIP and BiomedCLIP baselines. Our trained models consistently improve cross-modal alignment over baselines, with the best configuration achieving a paired alignment score of 0.682. However, stronger alignment does not guarantee better downstream performance: CLIP-based variants with partial fine-tuning achieve the strongest zero-shot classification on external held-out datasets (0.709 on BUSI; 0.626 on AULI), while full end-to-end fine-tuning degrades transfer due to overfitting. On linear probing and few-shot adaptation, model rankings are dataset-dependent, reflecting a trade-off between domain adaptation and representational generalizability. We further show that template-based captions match or outperform LLM-generated captions, suggesting lexical diversity is not a proxy for caption quality. Taken together, our results demonstrate that ultrasound vision-language alignment is achievable from public data alone, but robust clinical transfer requires careful balancing of domain adaptation, encoder capacity, and caption supervision quality.
Rethinking the Practicality of Vision-language-action Model: A Comprehensive Benchmark and An Improved Baseline
Feb 26, 2026Vision-Language-Action (VLA) models have emerged as a generalist robotic agent. However, existing VLAs are hindered by excessive parameter scales, prohibitive pre-training requirements, and limited applicability to diverse embodiments. To improve the practicality of VLAs, we propose a comprehensive benchmark and an improved baseline. First, we propose CEBench, a new benchmark spanning diverse embodiments in both simulation and the real world with consideration of domain randomization. We collect 14.4k simulated trajectories and 1.6k real-world expert-curated trajectories to support training on CEBench. Second, using CEBench as our testbed, we study three critical aspects of VLAs' practicality and offer several key findings. Informed by these findings, we introduce LLaVA-VLA, a lightweight yet powerful VLA designed for practical deployment on consumer-grade GPUs. Architecturally, it integrates a compact VLM backbone with multi-view perception, proprioceptive tokenization, and action chunking. To eliminate reliance on costly pre-training, LLaVA-VLA adopts a two-stage training paradigm including post-training and fine-tuning. Furthermore, LLaVA-VLA extends the action space to unify navigation and manipulation. Experiments across embodiments demonstrate the capabilities of generalization and versatility of LLaVA-VLA , while real-world mobile manipulation experiments establish it as the first end-to-end VLA model for mobile manipulation. We will open-source all datasets, codes, and checkpoints upon acceptance to foster reproducibility and future research.
Towards Fair Cross-Domain Adaptation via Generative Learning
Mar 04, 2020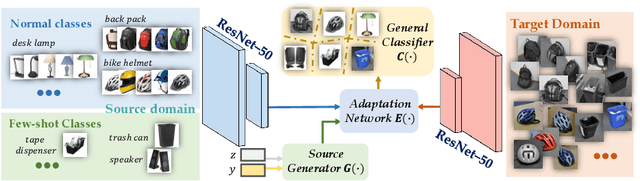
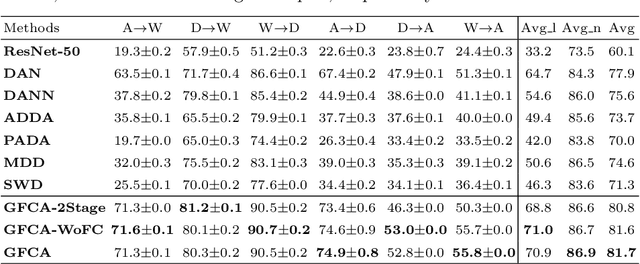
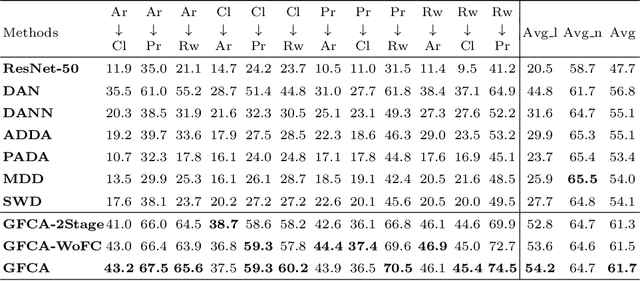
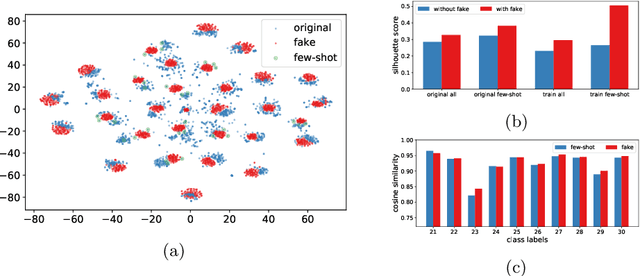
Domain Adaptation (DA) targets at adapting a model trained over the well-labeled source domain to the unlabeled target domain lying in different distributions. Existing DA normally assumes the well-labeled source domain is class-wise balanced, which means the size per source class is relatively similar. However, in real-world applications, labeled samples for some categories in the source domain could be extremely few due to the difficulty of data collection and annotation, which leads to decreasing performance over target domain on those few-shot categories. To perform fair cross-domain adaptation and boost the performance on these minority categories, we develop a novel Generative Few-shot Cross-domain Adaptation (GFCA) algorithm for fair cross-domain classification. Specifically, generative feature augmentation is explored to synthesize effective training data for few-shot source classes, while effective cross-domain alignment aims to adapt knowledge from source to facilitate the target learning. Experimental results on two large cross-domain visual datasets demonstrate the effectiveness of our proposed method on improving both few-shot and overall classification accuracy comparing with the state-of-the-art DA approaches.