 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNITER: Learning UNiversal Image-TExt Representations
Sep 25, 2019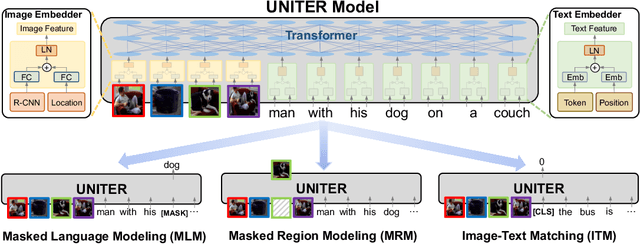

Joint image-text embedding is the bedrock for most Vision-and-Language (V+L) tasks, where multimodality inputs are jointly processed for visual and textual understanding. In this paper, we introduce UNITER, a UNiversal Image-TExt Representation, learned through large-scale pre-training over four image-text datasets (COCO, Visual Genome, Conceptual Captions, and SBU Captions), which can power heterogeneous downstream V+L tasks with joint multimodal embeddings. We design three pre-training tasks: Masked Language Modeling (MLM), Image-Text Matching (ITM), and Masked Region Modeling (MRM, with three variants). Different from concurrent work on multimodal pre-training that apply joint random masking to both modalities, we use conditioned masking on pre-training tasks (i.e., masked language/region modeling is conditioned on full observation of image/text). Comprehensive analysis shows that conditioned masking yields better performance than unconditioned masking. We also conduct a thorough ablation study to find an optimal setting for the combination of pre-training tasks. Extensive experiments show that UNITER achieves new state of the art across six V+L tasks (over nine datasets), including Visual Question Answering, Image-Text Retrieval, Referring Expression Comprehension, Visual Commonsense Reasoning, Visual Entailment, and NLVR2.
Contrastively Smoothed Class Alignment for Unsupervised Domain Adaptation
Sep 13, 2019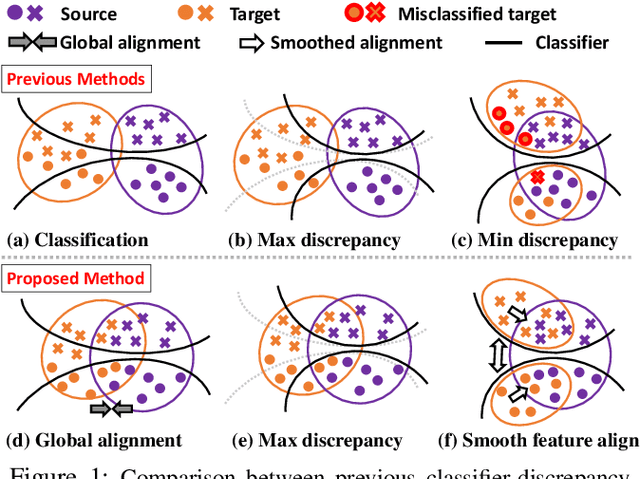
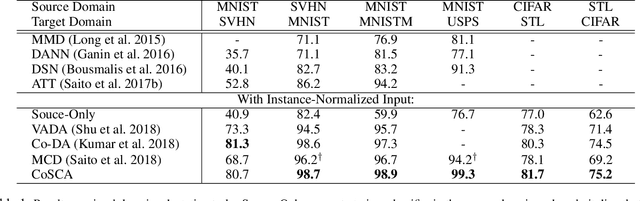
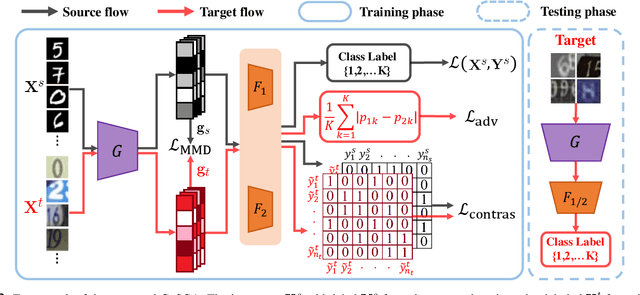
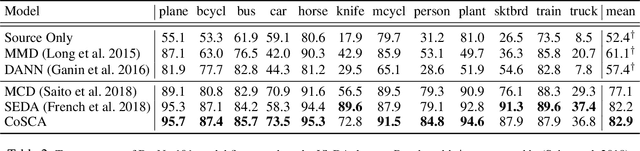
Recent unsupervised approaches to domain adaptation primarily focus on minimizing the gap between the source and the target domains through refining the feature generator, in order to learn a better alignment between the two domains. This minimization can be achieved via a domain classifier to detect target-domain features that are divergent from source-domain features. However, by optimizing via such domain classification discrepancy, ambiguous target samples that are not smoothly distributed on the low-dimensional data manifold are often missed. To solve this issue, we propose a novel Contrastively Smoothed Class Alignment (CoSCA) model, that explicitly incorporates both intra- and inter-class domain discrepancy to better align ambiguous target samples with the source domain. CoSCA estimates the underlying label hypothesis of target samples, and simultaneously adapts their feature representations by optimizing a proposed contrastive loss. In addition, Maximum Mean Discrepancy (MMD) is utilized to directly match features between source and target samples for better global alignment. Experiments on several benchmark datasets demonstrate that CoSCA can outperform state-of-the-art approaches for unsupervised domain adaptation by producing more discriminative features.
What Makes A Good Story? Designing Composite Rewards for Visual Storytelling
Sep 11, 2019
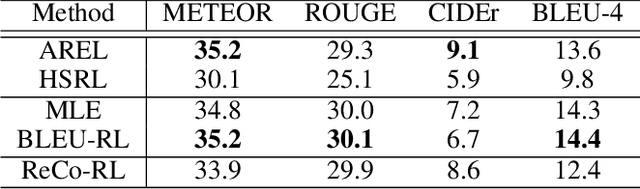
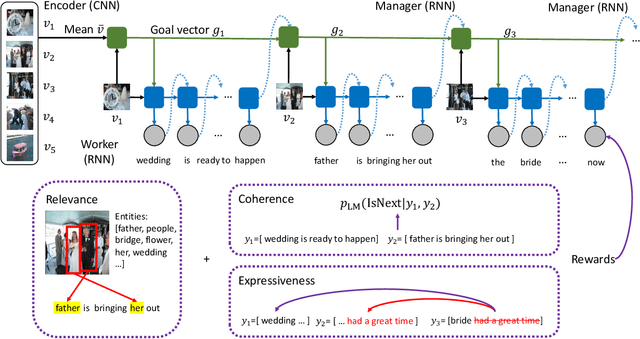

Previous storytelling approaches mostly focused on optimizing traditional metrics such as BLEU, ROUGE and CIDEr. In this paper, we re-examine this problem from a different angle, by looking deep into what defines a realistically-natural and topically-coherent story. To this end, we propose three assessment criteria: relevance, coherence and expressiveness, which we observe through empirical analysis could constitute a "high-quality" story to the human eye. Following this quality guideline, we propose a reinforcement learning framework, ReCo-RL, with reward functions designed to capture the essence of these quality criteria. Experiments on the Visual Storytelling Dataset (VIST) with both automatic and human evaluations demonstrate that our ReCo-RL model achieves better performance than state-of-the-art baselines on both traditional metrics and the proposed new criteria.
TIGEr: Text-to-Image Grounding for Image Caption Evaluation
Sep 04, 2019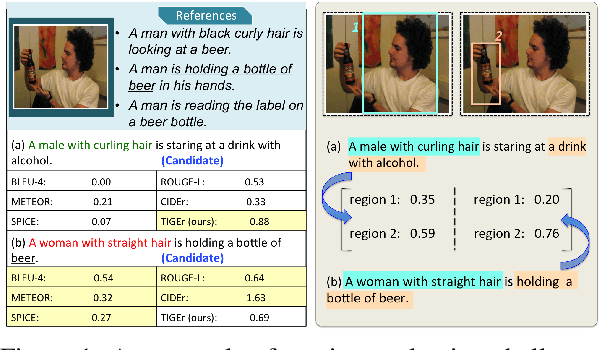
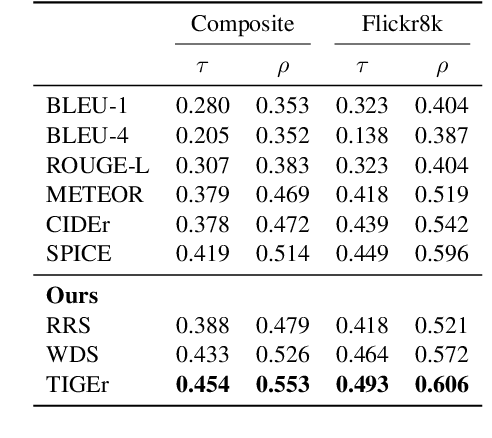
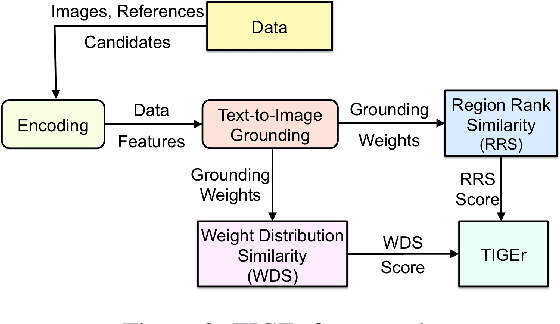
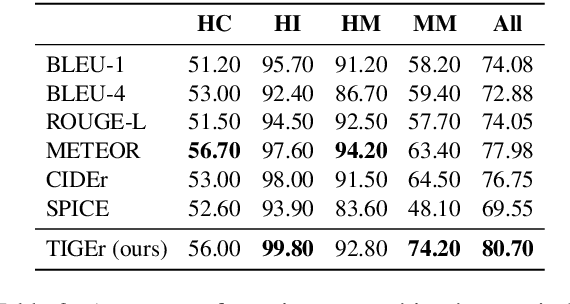
This paper presents a new metric called TIGEr for the automatic evaluation of image captioning systems. Popular metrics, such as BLEU and CIDEr, are based solely on text matching between reference captions and machine-generated captions, potentially leading to biased evaluations because references may not fully cover the image content and natural language is inherently ambiguous. Building upon a machine-learned text-image grounding model, TIGEr allows to evaluate caption quality not only based on how well a caption represents image content, but also on how well machine-generated captions match human-generated captions. Our empirical tests show that TIGEr has a higher consistency with human judgments than alternative existing metrics. We also comprehensively assess the metric's effectiveness in caption evaluation by measuring the correlation between human judgments and metric scores.
Domain Adaptive Text Style Transfer
Aug 25, 2019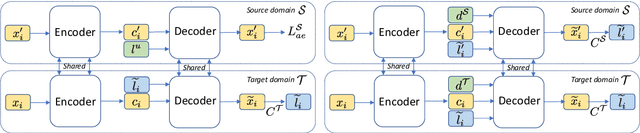
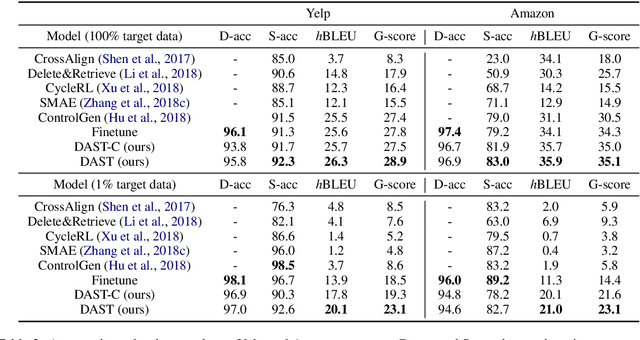
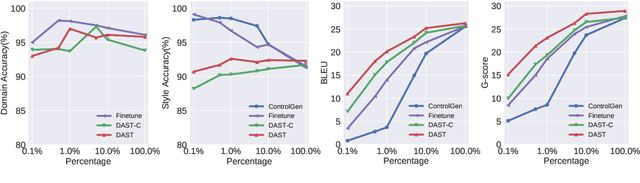
Text style transfer without parallel data has achieved some practical success. However, in the scenario where less data is available, these methods may yield poor performance. In this paper, we examine domain adaptation for text style transfer to leverage massively available data from other domains. These data may demonstrate domain shift, which impedes the benefits of utilizing such data for training. To address this challenge, we propose simple yet effective domain adaptive text style transfer models, enabling domain-adaptive information exchange. The proposed models presumably learn from the source domain to: (i) distinguish stylized information and generic content information; (ii) maximally preserve content information; and (iii) adaptively transfer the styles in a domain-aware manner. We evaluate the proposed models on two style transfer tasks (sentiment and formality) over multiple target domains where only limited non-parallel data is available. Extensive experiments demonstrate the effectiveness of the proposed model compared to the baselines.
Patient Knowledge Distillation for BERT Model Compression
Aug 25, 2019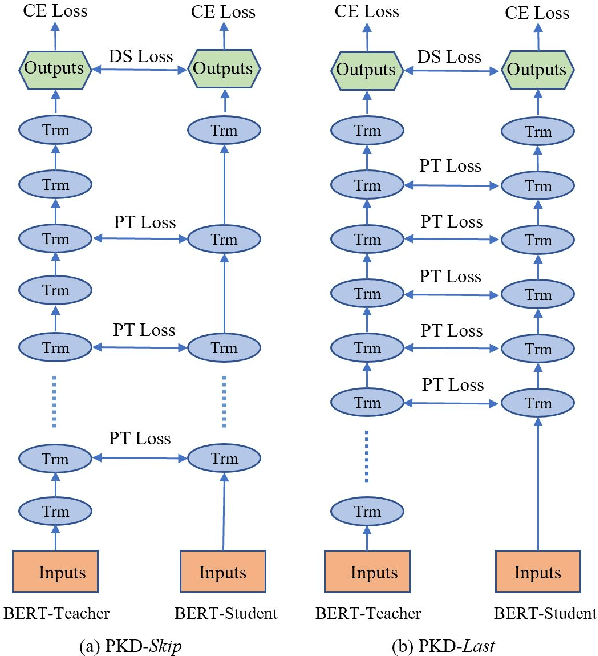
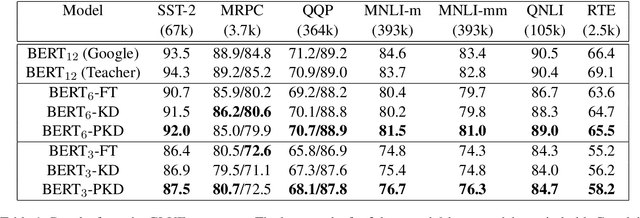
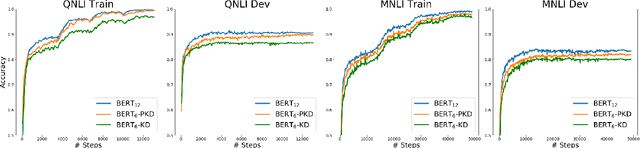

Pre-trained language models such as BERT have proven to be highly effective for natural language processing (NLP) tasks. However, the high demand for computing resources in training such models hinders their application in practice. In order to alleviate this resource hunger in large-scale model training, we propose a Patient Knowledge Distillation approach to compress an original large model (teacher) into an equally-effective lightweight shallow network (student). Different from previous knowledge distillation methods, which only use the output from the last layer of the teacher network for distillation, our student model patiently learns from multiple intermediate layers of the teacher model for incremental knowledge extraction, following two strategies: ($i$) PKD-Last: learning from the last $k$ layers; and ($ii$) PKD-Skip: learning from every $k$ layers. These two patient distillation schemes enable the exploitation of rich information in the teacher's hidden layers, and encourage the student model to patiently learn from and imitate the teacher through a multi-layer distillation process. Empirically, this translates into improved results on multiple NLP tasks with significant gain in training efficiency, without sacrificing model accuracy.
Adversarial Domain Adaptation for Machine Reading Comprehension
Aug 24, 2019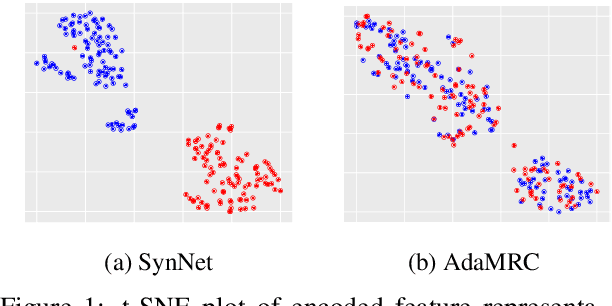
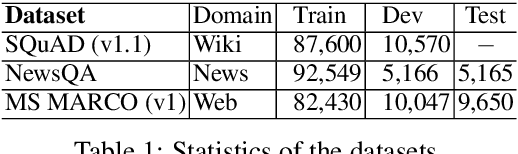
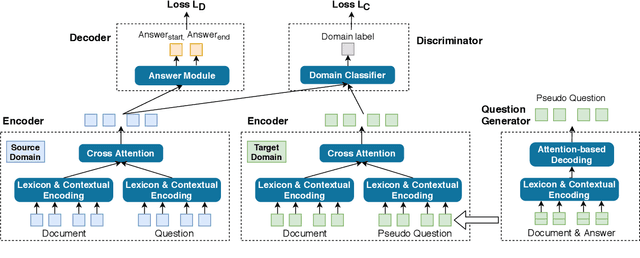
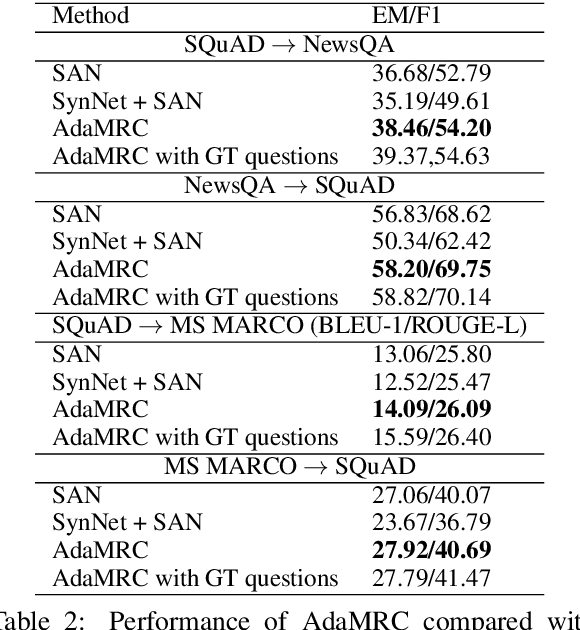
In this paper, we focus on unsupervised domain adaptation for Machine Reading Comprehension (MRC), where the source domain has a large amount of labeled data, while only unlabeled passages are available in the target domain. To this end, we propose an Adversarial Domain Adaptation framework (AdaMRC), where ($i$) pseudo questions are first generated for unlabeled passages in the target domain, and then ($ii$) a domain classifier is incorporated into an MRC model to predict which domain a given passage-question pair comes from. The classifier and the passage-question encoder are jointly trained using adversarial learning to enforce domain-invariant representation learning. Comprehensive evaluations demonstrate that our approach ($i$) is generalizable to different MRC models and datasets, ($ii$) can be combined with pre-trained large-scale language models (such as ELMo and BERT), and ($iii$) can be extended to semi-supervised learning.
Tactical Rewind: Self-Correction via Backtracking in Vision-and-Language Navigation
Apr 02, 2019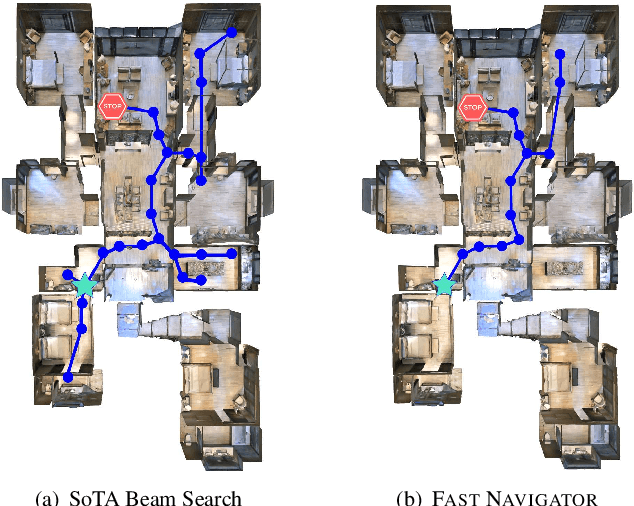
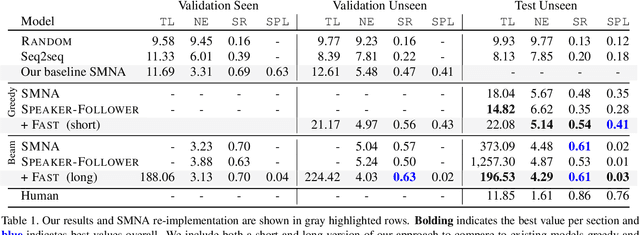
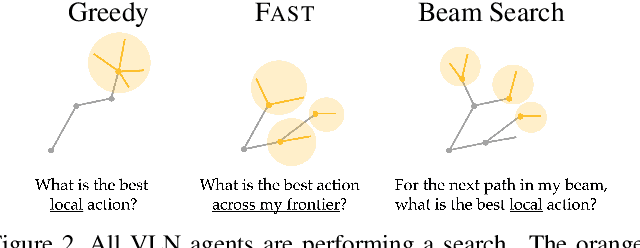
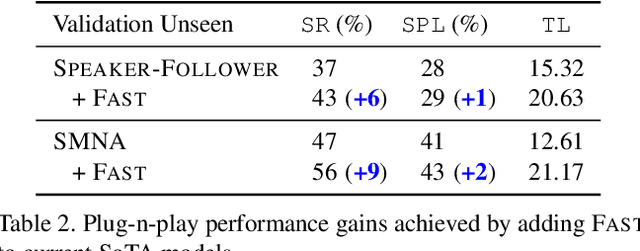
We present the Frontier Aware Search with backTracking (FAST) Navigator, a general framework for action decoding, that achieves state-of-the-art results on the Room-to-Room (R2R) Vision-and-Language navigation challenge of Anderson et. al. (2018). Given a natural language instruction and photo-realistic image views of a previously unseen environment, the agent was tasked with navigating from source to target location as quickly as possible. While all current approaches make local action decisions or score entire trajectories using beam search, ours balances local and global signals when exploring an unobserved environment. Importantly, this lets us act greedily but use global signals to backtrack when necessary. Applying FAST framework to existing state-of-the-art models achieved a 17% relative gain, an absolute 6% gain on Success rate weighted by Path Length (SPL).
Relation-aware Graph Attention Network for Visual Question Answering
Mar 29, 2019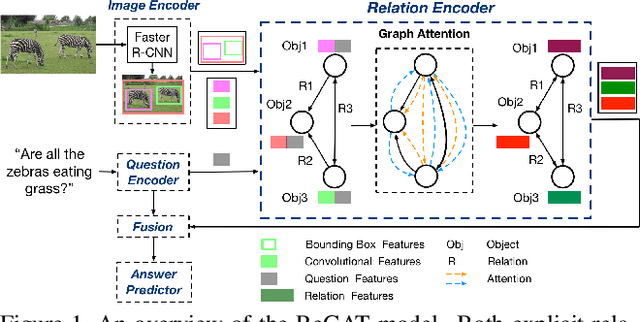

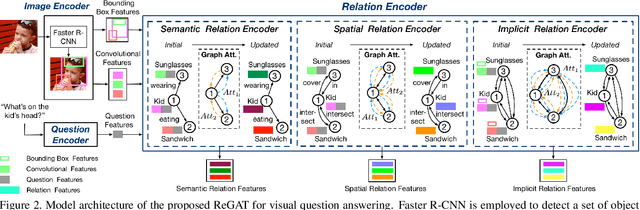
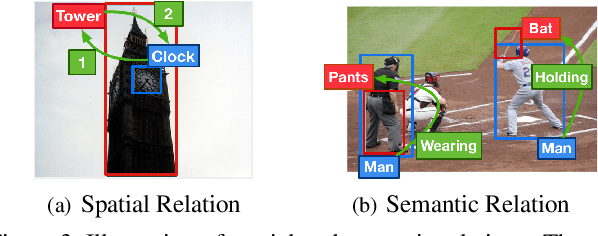
In order to answer semantically-complicated questions about an image, a Visual Question Answering (VQA) model needs to fully understand the visual scene in the image, especially the interactive dynamics between different objects. We propose a Relation-aware Graph Attention Network (ReGAT), which encodes each image into a graph and models multi-type inter-object relations via a graph attention mechanism, to learn question-adaptive relation representations. Two types of visual object relations are explored: (i) Explicit Relations that represent geometric positions and semantic interactions between objects; and (ii) Implicit Relations that capture the hidden dynamics between image regions. Experiments demonstrate that ReGAT outperforms prior state-of-the-art approaches on both VQA 2.0 and VQA-CP v2 datasets. We further show that ReGAT is compatible to existing VQA architectures, and can be used as a generic relation encoder to boost the model performance for VQA.
Topic-Guided Variational Autoencoders for Text Generation
Mar 17, 2019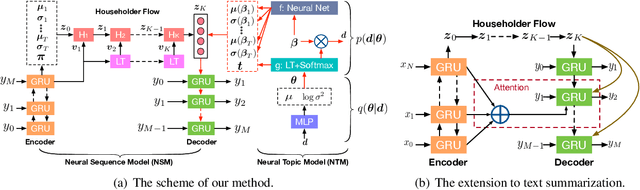

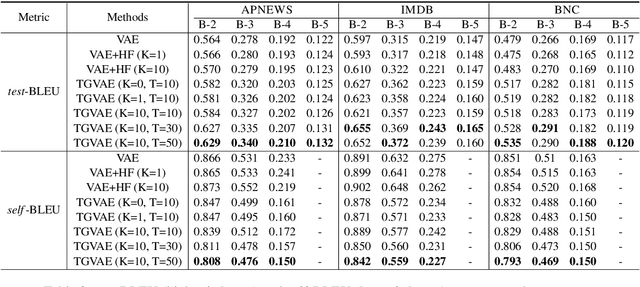
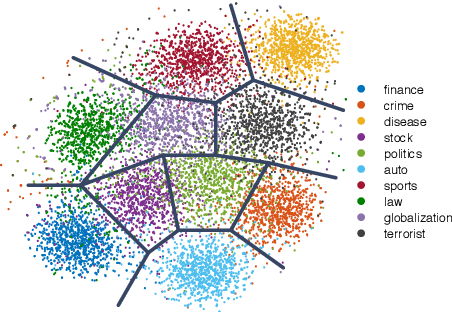
We propose a topic-guided variational autoencoder (TGVAE) model for text generation. Distinct from existing variational autoencoder (VAE) based approaches, which assume a simple Gaussian prior for the latent code, our model specifies the prior as a Gaussian mixture model (GMM) parametrized by a neural topic module. Each mixture component corresponds to a latent topic, which provides guidance to generate sentences under the topic. The neural topic module and the VAE-based neural sequence module in our model are learned jointly. In particular, a sequence of invertible Householder transformations is applied to endow the approximate posterior of the latent code with high flexibility during model inference. Experimental results show that our TGVAE outperforms alternative approaches on both unconditional and conditional text generation, which can generate semantically-meaningful sentences with various topics.