 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference-Conditioned Super-Resolution by Neural Texture Transfer
Apr 10, 2018
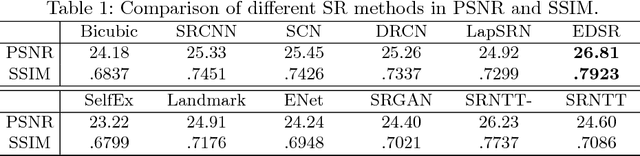
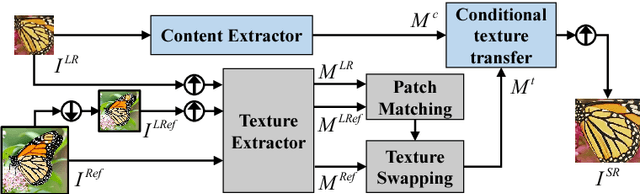
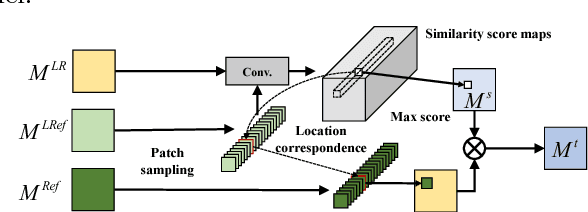
With the recent advancement in deep learning, we have witnessed a great progress in single image super-resolution. However, due to the significant information loss of the image downscaling process, it has become extremely challenging to further advance the state-of-the-art, especially for large upscaling factors. This paper explores a new research direction in super resolution, called reference-conditioned super-resolution, in which a reference image containing desired high-resolution texture details is provided besides the low-resolution image. We focus on transferring the high-resolution texture from reference images to the super-resolution process without the constraint of content similarity between reference and target images, which is a key difference from previous example-based methods. Inspired by recent work on image stylization, we address the problem via neural texture transfer. We design an end-to-end trainable deep model which generates detail enriched results by adaptively fusing the content from the low-resolution image with the texture patterns from the reference image. We create a benchmark dataset for the general research of reference-based super-resolution, which contains reference images paired with low-resolution inputs with varying degrees of similarity. Both objective and subjective evaluations demonstrate the great potential of using reference images as well as the superiority of our results over other state-of-the-art methods.
Multi-Content GAN for Few-Shot Font Style Transfer
Dec 01, 2017
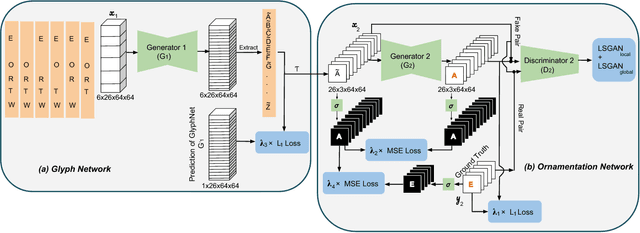

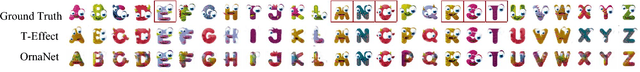
In this work, we focus on the challenge of taking partial observations of highly-stylized text and generalizing the observations to generate unobserved glyphs in the ornamented typeface. To generate a set of multi-content images following a consistent style from very few examples, we propose an end-to-end stacked conditional GAN model considering content along channels and style along network layers. Our proposed network transfers the style of given glyphs to the contents of unseen ones, capturing highly stylized fonts found in the real-world such as those on movie posters or infographics. We seek to transfer both the typographic stylization (ex. serifs and ears) as well as the textual stylization (ex. color gradients and effects.) We base our experiments on our collected data set including 10,000 fonts with different styles and demonstrate effective generalization from a very small number of observed glyphs.
Universal Style Transfer via Feature Transforms
Nov 17, 2017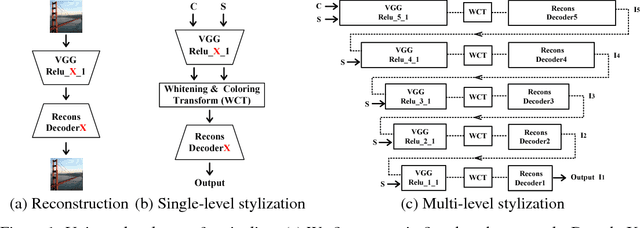



Universal style transfer aims to transfer arbitrary visual styles to content images. Existing feed-forward based methods, while enjoying the inference efficiency, are mainly limited by inability of generalizing to unseen styles or compromised visual quality. In this paper, we present a simple yet effective method that tackles these limitations without training on any pre-defined styles. The key ingredient of our method is a pair of feature transforms, whitening and coloring, that are embedded to an image reconstruction network. The whitening and coloring transforms reflect a direct matching of feature covariance of the content image to a given style image, which shares similar spirits with the optimization of Gram matrix based cost in neural style transfer. We demonstrate the effectiveness of our algorithm by generating high-quality stylized images with comparisons to a number of recent methods. We also analyze our method by visualizing the whitened features and synthesizing textures via simple feature coloring.
Visually-Aware Fashion Recommendation and Design with Generative Image Models
Nov 07, 2017
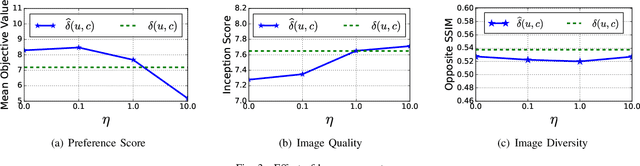

Building effective recommender systems for domains like fashion is challenging due to the high level of subjectivity and the semantic complexity of the features involved (i.e., fashion styles). Recent work has shown that approaches to `visual' recommendation (e.g.~clothing, art, etc.) can be made more accurate by incorporating visual signals directly into the recommendation objective, using `off-the-shelf' feature representations derived from deep networks. Here, we seek to extend this contribution by showing that recommendation performance can be significantly improved by learning `fashion aware' image representations directly, i.e., by training the image representation (from the pixel level) and the recommender system jointly; this contribution is related to recent work using Siamese CNNs, though we are able to show improvements over state-of-the-art recommendation techniques such as BPR and variants that make use of pre-trained visual features. Furthermore, we show that our model can be used \emph{generatively}, i.e., given a user and a product category, we can generate new images (i.e., clothing items) that are most consistent with their personal taste. This represents a first step towards building systems that go beyond recommending existing items from a product corpus, but which can be used to suggest styles and aid the design of new products.
Robust Lane Tracking with Multi-mode Observation Model and Particle Filtering
Jun 28, 2017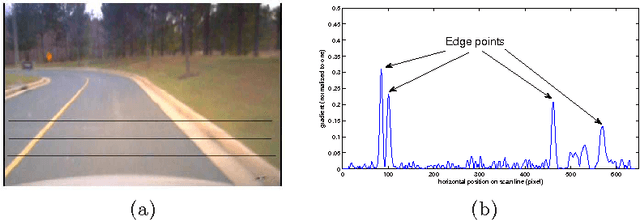


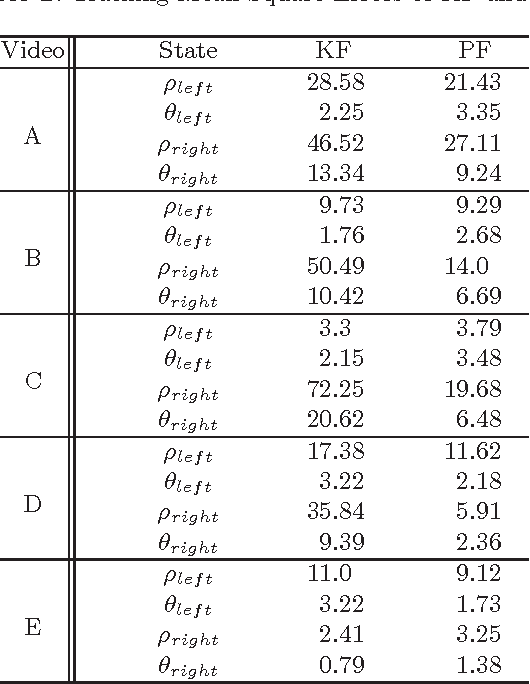
Automatic lane tracking involves estimating the underlying signal from a sequence of noisy signal observations. Many models and methods have been proposed for lane tracking, and dynamic targets tracking in general. The Kalman Filter is a widely used method that works well on linear Gaussian models. But this paper shows that Kalman Filter is not suitable for lane tracking, because its Gaussian observation model cannot faithfully represent the procured observations. We propose using a Particle Filter on top of a novel multiple mode observation model. Experiments show that our method produces superior performance to a conventional Kalman Filter.
Trimming and Improving Skip-thought Vectors
Jun 09, 2017

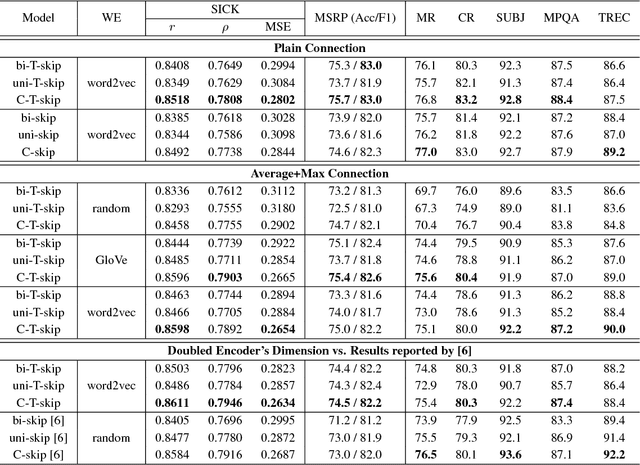
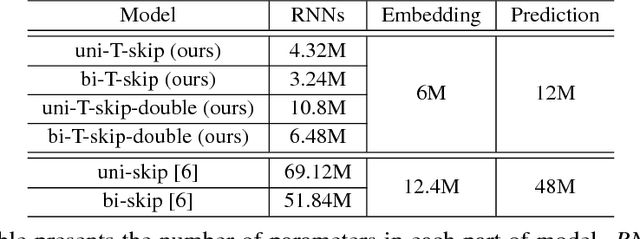
The skip-thought model has been proven to be effective at learning sentence representations and capturing sentence semantics. In this paper, we propose a suite of techniques to trim and improve it. First, we validate a hypothesis that, given a current sentence, inferring the previous and inferring the next sentence provide similar supervision power, therefore only one decoder for predicting the next sentence is preserved in our trimmed skip-thought model. Second, we present a connection layer between encoder and decoder to help the model to generalize better on semantic relatedness tasks. Third, we found that a good word embedding initialization is also essential for learning better sentence representations. We train our model unsupervised on a large corpus with contiguous sentences, and then evaluate the trained model on 7 supervised tasks, which includes semantic relatedness, paraphrase detection, and text classification benchmarks. We empirically show that, our proposed model is a faster, lighter-weight and equally powerful alternative to the original skip-thought model.
Rethinking Skip-thought: A Neighborhood based Approach
Jun 09, 2017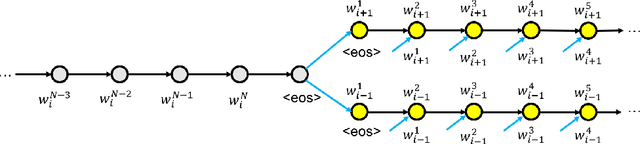
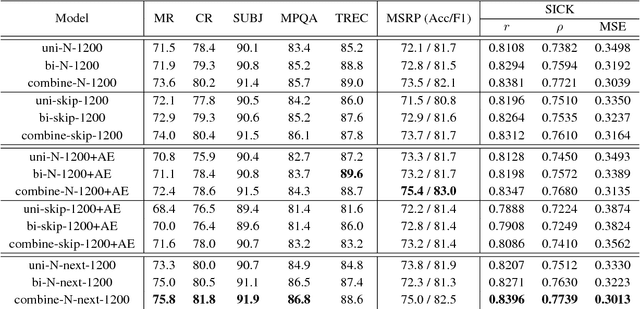
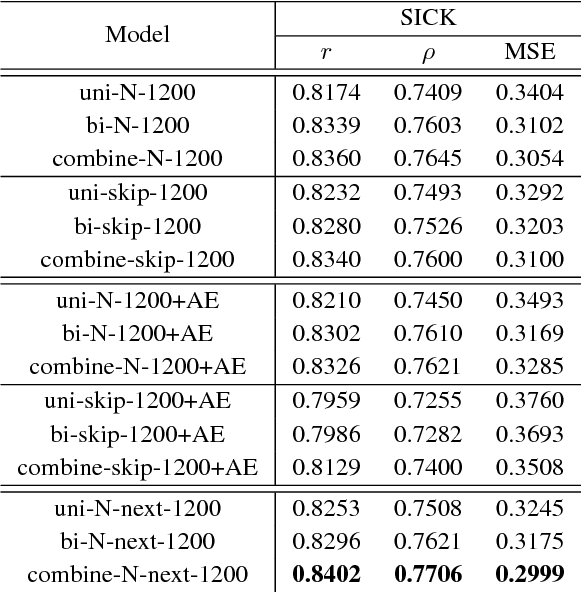

We study the skip-thought model with neighborhood information as weak supervision. More specifically, we propose a skip-thought neighbor model to consider the adjacent sentences as a neighborhood. We train our skip-thought neighbor model on a large corpus with continuous sentences, and then evaluate the trained model on 7 tasks, which include semantic relatedness, paraphrase detection, and classification benchmarks. Both quantitative comparison and qualitative investigation are conducted. We empirically show that, our skip-thought neighbor model performs as well as the skip-thought model on evaluation tasks. In addition, we found that, incorporating an autoencoder path in our model didn't aid our model to perform better, while it hurts the performance of the skip-thought model.
AMC: Attention guided Multi-modal Correlation Learning for Image Search
Apr 03, 2017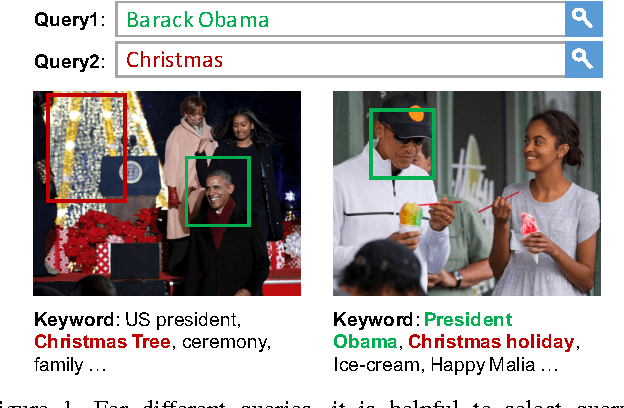

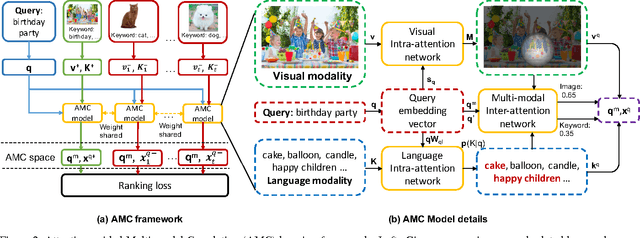
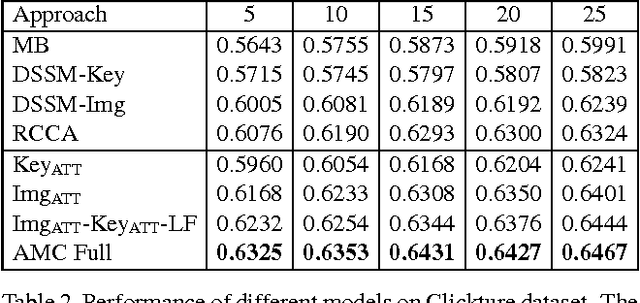
Given a user's query, traditional image search systems rank images according to its relevance to a single modality (e.g., image content or surrounding text). Nowadays, an increasing number of images on the Internet are available with associated meta data in rich modalities (e.g., titles, keywords, tags, etc.), which can be exploited for better similarity measure with queries. In this paper, we leverage visual and textual modalities for image search by learning their correlation with input query. According to the intent of query, attention mechanism can be introduced to adaptively balance the importance of different modalities. We propose a novel Attention guided Multi-modal Correlation (AMC) learning method which consists of a jointly learned hierarchy of intra and inter-attention networks. Conditioned on query's intent, intra-attention networks (i.e., visual intra-attention network and language intra-attention network) attend on informative parts within each modality; a multi-modal inter-attention network promotes the importance of the most query-relevant modalities. In experiments, we evaluate AMC models on the search logs from two real world image search engines and show a significant boost on the ranking of user-clicked images in search results. Additionally, we extend AMC models to caption ranking task on COCO dataset and achieve competitive results compared with recent state-of-the-arts.
Diversified Texture Synthesis with Feed-forward Networks
Mar 05, 2017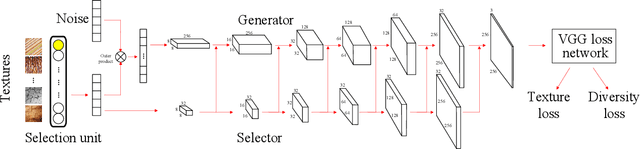


Recent progresses on deep discriminative and generative modeling have shown promising results on texture synthesis. However, existing feed-forward based methods trade off generality for efficiency, which suffer from many issues, such as shortage of generality (i.e., build one network per texture), lack of diversity (i.e., always produce visually identical output) and suboptimality (i.e., generate less satisfying visual effects). In this work, we focus on solving these issues for improved texture synthesis. We propose a deep generative feed-forward network which enables efficient synthesis of multiple textures within one single network and meaningful interpolation between them. Meanwhile, a suite of important techniques are introduced to achieve better convergence and diversity. With extensive experiments, we demonstrate the effectiveness of the proposed model and techniques for synthesizing a large number of textures and show its applications with the stylization.
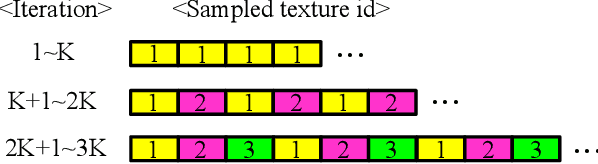
Learning a Mixture of Deep Networks for Single Image Super-Resolution
Jan 03, 2017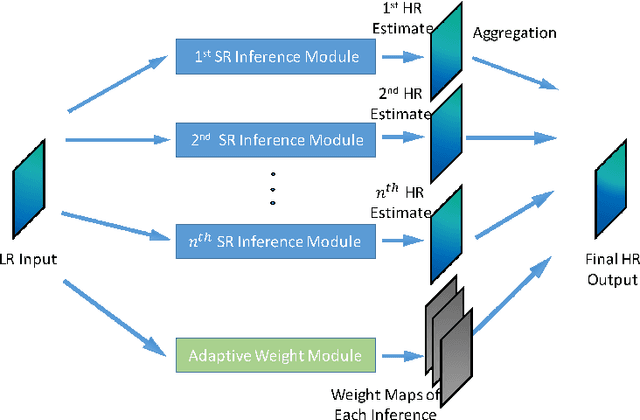
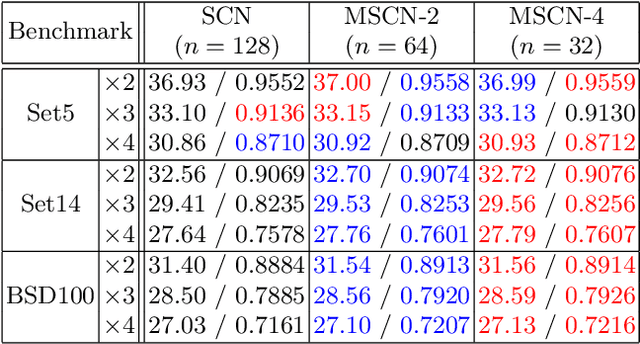
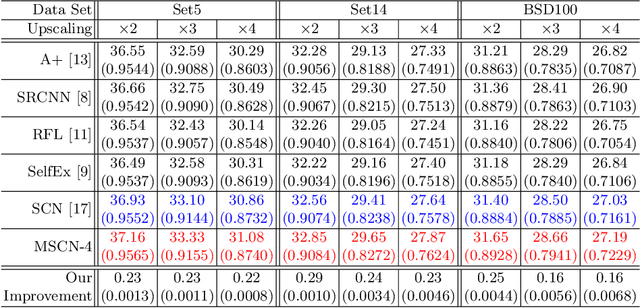
Single image super-resolution (SR) is an ill-posed problem which aims to recover high-resolution (HR) images from their low-resolution (LR) observations. The crux of this problem lies in learning the complex mapping between low-resolution patches and the corresponding high-resolution patches. Prior arts have used either a mixture of simple regression models or a single non-linear neural network for this propose. This paper proposes the method of learning a mixture of SR inference modules in a unified framework to tackle this problem. Specifically, a number of SR inference modules specialized in different image local patterns are first independently applied on the LR image to obtain various HR estimates, and the resultant HR estimates are adaptively aggregated to form the final HR image. By selecting neural networks as the SR inference module, the whole procedure can be incorporated into a unified network and be optimized jointly. Extensive experiments are conducted to investigate the relation between restoration performance and different network architectures. Compared with other current image SR approaches, our proposed method achieves state-of-the-arts restoration results on a wide range of images consistently while allowing more flexible design choices. The source codes are available in http://www.ifp.illinois.edu/~dingliu2/accv2016.