 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025



Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
Open-World Dynamic Prompt and Continual Visual Representation Learning
Sep 09, 2024



The open world is inherently dynamic, characterized by ever-evolving concepts and distributions. Continual learning (CL) in this dynamic open-world environment presents a significant challenge in effectively generalizing to unseen test-time classes. To address this challenge, we introduce a new practical CL setting tailored for open-world visual representation learning. In this setting, subsequent data streams systematically introduce novel classes that are disjoint from those seen in previous training phases, while also remaining distinct from the unseen test classes. In response, we present Dynamic Prompt and Representation Learner (DPaRL), a simple yet effective Prompt-based CL (PCL) method. Our DPaRL learns to generate dynamic prompts for inference, as opposed to relying on a static prompt pool in previous PCL methods. In addition, DPaRL jointly learns dynamic prompt generation and discriminative representation at each training stage whereas prior PCL methods only refine the prompt learning throughout the process. Our experimental results demonstrate the superiority of our approach, surpassing state-of-the-art methods on well-established open-world image retrieval benchmarks by an average of 4.7\% improvement in Recall@1 performance.
NAVERO: Unlocking Fine-Grained Semantics for Video-Language Compositionality
Aug 18, 2024



We study the capability of Video-Language (VidL) models in understanding compositions between objects, attributes, actions and their relations. Composition understanding becomes particularly challenging for video data since the compositional relations rapidly change over time in videos. We first build a benchmark named AARO to evaluate composition understanding related to actions on top of spatial concepts. The benchmark is constructed by generating negative texts with incorrect action descriptions for a given video and the model is expected to pair a positive text with its corresponding video. Furthermore, we propose a training method called NAVERO which utilizes video-text data augmented with negative texts to enhance composition understanding. We also develop a negative-augmented visual-language matching loss which is used explicitly to benefit from the generated negative text. We compare NAVERO with other state-of-the-art methods in terms of compositional understanding as well as video-text retrieval performance. NAVERO achieves significant improvement over other methods for both video-language and image-language composition understanding, while maintaining strong performance on traditional text-video retrieval tasks.
Mixed-Query Transformer: A Unified Image Segmentation Architecture
Apr 06, 2024



Existing unified image segmentation models either employ a unified architecture across multiple tasks but use separate weights tailored to each dataset, or apply a single set of weights to multiple datasets but are limited to a single task. In this paper, we introduce the Mixed-Query Transformer (MQ-Former), a unified architecture for multi-task and multi-dataset image segmentation using a single set of weights. To enable this, we propose a mixed query strategy, which can effectively and dynamically accommodate different types of objects without heuristic designs. In addition, the unified architecture allows us to use data augmentation with synthetic masks and captions to further improve model generalization. Experiments demonstrate that MQ-Former can not only effectively handle multiple segmentation datasets and tasks compared to specialized state-of-the-art models with competitive performance, but also generalize better to open-set segmentation tasks, evidenced by over 7 points higher performance than the prior art on the open-vocabulary SeginW benchmark.
Musketeer (All for One, and One for All): A Generalist Vision-Language Model with Task Explanation Prompts
May 11, 2023We present a sequence-to-sequence vision-language model whose parameters are jointly trained on all tasks (all for one) and fully shared among multiple tasks (one for all), resulting in a single model which we named Musketeer. The integration of knowledge across heterogeneous tasks is enabled by a novel feature called Task Explanation Prompt (TEP). TEP reduces interference among tasks, allowing the model to focus on their shared structure. With a single model, Musketeer achieves results comparable to or better than strong baselines trained on single tasks, almost uniformly across multiple tasks.
PolyFormer: Referring Image Segmentation as Sequential Polygon Generation
Feb 14, 2023



In this work, instead of directly predicting the pixel-level segmentation masks, the problem of referring image segmentation is formulated as sequential polygon generation, and the predicted polygons can be later converted into segmentation masks. This is enabled by a new sequence-to-sequence framework, Polygon Transformer (PolyFormer), which takes a sequence of image patches and text query tokens as input, and outputs a sequence of polygon vertices autoregressively. For more accurate geometric localization, we propose a regression-based decoder, which predicts the precise floating-point coordinates directly, without any coordinate quantization error. In the experiments, PolyFormer outperforms the prior art by a clear margin, e.g., 5.40% and 4.52% absolute improvements on the challenging RefCOCO+ and RefCOCOg datasets. It also shows strong generalization ability when evaluated on the referring video segmentation task without fine-tuning, e.g., achieving competitive 61.5% J&F on the Ref-DAVIS17 dataset.
Semi-supervised Vision Transformers at Scale
Aug 11, 2022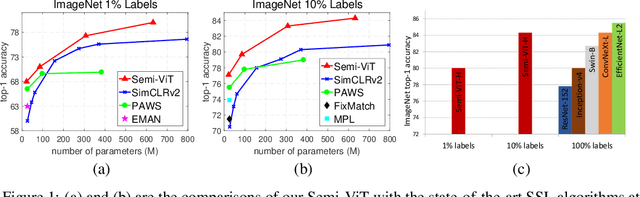
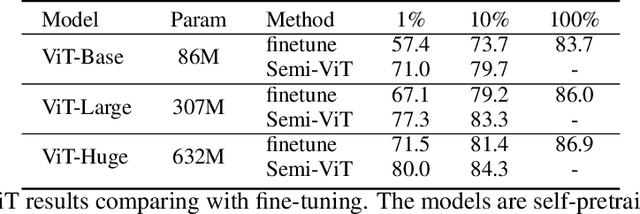
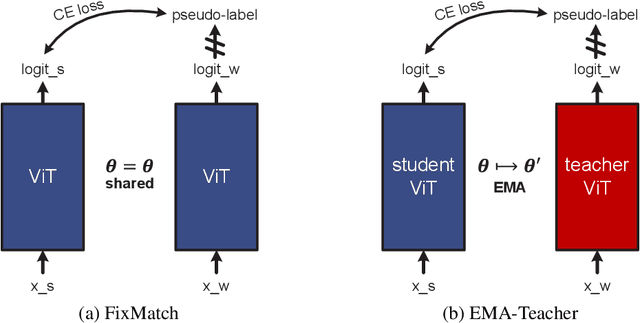
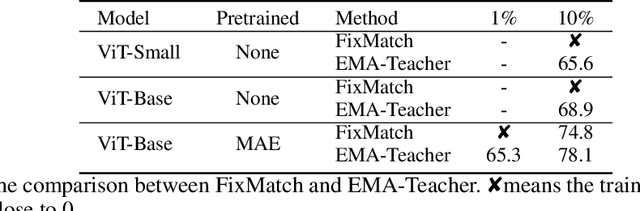
We study semi-supervised learning (SSL) for vision transformers (ViT), an under-explored topic despite the wide adoption of the ViT architectures to different tasks. To tackle this problem, we propose a new SSL pipeline, consisting of first un/self-supervised pre-training, followed by supervised fine-tuning, and finally semi-supervised fine-tuning. At the semi-supervised fine-tuning stage, we adopt an exponential moving average (EMA)-Teacher framework instead of the popular FixMatch, since the former is more stable and delivers higher accuracy for semi-supervised vision transformers. In addition, we propose a probabilistic pseudo mixup mechanism to interpolate unlabeled samples and their pseudo labels for improved regularization, which is important for training ViTs with weak inductive bias. Our proposed method, dubbed Semi-ViT, achieves comparable or better performance than the CNN counterparts in the semi-supervised classification setting. Semi-ViT also enjoys the scalability benefits of ViTs that can be readily scaled up to large-size models with increasing accuracies. For example, Semi-ViT-Huge achieves an impressive 80% top-1 accuracy on ImageNet using only 1% labels, which is comparable with Inception-v4 using 100% ImageNet labels.
Masked Vision and Language Modeling for Multi-modal Representation Learning
Aug 03, 2022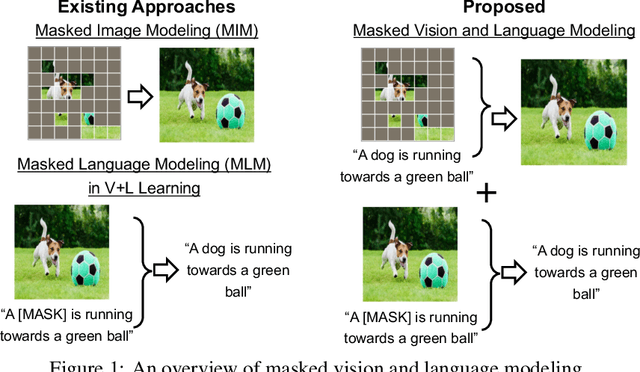
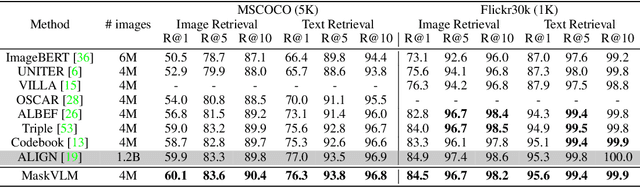
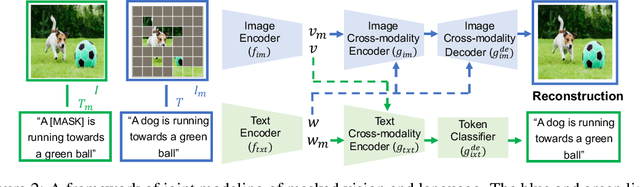
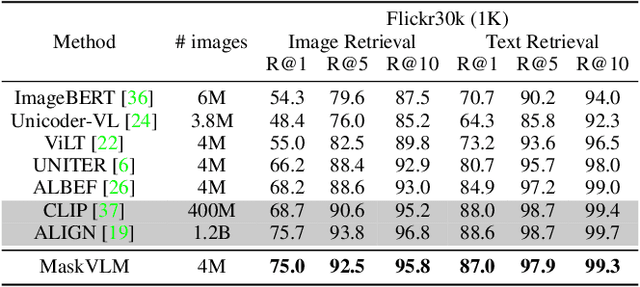
In this paper, we study how to use masked signal modeling in vision and language (V+L) representation learning. Instead of developing masked language modeling (MLM) and masked image modeling (MIM) independently, we propose to build joint masked vision and language modeling, where the masked signal of one modality is reconstructed with the help from another modality. This is motivated by the nature of image-text paired data that both of the image and the text convey almost the same information but in different formats. The masked signal reconstruction of one modality conditioned on another modality can also implicitly learn cross-modal alignment between language tokens and image patches. Our experiments on various V+L tasks show that the proposed method not only achieves state-of-the-art performances by using a large amount of data, but also outperforms the other competitors by a significant margin in the regimes of limited training data.
Rethinking Few-Shot Object Detection on a Multi-Domain Benchmark
Jul 22, 2022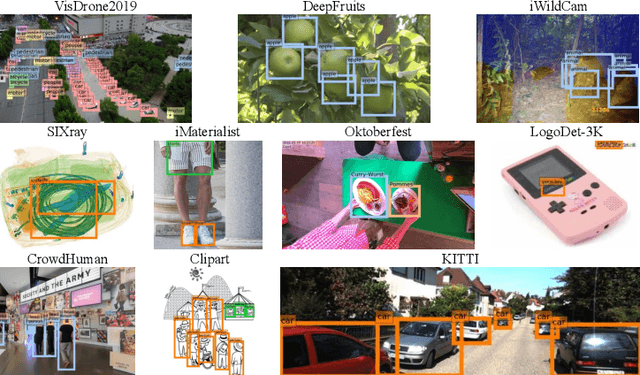
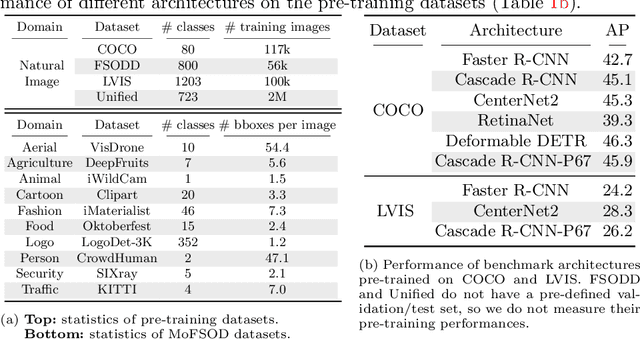
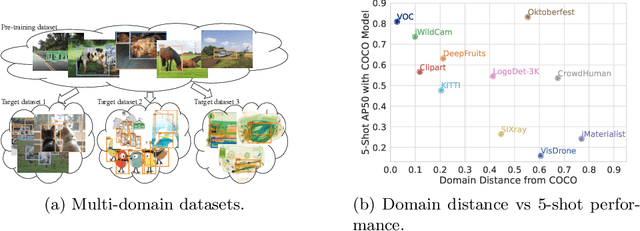
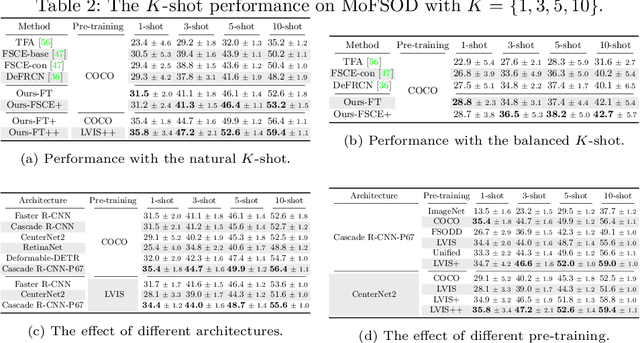
Most existing works on few-shot object detection (FSOD) focus on a setting where both pre-training and few-shot learning datasets are from a similar domain. However, few-shot algorithms are important in multiple domains; hence evaluation needs to reflect the broad applications. We propose a Multi-dOmain Few-Shot Object Detection (MoFSOD) benchmark consisting of 10 datasets from a wide range of domains to evaluate FSOD algorithms. We comprehensively analyze the impacts of freezing layers, different architectures, and different pre-training datasets on FSOD performance. Our empirical results show several key factors that have not been explored in previous works: 1) contrary to previous belief, on a multi-domain benchmark, fine-tuning (FT) is a strong baseline for FSOD, performing on par or better than the state-of-the-art (SOTA) algorithms; 2) utilizing FT as the baseline allows us to explore multiple architectures, and we found them to have a significant impact on down-stream few-shot tasks, even with similar pre-training performances; 3) by decoupling pre-training and few-shot learning, MoFSOD allows us to explore the impact of different pre-training datasets, and the right choice can boost the performance of the down-stream tasks significantly. Based on these findings, we list possible avenues of investigation for improving FSOD performance and propose two simple modifications to existing algorithms that lead to SOTA performance on the MoFSOD benchmark. The code is available at https://github.com/amazon-research/few-shot-object-detection-benchmark.
X-DETR: A Versatile Architecture for Instance-wise Vision-Language Tasks
Apr 12, 2022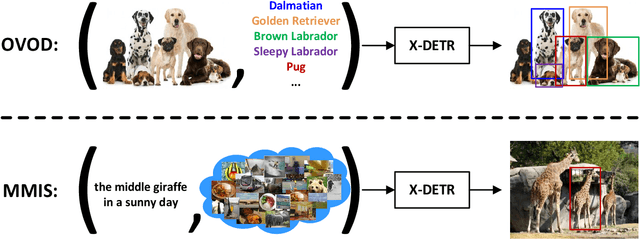
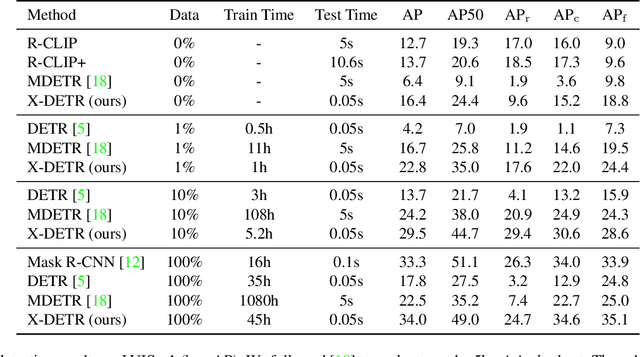
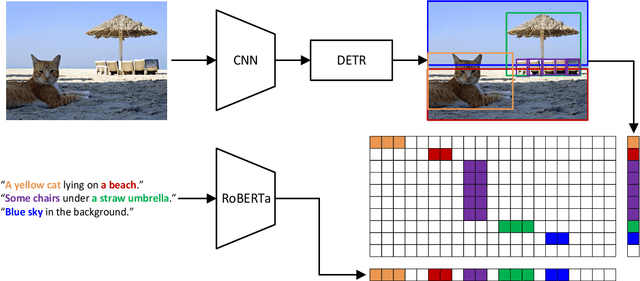
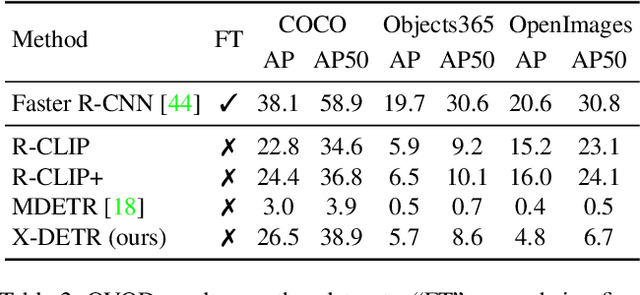
In this paper, we study the challenging instance-wise vision-language tasks, where the free-form language is required to align with the objects instead of the whole image. To address these tasks, we propose X-DETR, whose architecture has three major components: an object detector, a language encoder, and vision-language alignment. The vision and language streams are independent until the end and they are aligned using an efficient dot-product operation. The whole network is trained end-to-end, such that the detector is optimized for the vision-language tasks instead of an off-the-shelf component. To overcome the limited size of paired object-language annotations, we leverage other weak types of supervision to expand the knowledge coverage. This simple yet effective architecture of X-DETR shows good accuracy and fast speeds for multiple instance-wise vision-language tasks, e.g., 16.4 AP on LVIS detection of 1.2K categories at ~20 frames per second without using any LVIS annotation during training.