 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNew Intent Discovery with Attracting and Dispersing Prototype
Mar 25, 2024



New Intent Discovery (NID) aims to recognize known and infer new intent categories with the help of limited labeled and large-scale unlabeled data. The task is addressed as a feature-clustering problem and recent studies augment instance representation. However, existing methods fail to capture cluster-friendly representations, since they show less capability to effectively control and coordinate within-cluster and between-cluster distances. Tailored to the NID problem, we propose a Robust and Adaptive Prototypical learning (RAP) framework for globally distinct decision boundaries for both known and new intent categories. Specifically, a robust prototypical attracting learning (RPAL) method is designed to compel instances to gravitate toward their corresponding prototype, achieving greater within-cluster compactness. To attain larger between-cluster separation, another adaptive prototypical dispersing learning (APDL) method is devised to maximize the between-cluster distance from the prototype-to-prototype perspective. Experimental results evaluated on three challenging benchmarks (CLINC, BANKING, and StackOverflow) of our method with better cluster-friendly representation demonstrate that RAP brings in substantial improvements over the current state-of-the-art methods (even large language model) by a large margin (average +5.5% improvement).
MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL
Dec 26, 2023



Recent advancements in Text-to-SQL methods employing Large Language Models (LLMs) have demonstrated remarkable performance. Nonetheless, these approaches continue to encounter difficulties when handling extensive databases, intricate user queries, and erroneous SQL results. To tackle these challenges, we present \textsc{MAC-SQL}, a novel LLM-based multi-agent collaborative framework designed for the Text-to-SQL task. Our framework comprises three agents: the \textit{Selector}, accountable for condensing voluminous databases and preserving relevant table schemas for user questions; the \textit{Decomposer}, which disassembles complex user questions into more straightforward sub-problems and resolves them progressively; and the \textit{Refiner}, tasked with validating and refining defective SQL queries. We perform comprehensive experiments on two Text-to-SQL datasets, BIRD and Spider, achieving a state-of-the-art execution accuracy of 59.59\% on the BIRD test set. Moreover, we have open-sourced an instruction fine-tuning model, SQL-Llama, based on Code Llama 7B, in addition to an agent instruction dataset derived from training data based on BIRD and Spider. The SQL-Llama model has demonstrated encouraging results on the development sets of both BIRD and Spider. However, when compared to GPT-4, there remains a notable potential for enhancement. Our code and data are publicly available at https://github.com/wbbeyourself/MAC-SQL.
IEKM: A Model Incorporating External Keyword Matrices
Nov 21, 2023



A customer service platform system with a core text semantic similarity (STS) task faces two urgent challenges: Firstly, one platform system needs to adapt to different domains of customers, i.e., different domains adaptation (DDA). Secondly, it is difficult for the model of the platform system to distinguish sentence pairs that are literally close but semantically different, i.e., hard negative samples. In this paper, we propose an incorporation external keywords matrices model (IEKM) to address these challenges. The model uses external tools or dictionaries to construct external matrices and fuses them to the self-attention layers of the Transformer structure through gating units, thus enabling flexible corrections to the model results. We evaluate the method on multiple datasets and the results show that our method has improved performance on all datasets. To demonstrate that our method can effectively solve all the above challenges, we conduct a flexible correction experiment, which results in an increase in the F1 value from 56.61 to 73.53. Our code will be publicly available.
KnowPrefix-Tuning: A Two-Stage Prefix-Tuning Framework for Knowledge-Grounded Dialogue Generation
Jun 27, 2023



Existing knowledge-grounded conversation systems generate responses typically in a retrieve-then-generate manner. They require a large knowledge base and a strong knowledge retrieval component, which is time- and resource-consuming. In this paper, we address the challenge by leveraging the inherent knowledge encoded in the pre-trained language models (PLMs). We propose Knowledgeable Prefix Tuning (KnowPrefix-Tuning), a two-stage tuning framework, bypassing the retrieval process in a knowledge-grounded conversation system by injecting prior knowledge into the lightweight knowledge prefix. The knowledge prefix is a sequence of continuous knowledge-specific vectors that can be learned during training. In addition, we propose a novel interactive re-parameterization mechanism that allows the prefix to interact fully with the PLM during the optimization of response generation. Experimental results demonstrate that KnowPrefix-Tuning outperforms fine-tuning and other lightweight tuning approaches, and performs comparably with strong retrieval-based baselines while being $3\times$ faster during inference.
GripRank: Bridging the Gap between Retrieval and Generation via the Generative Knowledge Improved Passage Ranking
May 29, 2023



Retrieval-enhanced text generation, which aims to leverage passages retrieved from a large passage corpus for delivering a proper answer given the input query, has shown remarkable progress on knowledge-intensive language tasks such as open-domain question answering and knowledge-enhanced dialogue generation. However, the retrieved passages are not ideal for guiding answer generation because of the discrepancy between retrieval and generation, i.e., the candidate passages are all treated equally during the retrieval procedure without considering their potential to generate the proper answers. This discrepancy makes a passage retriever deliver a sub-optimal collection of candidate passages to generate answers. In this paper, we propose the GeneRative Knowledge Improved Passage Ranking (GripRank) approach, addressing the above challenge by distilling knowledge from a generative passage estimator (GPE) to a passage ranker, where the GPE is a generative language model used to measure how likely the candidate passages can generate the proper answer. We realize the distillation procedure by teaching the passage ranker learning to rank the passages ordered by the GPE. Furthermore, we improve the distillation quality by devising a curriculum knowledge distillation mechanism, which allows the knowledge provided by the GPE can be progressively distilled to the ranker through an easy-to-hard curriculum, enabling the passage ranker to correctly recognize the provenance of the answer from many plausible candidates. We conduct extensive experiments on four datasets across three knowledge-intensive language tasks. Experimental results show advantages over the state-of-the-art methods for both passage ranking and answer generation on the KILT benchmark.
QURG: Question Rewriting Guided Context-Dependent Text-to-SQL Semantic Parsing
May 16, 2023Context-dependent Text-to-SQL aims to translate multi-turn natural language questions into SQL queries. Despite various methods have exploited context-dependence information implicitly for contextual SQL parsing, there are few attempts to explicitly address the dependencies between current question and question context. This paper presents QURG, a novel Question Rewriting Guided approach to help the models achieve adequate contextual understanding. Specifically, we first train a question rewriting model to complete the current question based on question context, and convert them into a rewriting edit matrix. We further design a two-stream matrix encoder to jointly model the rewriting relations between question and context, and the schema linking relations between natural language and structured schema. Experimental results show that QURG significantly improves the performances on two large-scale context-dependent datasets SParC and CoSQL, especially for hard and long-turn questions.
CQR-SQL: Conversational Question Reformulation Enhanced Context-Dependent Text-to-SQL Parsers
May 17, 2022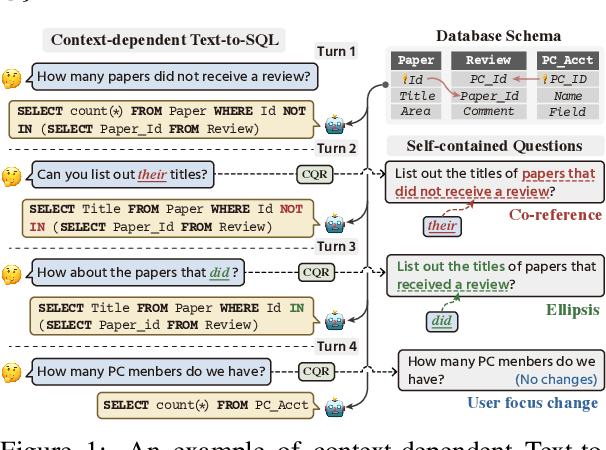

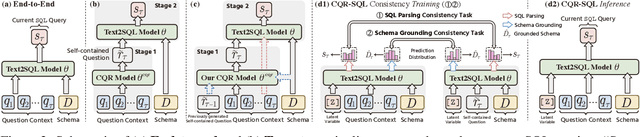
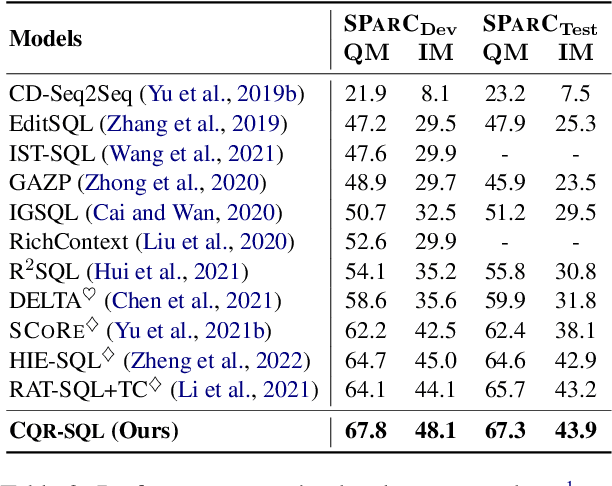
Context-dependent text-to-SQL is the task of translating multi-turn questions into database-related SQL queries. Existing methods typically focus on making full use of history context or previously predicted SQL for currently SQL parsing, while neglecting to explicitly comprehend the schema and conversational dependency, such as co-reference, ellipsis and user focus change. In this paper, we propose CQR-SQL, which uses auxiliary Conversational Question Reformulation (CQR) learning to explicitly exploit schema and decouple contextual dependency for SQL parsing. Specifically, we first present a schema enhanced recursive CQR method to produce domain-relevant self-contained questions. Secondly, we train CQR-SQL models to map the semantics of multi-turn questions and auxiliary self-contained questions into the same latent space through schema grounding consistency task and tree-structured SQL parsing consistency task, which enhances the abilities of SQL parsing by adequately contextual understanding. At the time of writing, our CQR-SQL achieves new state-of-the-art results on two context-dependent text-to-SQL benchmarks SParC and CoSQL.
Multi-channel Speech Enhancement with 2-D Convolutional Time-frequency Domain Features and a Pre-trained Acoustic Model
Jul 26, 2021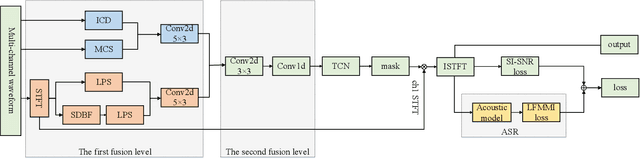
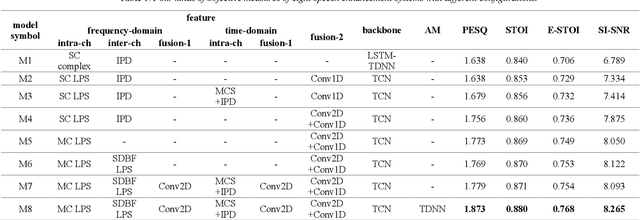
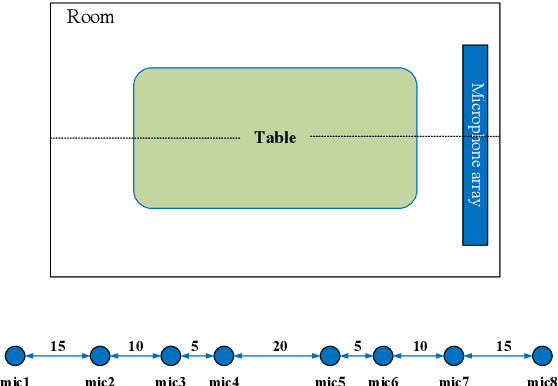

We propose a multi-channel speech enhancement approach with a novel two-stage feature fusion method and a pre-trained acoustic model in a multi-task learning paradigm. In the first fusion stage, the time-domain and frequency-domain features are extracted separately. In the time domain, the multi-channel convolution sum (MCS) and the inter-channel convolution differences (ICDs) features are computed and then integrated with a 2-D convolutional layer, while in the frequency domain, the log-power spectra (LPS) features from both original channels and super-directive beamforming outputs are combined with another 2-D convolutional layer. To fully integrate the rich information of multi-channel speech, i.e. time-frequency domain features and the array geometry, we apply a third 2-D convolutional layer in the second stage of fusion to obtain the final convolutional features. Furthermore, we propose to use a fixed clean acoustic model trained with the end-to-end lattice-free maximum mutual information criterion to enforce the enhanced output to have the same distribution as the clean waveform to alleviate the over-estimation problem of the enhancement task and constrain distortion. On the Task1 development dataset of the ConferencingSpeech 2021 challenge, a PESQ improvement of 0.24 and 0.19 is attained compared to the official baseline and a recently proposed multi-channel separation method.
Enhancing Label Correlation Feedback in Multi-Label Text Classification via Multi-Task Learning
Jun 06, 2021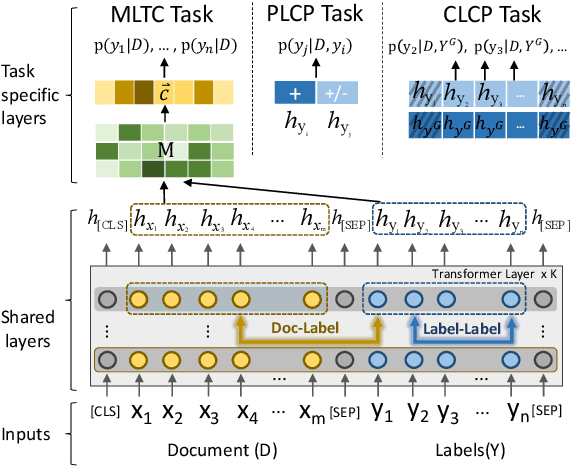
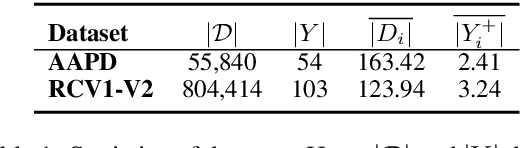
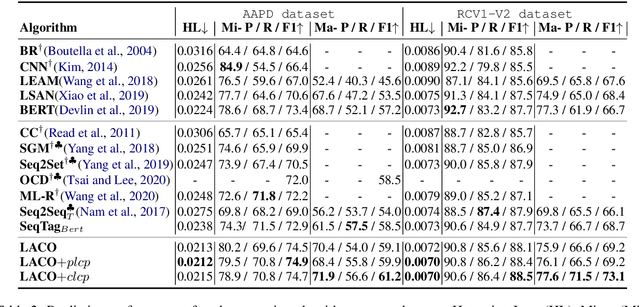
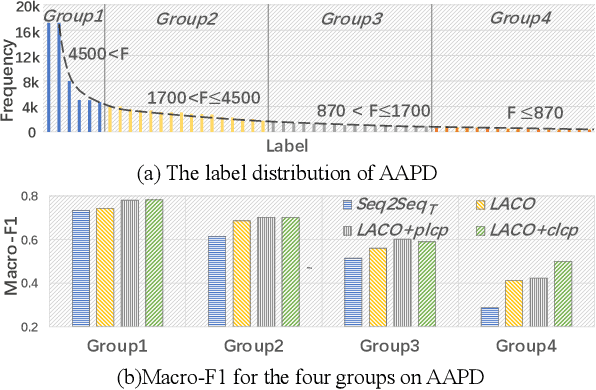
In multi-label text classification (MLTC), each given document is associated with a set of correlated labels. To capture label correlations, previous classifier-chain and sequence-to-sequence models transform MLTC to a sequence prediction task. However, they tend to suffer from label order dependency, label combination over-fitting and error propagation problems. To address these problems, we introduce a novel approach with multi-task learning to enhance label correlation feedback. We first utilize a joint embedding (JE) mechanism to obtain the text and label representation simultaneously. In MLTC task, a document-label cross attention (CA) mechanism is adopted to generate a more discriminative document representation. Furthermore, we propose two auxiliary label co-occurrence prediction tasks to enhance label correlation learning: 1) Pairwise Label Co-occurrence Prediction (PLCP), and 2) Conditional Label Co-occurrence Prediction (CLCP). Experimental results on AAPD and RCV1-V2 datasets show that our method outperforms competitive baselines by a large margin. We analyze low-frequency label performance, label dependency, label combination diversity and coverage speed to show the effectiveness of our proposed method on label correlation learning.
Knowledge Based Machine Reading Comprehension
Sep 12, 2018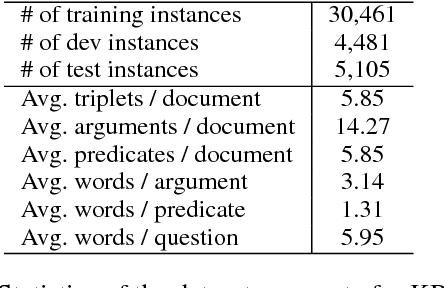
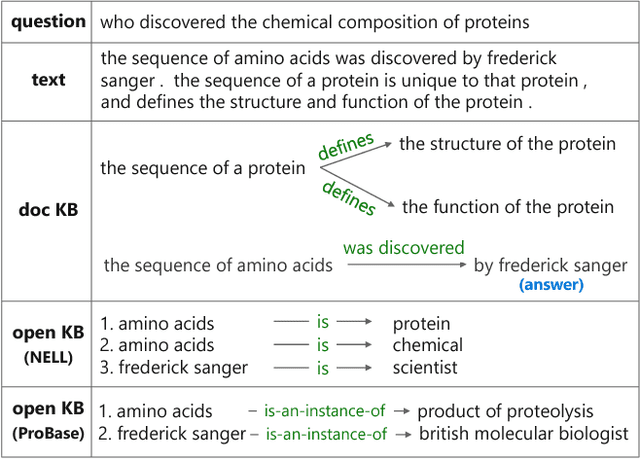
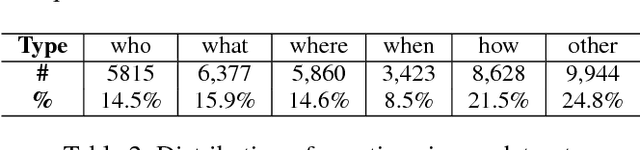
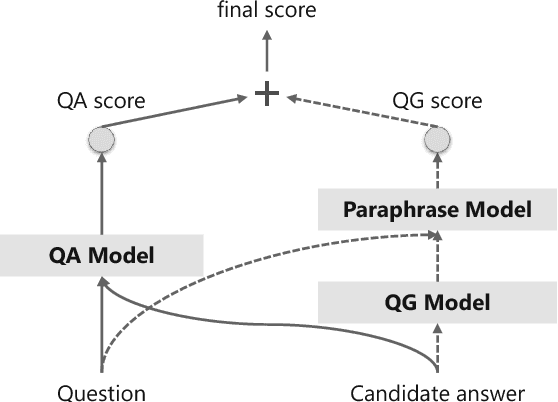
Machine reading comprehension (MRC) requires reasoning about both the knowledge involved in a document and knowledge about the world. However, existing datasets are typically dominated by questions that can be well solved by context matching, which fail to test this capability. To encourage the progress on knowledge-based reasoning in MRC, we present knowledge-based MRC in this paper, and build a new dataset consisting of 40,047 question-answer pairs. The annotation of this dataset is designed so that successfully answering the questions requires understanding and the knowledge involved in a document. We implement a framework consisting of both a question answering model and a question generation model, both of which take the knowledge extracted from the document as well as relevant facts from an external knowledge base such as Freebase/ProBase/Reverb/NELL. Results show that incorporating side information from external KB improves the accuracy of the baseline question answer system. We compare it with a standard MRC model BiDAF, and also provide the difficulty of the dataset and lay out remaining challenges.