 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariability-Driven User-Story Generation using LLM and Triadic Concept Analysis
Apr 11, 2025
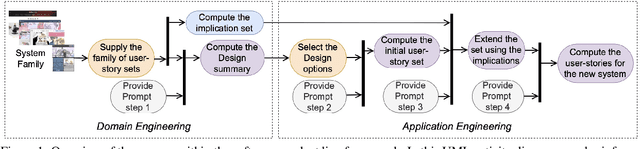


A widely used Agile practice for requirements is to produce a set of user stories (also called ``agile product backlog''), which roughly includes a list of pairs (role, feature), where the role handles the feature for a certain purpose. In the context of Software Product Lines, the requirements for a family of similar systems is thus a family of user-story sets, one per system, leading to a 3-dimensional dataset composed of sets of triples (system, role, feature). In this paper, we combine Triadic Concept Analysis (TCA) and Large Language Model (LLM) prompting to suggest the user-story set required to develop a new system relying on the variability logic of an existing system family. This process consists in 1) computing 3-dimensional variability expressed as a set of TCA implications, 2) providing the designer with intelligible design options, 3) capturing the designer's selection of options, 4) proposing a first user-story set corresponding to this selection, 5) consolidating its validity according to the implications identified in step 1, while completing it if necessary, and 6) leveraging LLM to have a more comprehensive website. This process is evaluated with a dataset comprising the user-story sets of 67 similar-purpose websites.
* 20th International Conference on Evaluation of Novel Approaches to Software Engineering April 4-6, 2025, in Porto, Portugal
Enhancing Large Language Models (LLMs) for Telecommunications using Knowledge Graphs and Retrieval-Augmented Generation
Mar 31, 2025Large language models (LLMs) have made significant progress in general-purpose natural language processing tasks. However, LLMs are still facing challenges when applied to domain-specific areas like telecommunications, which demands specialized expertise and adaptability to evolving standards. This paper presents a novel framework that combines knowledge graph (KG) and retrieval-augmented generation (RAG) techniques to enhance LLM performance in the telecom domain. The framework leverages a KG to capture structured, domain-specific information about network protocols, standards, and other telecom-related entities, comprehensively representing their relationships. By integrating KG with RAG, LLMs can dynamically access and utilize the most relevant and up-to-date knowledge during response generation. This hybrid approach bridges the gap between structured knowledge representation and the generative capabilities of LLMs, significantly enhancing accuracy, adaptability, and domain-specific comprehension. Our results demonstrate the effectiveness of the KG-RAG framework in addressing complex technical queries with precision. The proposed KG-RAG model attained an accuracy of 88% for question answering tasks on a frequently used telecom-specific dataset, compared to 82% for the RAG-only and 48% for the LLM-only approaches.
Approximate Size Targets Are Sufficient for Accurate Semantic Segmentation
Mar 10, 2025This paper demonstrates a surprising result for segmentation with image-level targets: extending binary class tags to approximate relative object-size distributions allows off-the-shelf architectures to solve the segmentation problem. A straightforward zero-avoiding KL-divergence loss for average predictions produces segmentation accuracy comparable to the standard pixel-precise supervision with full ground truth masks. In contrast, current results based on class tags typically require complex non-reproducible architectural modifications and specialized multi-stage training procedures. Our ideas are validated on PASCAL VOC using our new human annotations of approximate object sizes. We also show the results on COCO and medical data using synthetically corrupted size targets. All standard networks demonstrate robustness to the size targets' errors. For some classes, the validation accuracy is significantly better than the pixel-level supervision; the latter is not robust to errors in the masks. Our work provides new ideas and insights on image-level supervision in segmentation and may encourage other simple general solutions to the problem.
Low Complexity Frequency Domain Nonlinear Self-Interference Cancellation for Flexible Duplex
Mar 04, 2025Nonlinear self-interference (SI) cancellation is essential for mitigating the impact of transmitter-side nonlinearity on overall SI cancellation performance in flexible duplex systems, including in-band full-duplex (IBFD) and sub-band full-duplex (SBFD). Digital SI cancellation (SIC) must address the nonlinearity in the power amplifier (PA) and the in-phase/quadrature-phase (IQ) imbalance from up/down converters at the base station (BS), in addition to analog SIC. In environments with rich signal reflection paths, however, the required number of delayed taps for time-domain nonlinear SI cancellation increases exponentially with the number of multipaths, leading to excessive complexity. This paper introduces a novel, low-complexity, frequency domain nonlinear SIC, suitable for flexible duplex systems with multiple-input and multiple-output (MIMO) configurations. The key approach involves decomposing nonlinear SI into a nonlinear basis and categorizing them based on their effectiveness across any flexible duplex setting. The proposed algorithm is founded on our analytical results of intermodulation distortion (IMD) in the frequency domain and utilizes a specialized pilot sequence. This algorithm is directly applicable to orthogonal frequency division multiplexing (OFDM) multi-carrier systems and offers lower complexity than conventional digital SIC methods. Additionally, we assess the impact of the proposed SIC on flexible duplex systems through system-level simulation (SLS) using 3D ray-tracing and proof-of-concept (PoC) measurement.
HLV-1K: A Large-scale Hour-Long Video Benchmark for Time-Specific Long Video Understanding
Jan 03, 2025



Multimodal large language models have become a popular topic in deep visual understanding due to many promising real-world applications. However, hour-long video understanding, spanning over one hour and containing tens of thousands of visual frames, remains under-explored because of 1) challenging long-term video analyses, 2) inefficient large-model approaches, and 3) lack of large-scale benchmark datasets. Among them, in this paper, we focus on building a large-scale hour-long long video benchmark, HLV-1K, designed to evaluate long video understanding models. HLV-1K comprises 1009 hour-long videos with 14,847 high-quality question answering (QA) and multi-choice question asnwering (MCQA) pairs with time-aware query and diverse annotations, covering frame-level, within-event-level, cross-event-level, and long-term reasoning tasks. We evaluate our benchmark using existing state-of-the-art methods and demonstrate its value for testing deep long video understanding capabilities at different levels and for various tasks. This includes promoting future long video understanding tasks at a granular level, such as deep understanding of long live videos, meeting recordings, and movies.
Optimized Tradeoffs for Private Prediction with Majority Ensembling
Nov 27, 2024



We study a classical problem in private prediction, the problem of computing an $(m\epsilon, \delta)$-differentially private majority of $K$ $(\epsilon, \Delta)$-differentially private algorithms for $1 \leq m \leq K$ and $1 > \delta \geq \Delta \geq 0$. Standard methods such as subsampling or randomized response are widely used, but do they provide optimal privacy-utility tradeoffs? To answer this, we introduce the Data-dependent Randomized Response Majority (DaRRM) algorithm. It is parameterized by a data-dependent noise function $\gamma$, and enables efficient utility optimization over the class of all private algorithms, encompassing those standard methods. We show that maximizing the utility of an $(m\epsilon, \delta)$-private majority algorithm can be computed tractably through an optimization problem for any $m \leq K$ by a novel structural result that reduces the infinitely many privacy constraints into a polynomial set. In some settings, we show that DaRRM provably enjoys a privacy gain of a factor of 2 over common baselines, with fixed utility. Lastly, we demonstrate the strong empirical effectiveness of our first-of-its-kind privacy-constrained utility optimization for ensembling labels for private prediction from private teachers in image classification. Notably, our DaRRM framework with an optimized $\gamma$ exhibits substantial utility gains when compared against several baselines.
Distribution of Responsibility During the Usage of AI-Based Exoskeletons for Upper Limb Rehabilitation
Oct 22, 2024

The ethical issues concerning the AI-based exoskeletons used in healthcare have already been studied literally rather than technically. How the ethical guidelines can be integrated into the development process has not been widely studied. However, this is one of the most important topics which should be studied more in real-life applications. Therefore, in this paper we highlight one ethical concern in the context of an exoskeleton used to train a user to perform a gesture: during the interaction between the exoskeleton, patient and therapist, how is the responsibility for decision making distributed? Based on the outcome of this, we will discuss how to integrate ethical guidelines into the development process of an AI-based exoskeleton. The discussion is based on a case study: AiBle. The different technical factors affecting the rehabilitation results and the human-machine interaction for AI-based exoskeletons are identified and discussed in this paper in order to better apply the ethical guidelines during the development of AI-based exoskeletons.
Scalable spectral representations for network multiagent control
Oct 22, 2024



Network Markov Decision Processes (MDPs), a popular model for multi-agent control, pose a significant challenge to efficient learning due to the exponential growth of the global state-action space with the number of agents. In this work, utilizing the exponential decay property of network dynamics, we first derive scalable spectral local representations for network MDPs, which induces a network linear subspace for the local $Q$-function of each agent. Building on these local spectral representations, we design a scalable algorithmic framework for continuous state-action network MDPs, and provide end-to-end guarantees for the convergence of our algorithm. Empirically, we validate the effectiveness of our scalable representation-based approach on two benchmark problems, and demonstrate the advantages of our approach over generic function approximation approaches to representing the local $Q$-functions.
From Seconds to Hours: Reviewing MultiModal Large Language Models on Comprehensive Long Video Understanding
Sep 27, 2024



The integration of Large Language Models (LLMs) with visual encoders has recently shown promising performance in visual understanding tasks, leveraging their inherent capability to comprehend and generate human-like text for visual reasoning. Given the diverse nature of visual data, MultiModal Large Language Models (MM-LLMs) exhibit variations in model designing and training for understanding images, short videos, and long videos. Our paper focuses on the substantial differences and unique challenges posed by long video understanding compared to static image and short video understanding. Unlike static images, short videos encompass sequential frames with both spatial and within-event temporal information, while long videos consist of multiple events with between-event and long-term temporal information. In this survey, we aim to trace and summarize the advancements of MM-LLMs from image understanding to long video understanding. We review the differences among various visual understanding tasks and highlight the challenges in long video understanding, including more fine-grained spatiotemporal details, dynamic events, and long-term dependencies. We then provide a detailed summary of the advancements in MM-LLMs in terms of model design and training methodologies for understanding long videos. Finally, we compare the performance of existing MM-LLMs on video understanding benchmarks of various lengths and discuss potential future directions for MM-LLMs in long video understanding.
A spherical harmonic-domain spatial audio signal enhancement method based on minimum variance distortionless response
Sep 05, 2024Spatial audio signal enhancement aims to reduce interfering source contributions while preserving the desired sound field with its spatial cues intact. Existing methods generally rely on impractical assumptions (e.g. no reverberation or accurate estimations of impractical information) or have limited applicability. This paper presents a spherical harmonic (SH)-domain minimum variance distortionless response (MVDR)-based spatial signal enhancer using Relative Harmonic Coefficients (ReHCs) to extract clean SH coefficients from noisy ones in reverberant environments. A simulation study shows the proposed method achieves lower estimation error, higher speech-distortion-ratio (SDR), and comparable noise reduction (NR) within the sweet area in a reverberant environment, compared to a beamforming-and-projection method as the baseline.