 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScout Before You Attend: Sketch-and-Walk Sparse Attention for Efficient LLM Inference
Feb 07, 2026Self-attention dominates the computational and memory cost of long-context LLM inference across both prefill and decode phases. To address this challenge, we introduce Sketch&Walk Attention, a training-free sparse attention method that determines sparsity with lightweight sketches and deterministic walk. Sketch&Walk applies Hadamard sketching to get inexpensive approximations of attention scores, then aggregates these estimates across layers via a walk mechanism that captures attention influence beyond direct interactions between tokens. The accumulated walk scores are used to select top-k attention blocks, enabling dynamic sparsity with a single training-free algorithm that applies uniformly to both the prefill and decode phases, together with custom sparse attention kernels. Across a wide range of models and tasks, Sketch&Walk maintains near-lossless accuracy at 20% attention density and can slightly outperform dense attention in some settings, while achieving up to 6x inference speedup.
Redefining Machine Simultaneous Interpretation: From Incremental Translation to Human-Like Strategies
Jan 16, 2026Simultaneous Machine Translation (SiMT) requires high-quality translations under strict real-time constraints, which traditional policies with only READ/WRITE actions cannot fully address. We extend the action space of SiMT with four adaptive actions: Sentence_Cut, Drop, Partial_Summarization and Pronominalization, which enable real-time restructuring, omission, and simplification while preserving semantic fidelity. We adapt these actions in a large language model (LLM) framework and construct training references through action-aware prompting. To evaluate both quality and word-level monotonicity, we further develop a latency-aware TTS pipeline that maps textual outputs to speech with realistic timing. Experiments on the ACL60/60 English-Chinese, English-German and English-Japanese benchmarks show that our framework consistently improves semantic metrics and achieves lower delay compared to reference translations and salami-based baselines. Notably, combining Drop and Sentence_Cut leads to consistent improvements in the balance between fluency and latency. These results demonstrate that enriching the action space of LLM-based SiMT provides a promising direction for bridging the gap between human and machine interpretation.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
SASST: Leveraging Syntax-Aware Chunking and LLMs for Simultaneous Speech Translation
Aug 11, 2025This work proposes a grammar-based chunking strategy that segments input streams into semantically complete units by parsing dependency relations (e.g., noun phrase boundaries, verb-object structures) and punctuation features. The method ensures chunk coherence and minimizes semantic fragmentation. Building on this mechanism, we present SASST (Syntax-Aware Simultaneous Speech Translation), an end-to-end framework integrating frozen Whisper encoder and decoder-only LLM. The unified architecture dynamically outputs translation tokens or <WAIT> symbols to jointly optimize translation timing and content, with target-side reordering addressing word-order divergence. Experiments on CoVoST2 multilingual corpus En-{De, Zh, Ja} demonstrate significant translation quality improvements across languages and validate the effectiveness of syntactic structures in LLM-driven SimulST systems.
LiDARDustX: A LiDAR Dataset for Dusty Unstructured Road Environments
May 28, 2025



Autonomous driving datasets are essential for validating the progress of intelligent vehicle algorithms, which include localization, perception, and prediction. However, existing datasets are predominantly focused on structured urban environments, which limits the exploration of unstructured and specialized scenarios, particularly those characterized by significant dust levels. This paper introduces the LiDARDustX dataset, which is specifically designed for perception tasks under high-dust conditions, such as those encountered in mining areas. The LiDARDustX dataset consists of 30,000 LiDAR frames captured by six different LiDAR sensors, each accompanied by 3D bounding box annotations and point cloud semantic segmentation. Notably, over 80% of the dataset comprises dust-affected scenes. By utilizing this dataset, we have established a benchmark for evaluating the performance of state-of-the-art 3D detection and segmentation algorithms. Additionally, we have analyzed the impact of dust on perception accuracy and delved into the causes of these effects. The data and further information can be accessed at: https://github.com/vincentweikey/LiDARDustX.
seg2med: a segmentation-based medical image generation framework using denoising diffusion probabilistic models
Apr 12, 2025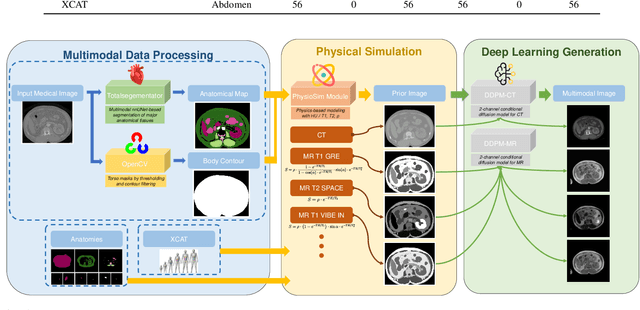
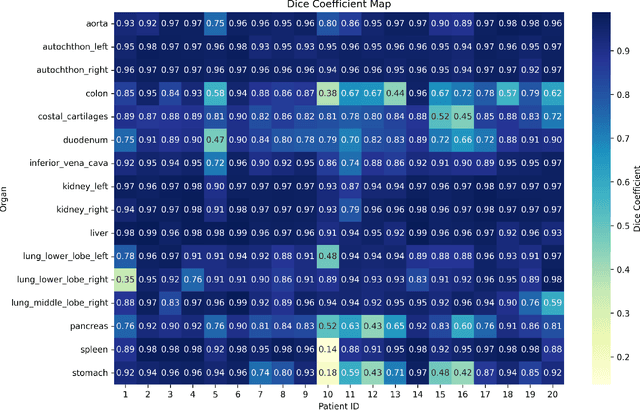
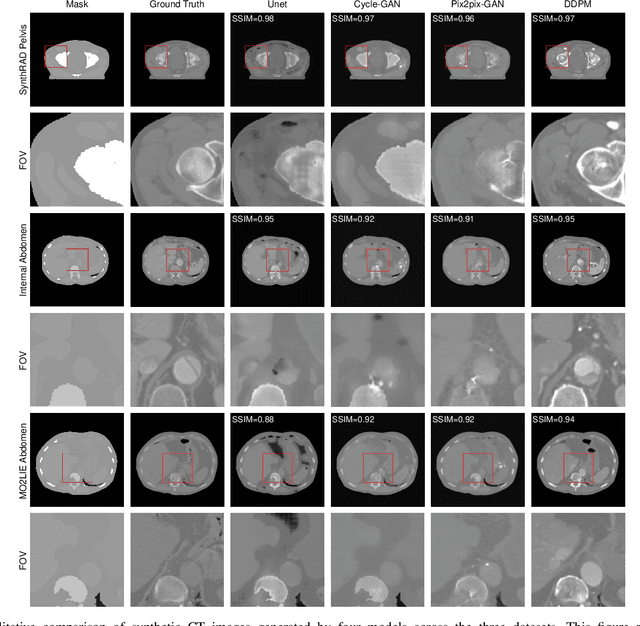
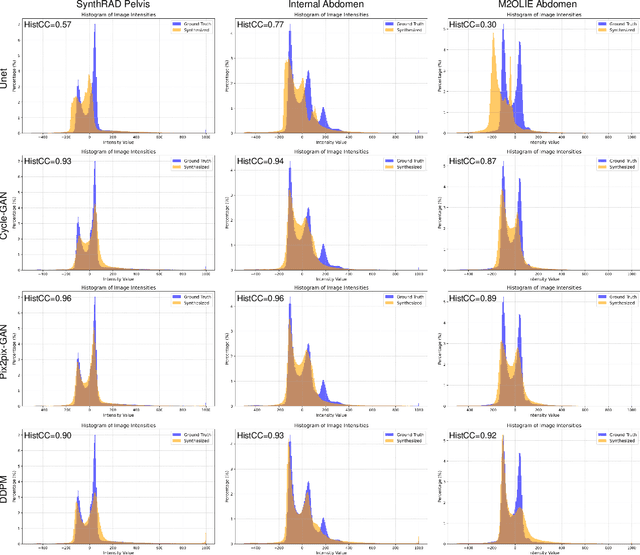
In this study, we present seg2med, an advanced medical image synthesis framework that uses Denoising Diffusion Probabilistic Models (DDPM) to generate high-quality synthetic medical images conditioned on anatomical masks from TotalSegmentator. The framework synthesizes CT and MR images from segmentation masks derived from real patient data and XCAT digital phantoms, achieving a Structural Similarity Index Measure (SSIM) of 0.94 +/- 0.02 for CT and 0.89 +/- 0.04 for MR images compared to ground-truth images of real patients. It also achieves a Feature Similarity Index Measure (FSIM) of 0.78 +/- 0.04 for CT images from XCAT. The generative quality is further supported by a Fr\'echet Inception Distance (FID) of 3.62 for CT image generation. Additionally, seg2med can generate paired CT and MR images with consistent anatomical structures and convert images between CT and MR modalities, achieving SSIM values of 0.91 +/- 0.03 for MR-to-CT and 0.77 +/- 0.04 for CT-to-MR conversion. Despite the limitations of incomplete anatomical details in segmentation masks, the framework shows strong performance in cross-modality synthesis and multimodal imaging. seg2med also demonstrates high anatomical fidelity in CT synthesis, achieving a mean Dice coefficient greater than 0.90 for 11 abdominal organs and greater than 0.80 for 34 organs out of 59 in 58 test cases. The highest Dice of 0.96 +/- 0.01 was recorded for the right scapula. Leveraging the TotalSegmentator toolkit, seg2med enables segmentation mask generation across diverse datasets, supporting applications in clinical imaging, data augmentation, multimodal synthesis, and diagnostic algorithm development.
4D Gaussian Splatting: Modeling Dynamic Scenes with Native 4D Primitives
Dec 30, 2024



Dynamic 3D scene representation and novel view synthesis from captured videos are crucial for enabling immersive experiences required by AR/VR and metaverse applications. However, this task is challenging due to the complexity of unconstrained real-world scenes and their temporal dynamics. In this paper, we frame dynamic scenes as a spatio-temporal 4D volume learning problem, offering a native explicit reformulation with minimal assumptions about motion, which serves as a versatile dynamic scene learning framework. Specifically, we represent a target dynamic scene using a collection of 4D Gaussian primitives with explicit geometry and appearance features, dubbed as 4D Gaussian splatting (4DGS). This approach can capture relevant information in space and time by fitting the underlying spatio-temporal volume. Modeling the spacetime as a whole with 4D Gaussians parameterized by anisotropic ellipses that can rotate arbitrarily in space and time, our model can naturally learn view-dependent and time-evolved appearance with 4D spherindrical harmonics. Notably, our 4DGS model is the first solution that supports real-time rendering of high-resolution, photorealistic novel views for complex dynamic scenes. To enhance efficiency, we derive several compact variants that effectively reduce memory footprint and mitigate the risk of overfitting. Extensive experiments validate the superiority of 4DGS in terms of visual quality and efficiency across a range of dynamic scene-related tasks (e.g., novel view synthesis, 4D generation, scene understanding) and scenarios (e.g., single object, indoor scenes, driving environments, synthetic and real data).
UAV-Enabled Secure ISAC Against Dual Eavesdropping Threats: Joint Beamforming and Trajectory Design
Dec 27, 2024



In this work, we study an unmanned aerial vehicle (UAV)-enabled secure integrated sensing and communication (ISAC) system, where a UAV serves as an aerial base station (BS) to simultaneously perform communication with a user and detect a target on the ground, while a dual-functional eavesdropper attempts to intercept the signals for both sensing and communication. Facing the dual eavesdropping threats, we aim to enhance the average achievable secrecy rate for the communication user by jointly designing the UAV trajectory together with the transmit information and sensing beamforming, while satisfying the requirements on sensing performance and sensing security, as well as the UAV power and flight constraints. To address the non-convex nature of the optimization problem, we employ the alternating optimization (AO) strategy, jointly with the successive convex approximation (SCA) and semidefinite relaxation (SDR) methods. Numerical results validate the proposed approach, demonstrating its ability to achieve a high secrecy rate while meeting the required sensing and security constraints.
Double-Exponential Increases in Inference Energy: The Cost of the Race for Accuracy
Dec 12, 2024



Deep learning models in computer vision have achieved significant success but pose increasing concerns about energy consumption and sustainability. Despite these concerns, there is a lack of comprehensive understanding of their energy efficiency during inference. In this study, we conduct a comprehensive analysis of the inference energy consumption of 1,200 ImageNet classification models - the largest evaluation of its kind to date. Our findings reveal a steep diminishing return in accuracy gains relative to the increase in energy usage, highlighting sustainability concerns in the pursuit of marginal improvements. We identify key factors contributing to energy consumption and demonstrate methods to improve energy efficiency. To promote more sustainable AI practices, we introduce an energy efficiency scoring system and develop an interactive web application that allows users to compare models based on accuracy and energy consumption. By providing extensive empirical data and practical tools, we aim to facilitate informed decision-making and encourage collaborative efforts in developing energy-efficient AI technologies.
Driving Scene Synthesis on Free-form Trajectories with Generative Prior
Dec 02, 2024



Driving scene synthesis along free-form trajectories is essential for driving simulations to enable closed-loop evaluation of end-to-end driving policies. While existing methods excel at novel view synthesis on recorded trajectories, they face challenges with novel trajectories due to limited views of driving videos and the vastness of driving environments. To tackle this challenge, we propose a novel free-form driving view synthesis approach, dubbed DriveX, by leveraging video generative prior to optimize a 3D model across a variety of trajectories. Concretely, we crafted an inverse problem that enables a video diffusion model to be utilized as a prior for many-trajectory optimization of a parametric 3D model (e.g., Gaussian splatting). To seamlessly use the generative prior, we iteratively conduct this process during optimization. Our resulting model can produce high-fidelity virtual driving environments outside the recorded trajectory, enabling free-form trajectory driving simulation. Beyond real driving scenes, DriveX can also be utilized to simulate virtual driving worlds from AI-generated videos.