 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeseg2med: a segmentation-based medical image generation framework using denoising diffusion probabilistic models
Apr 12, 2025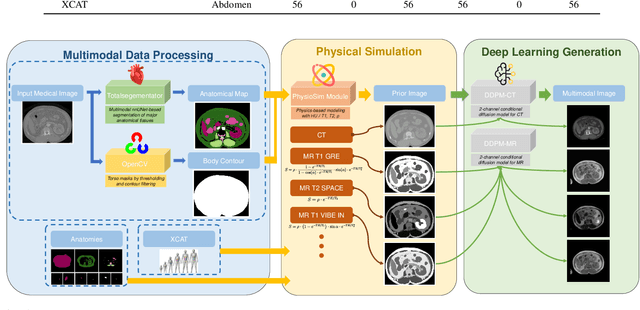
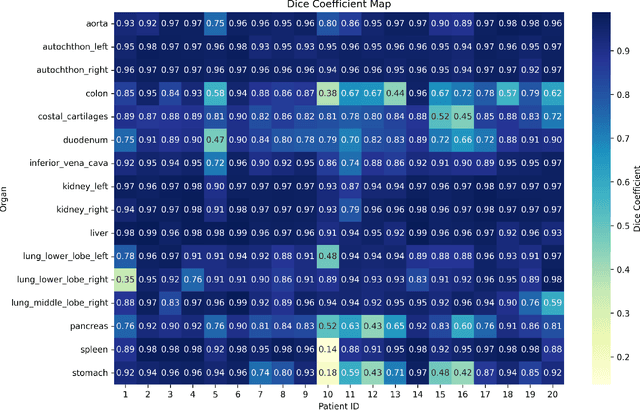
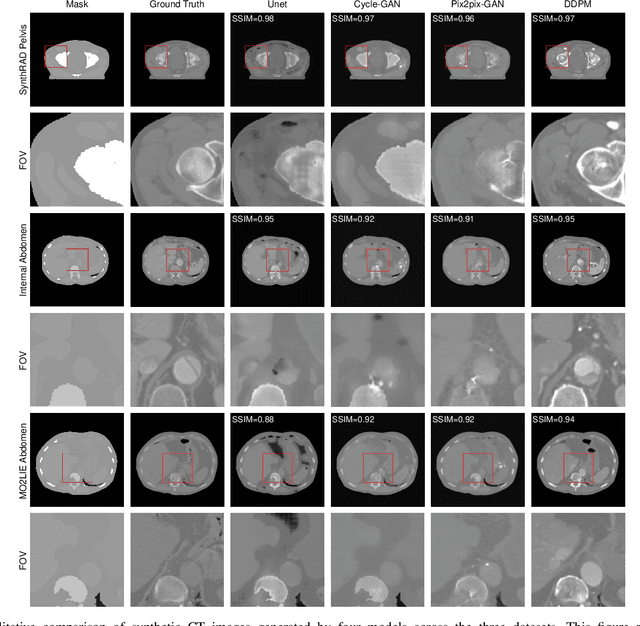
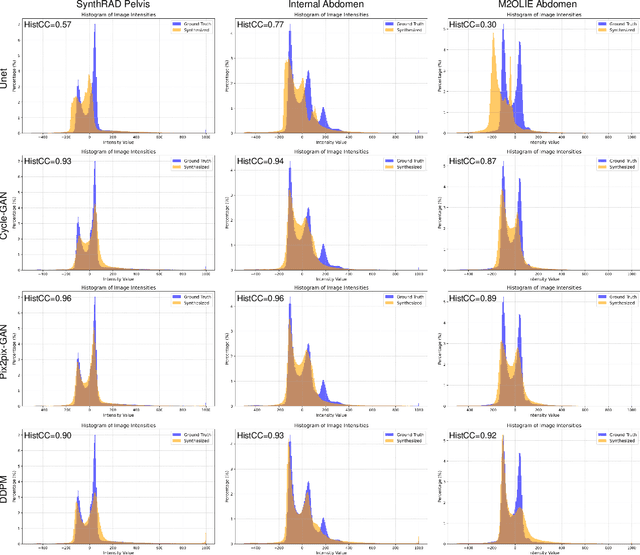
In this study, we present seg2med, an advanced medical image synthesis framework that uses Denoising Diffusion Probabilistic Models (DDPM) to generate high-quality synthetic medical images conditioned on anatomical masks from TotalSegmentator. The framework synthesizes CT and MR images from segmentation masks derived from real patient data and XCAT digital phantoms, achieving a Structural Similarity Index Measure (SSIM) of 0.94 +/- 0.02 for CT and 0.89 +/- 0.04 for MR images compared to ground-truth images of real patients. It also achieves a Feature Similarity Index Measure (FSIM) of 0.78 +/- 0.04 for CT images from XCAT. The generative quality is further supported by a Fr\'echet Inception Distance (FID) of 3.62 for CT image generation. Additionally, seg2med can generate paired CT and MR images with consistent anatomical structures and convert images between CT and MR modalities, achieving SSIM values of 0.91 +/- 0.03 for MR-to-CT and 0.77 +/- 0.04 for CT-to-MR conversion. Despite the limitations of incomplete anatomical details in segmentation masks, the framework shows strong performance in cross-modality synthesis and multimodal imaging. seg2med also demonstrates high anatomical fidelity in CT synthesis, achieving a mean Dice coefficient greater than 0.90 for 11 abdominal organs and greater than 0.80 for 34 organs out of 59 in 58 test cases. The highest Dice of 0.96 +/- 0.01 was recorded for the right scapula. Leveraging the TotalSegmentator toolkit, seg2med enables segmentation mask generation across diverse datasets, supporting applications in clinical imaging, data augmentation, multimodal synthesis, and diagnostic algorithm development.
Weighted Monte Carlo augmented spherical Fourier-Bessel convolutional layers for 3D abdominal organ segmentation
Mar 09, 2024



Filter-decomposition-based group equivariant convolutional neural networks show promising stability and data efficiency for 3D image feature extraction. However, the existing filter-decomposition-based 3D group equivariant neural networks rely on parameter-sharing designs and are mostly limited to rotation transformation groups, where the chosen spherical harmonic filter bases consider only angular orthogonality. These limitations hamper its application to deep neural network architectures for medical image segmentation. To address these issues, this paper describes a non-parameter-sharing affine group equivariant neural network for 3D medical image segmentation based on an adaptive aggregation of Monte Carlo augmented spherical Fourier Bessel filter bases. The efficiency and flexibility of the adopted non-parameter-sharing strategy enable for the first time an efficient implementation of 3D affine group equivariant convolutional neural networks for volumetric data. The introduced spherical Bessel Fourier filter basis combines both angular and radial orthogonality for better feature extraction. The 3D image segmentation experiments on two abdominal medical image sets, BTCV and the NIH Pancreas datasets, show that the proposed methods excel the state-of-the-art 3D neural networks with high training stability and data efficiency. The code will be available at https://github.com/ZhaoWenzhao/WMCSFB.
Adaptive aggregation of Monte Carlo augmented decomposed filters for efficient group-equivariant convolutional neural network
May 17, 2023



Filter-decomposition-based group-equivariant convolutional neural networks (G-CNN) have been demonstrated to increase CNN's data efficiency and contribute to better interpretability and controllability of CNN models. However, so far filter-decomposition-based affine G-CNN methods rely on parameter sharing for achieving high parameter efficiency and suffer from a heavy computational burden. They also use a limited number of transformations and in particular ignore the shear transform in the application. In this paper, we address these problems by emphasizing the importance of the diversity of transformations. We propose a flexible and efficient strategy based on weighted filter-wise Monte Carlo sampling. In addition, we introduce shear equivariant CNN to address the highly sparse representations of natural images. We demonstrate that the proposed methods are intrinsically an efficient generalization of traditional CNNs, and we explain the advantage of bottleneck architectures used in the existing state-of-the-art CNN models such as ResNet, ResNext, and ConvNeXt from the group-equivariant perspective. Experiments on image classification and image denoising tasks show that with a set of suitable filter basis, our methods achieve superior performance to standard CNN with high data efficiency. The code will be available at https://github.com/ZhaoWenzhao/MCG_CNN.