 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVDGD: Mitigating LVLM Hallucinations in Cognitive Prompts by Bridging the Visual Perception Gap
May 24, 2024Recent interest in Large Vision-Language Models (LVLMs) for practical applications is moderated by the significant challenge of hallucination or the inconsistency between the factual information and the generated text. In this paper, we first perform an in-depth analysis of hallucinations and discover several novel insights about how and when LVLMs hallucinate. From our analysis, we show that: (1) The community's efforts have been primarily targeted towards reducing hallucinations related to visual recognition (VR) prompts (e.g., prompts that only require describing the image), thereby ignoring hallucinations for cognitive prompts (e.g., prompts that require additional skills like reasoning on contents of the image). (2) LVLMs lack visual perception, i.e., they can see but not necessarily understand or perceive the input image. We analyze responses to cognitive prompts and show that LVLMs hallucinate due to a perception gap: although LVLMs accurately recognize visual elements in the input image and possess sufficient cognitive skills, they struggle to respond accurately and hallucinate. To overcome this shortcoming, we propose Visual Description Grounded Decoding (VDGD), a simple, robust, and training-free method for alleviating hallucinations. Specifically, we first describe the image and add it as a prefix to the instruction. Next, during auto-regressive decoding, we sample from the plausible candidates according to their KL-Divergence (KLD) to the description, where lower KLD is given higher preference. Experimental results on several benchmarks and LVLMs show that VDGD improves significantly over other baselines in reducing hallucinations. We also propose VaLLu, a benchmark for the comprehensive evaluation of the cognitive capabilities of LVLMs.
A Closer Look at the Limitations of Instruction Tuning
Feb 03, 2024Instruction Tuning (IT), the process of training large language models (LLMs) using instruction-response pairs, has emerged as the predominant method for transforming base pre-trained LLMs into open-domain conversational agents. While IT has achieved notable success and widespread adoption, its limitations and shortcomings remain underexplored. In this paper, through rigorous experiments and an in-depth analysis of the changes LLMs undergo through IT, we reveal various limitations of IT. In particular, we show that (1) IT fails to enhance knowledge or skills in LLMs. LoRA fine-tuning is limited to learning response initiation and style tokens, and full-parameter fine-tuning leads to knowledge degradation. (2) Copying response patterns from IT datasets derived from knowledgeable sources leads to a decline in response quality. (3) Full-parameter fine-tuning increases hallucination by inaccurately borrowing tokens from conceptually similar instances in the IT dataset for generating responses. (4) Popular methods to improve IT do not lead to performance improvements over a simple LoRA fine-tuned model. Our findings reveal that responses generated solely from pre-trained knowledge consistently outperform responses by models that learn any form of new knowledge from IT on open-source datasets. We hope the insights and challenges revealed inspire future work.
Efficient Spoken Language Recognition via Multilabel Classification
Jun 02, 2023



Spoken language recognition (SLR) is the task of automatically identifying the language present in a speech signal. Existing SLR models are either too computationally expensive or too large to run effectively on devices with limited resources. For real-world deployment, a model should also gracefully handle unseen languages outside of the target language set, yet prior work has focused on closed-set classification where all input languages are known a-priori. In this paper we address these two limitations: we explore efficient model architectures for SLR based on convolutional networks, and propose a multilabel training strategy to handle non-target languages at inference time. Using the VoxLingua107 dataset, we show that our models obtain competitive results while being orders of magnitude smaller and faster than current state-of-the-art methods, and that our multilabel strategy is more robust to unseen non-target languages compared to multiclass classification.
Audio Similarity is Unreliable as a Proxy for Audio Quality
Jun 27, 2022
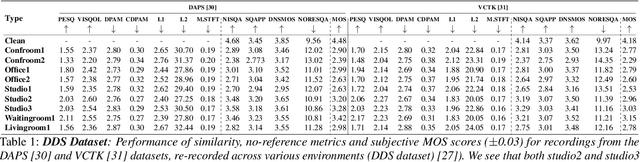

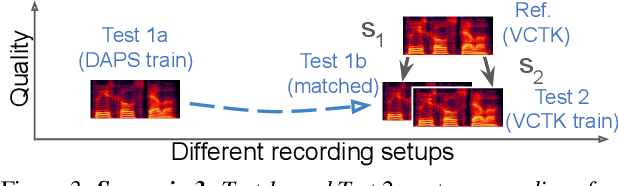
Many audio processing tasks require perceptual assessment. However, the time and expense of obtaining ``gold standard'' human judgments limit the availability of such data. Most applications incorporate full reference or other similarity-based metrics (e.g. PESQ) that depend on a clean reference. Researchers have relied on such metrics to evaluate and compare various proposed methods, often concluding that small, measured differences imply one is more effective than another. This paper demonstrates several practical scenarios where similarity metrics fail to agree with human perception, because they: (1) vary with clean references; (2) rely on attributes that humans factor out when considering quality, and (3) are sensitive to imperceptible signal level differences. In those scenarios, we show that no-reference metrics do not suffer from such shortcomings and correlate better with human perception. We conclude therefore that similarity serves as an unreliable proxy for audio quality.
Music Enhancement via Image Translation and Vocoding
Apr 28, 2022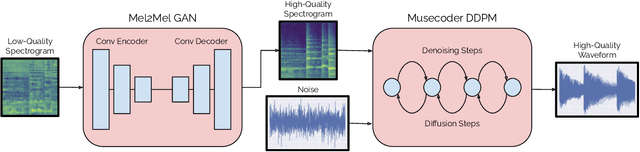
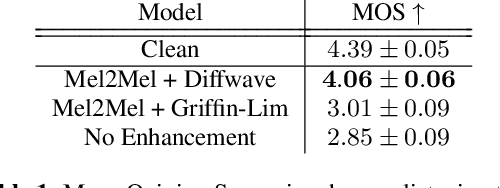


Consumer-grade music recordings such as those captured by mobile devices typically contain distortions in the form of background noise, reverb, and microphone-induced EQ. This paper presents a deep learning approach to enhance low-quality music recordings by combining (i) an image-to-image translation model for manipulating audio in its mel-spectrogram representation and (ii) a music vocoding model for mapping synthetically generated mel-spectrograms to perceptually realistic waveforms. We find that this approach to music enhancement outperforms baselines which use classical methods for mel-spectrogram inversion and an end-to-end approach directly mapping noisy waveforms to clean waveforms. Additionally, in evaluating the proposed method with a listening test, we analyze the reliability of common audio enhancement evaluation metrics when used in the music domain.
HEAR 2021: Holistic Evaluation of Audio Representations
Mar 26, 2022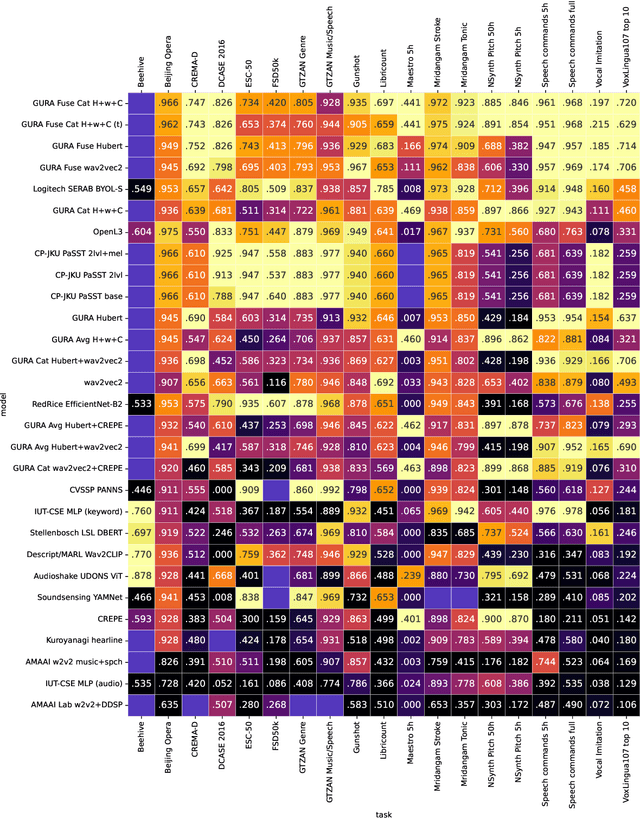
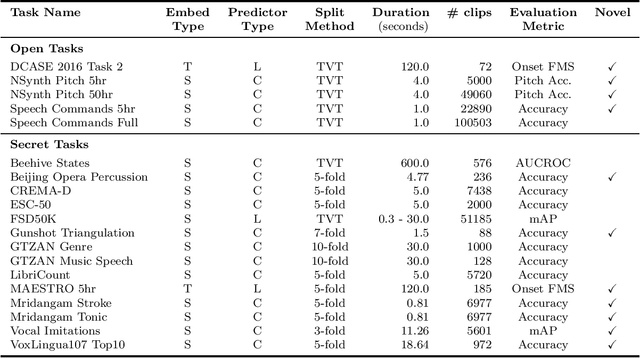

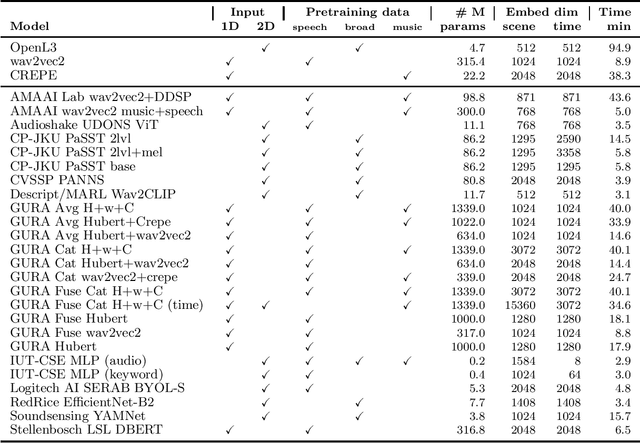
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
Neural Pitch-Shifting and Time-Stretching with Controllable LPCNet
Oct 05, 2021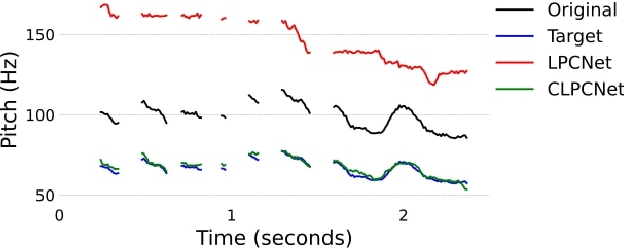
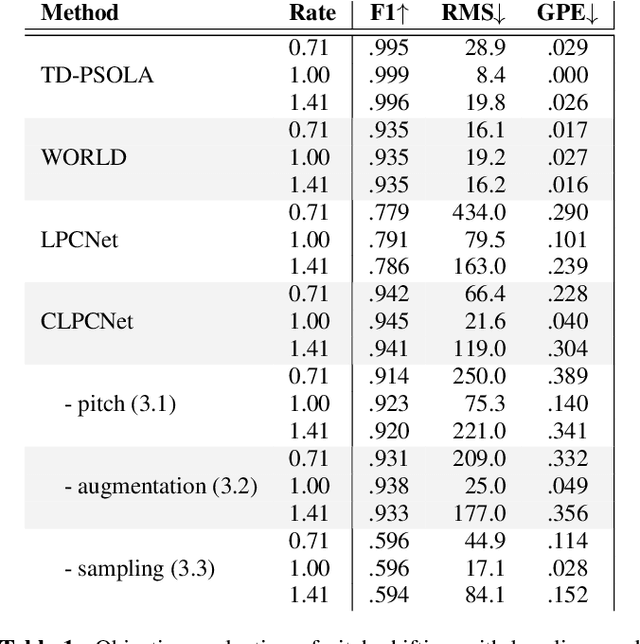
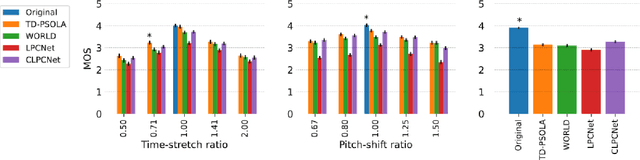
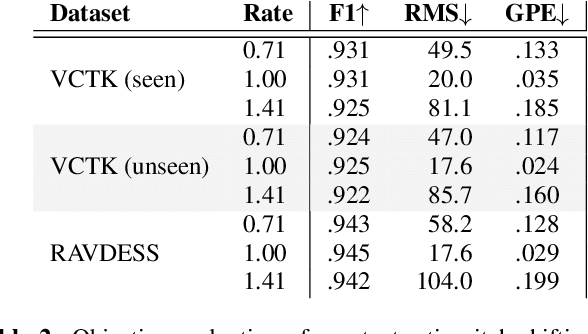
Modifying the pitch and timing of an audio signal are fundamental audio editing operations with applications in speech manipulation, audio-visual synchronization, and singing voice editing and synthesis. Thus far, methods for pitch-shifting and time-stretching that use digital signal processing (DSP) have been favored over deep learning approaches due to their speed and relatively higher quality. However, even existing DSP-based methods for pitch-shifting and time-stretching induce artifacts that degrade audio quality. In this paper, we propose Controllable LPCNet (CLPCNet), an improved LPCNet vocoder capable of pitch-shifting and time-stretching of speech. For objective evaluation, we show that CLPCNet performs pitch-shifting of speech on unseen datasets with high accuracy relative to prior neural methods. For subjective evaluation, we demonstrate that the quality and naturalness of pitch-shifting and time-stretching with CLPCNet on unseen datasets meets or exceeds competitive neural- or DSP-based approaches.
Controllable deep melody generation via hierarchical music structure representation
Sep 02, 2021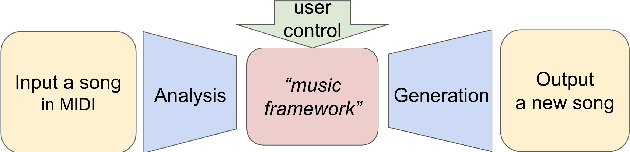
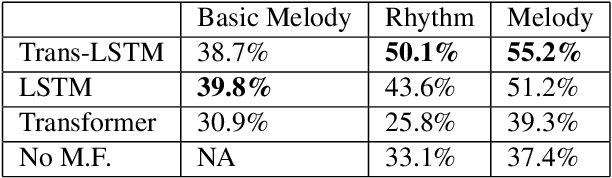
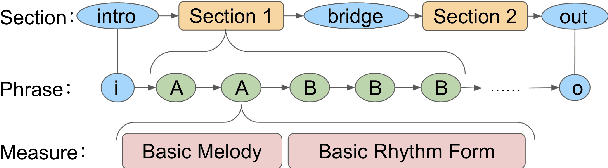
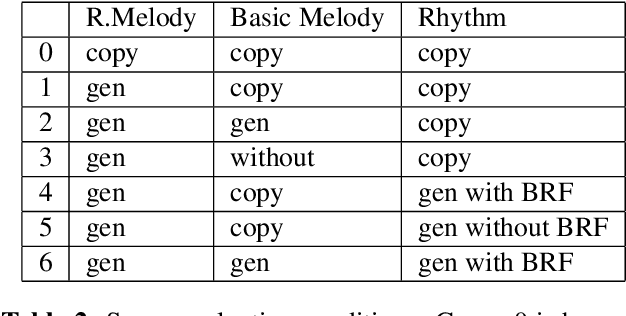
Recent advances in deep learning have expanded possibilities to generate music, but generating a customizable full piece of music with consistent long-term structure remains a challenge. This paper introduces MusicFrameworks, a hierarchical music structure representation and a multi-step generative process to create a full-length melody guided by long-term repetitive structure, chord, melodic contour, and rhythm constraints. We first organize the full melody with section and phrase-level structure. To generate melody in each phrase, we generate rhythm and basic melody using two separate transformer-based networks, and then generate the melody conditioned on the basic melody, rhythm and chords in an auto-regressive manner. By factoring music generation into sub-problems, our approach allows simpler models and requires less data. To customize or add variety, one can alter chords, basic melody, and rhythm structure in the music frameworks, letting our networks generate the melody accordingly. Additionally, we introduce new features to encode musical positional information, rhythm patterns, and melodic contours based on musical domain knowledge. A listening test reveals that melodies generated by our method are rated as good as or better than human-composed music in the POP909 dataset about half the time.
Context-Aware Prosody Correction for Text-Based Speech Editing
Feb 16, 2021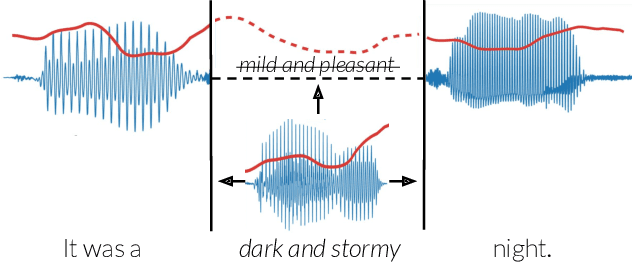

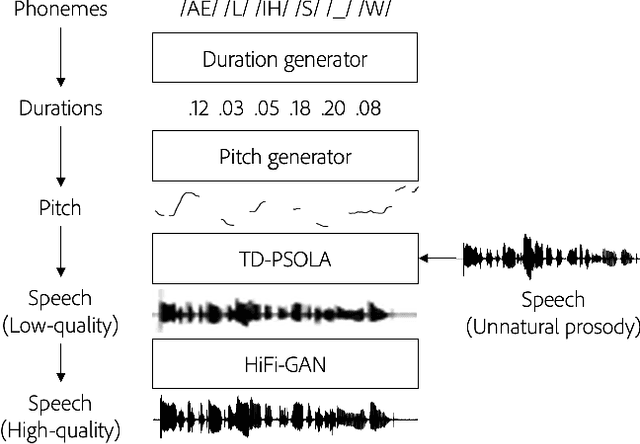
Text-based speech editors expedite the process of editing speech recordings by permitting editing via intuitive cut, copy, and paste operations on a speech transcript. A major drawback of current systems, however, is that edited recordings often sound unnatural because of prosody mismatches around edited regions. In our work, we propose a new context-aware method for more natural sounding text-based editing of speech. To do so, we 1) use a series of neural networks to generate salient prosody features that are dependent on the prosody of speech surrounding the edit and amenable to fine-grained user control 2) use the generated features to control a standard pitch-shift and time-stretch method and 3) apply a denoising neural network to remove artifacts induced by the signal manipulation to yield a high-fidelity result. We evaluate our approach using a subjective listening test, provide a detailed comparative analysis, and conclude several interesting insights.
CDPAM: Contrastive learning for perceptual audio similarity
Feb 09, 2021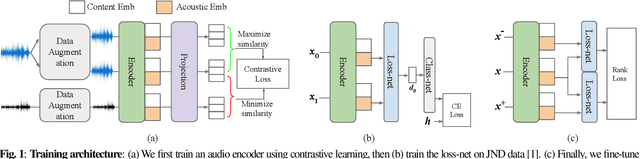

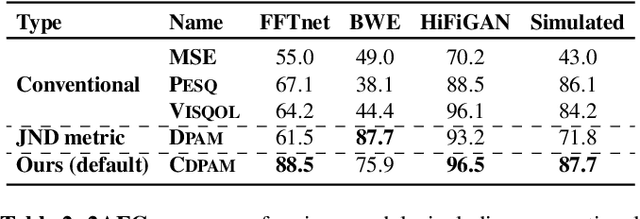
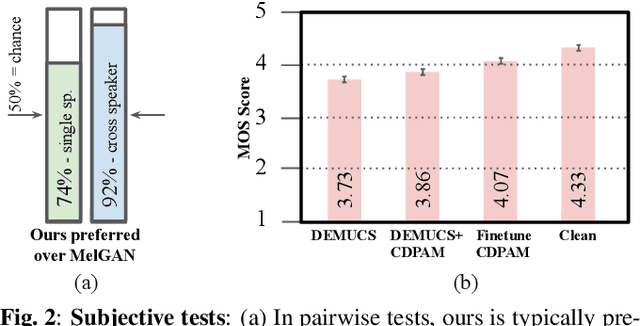
Many speech processing methods based on deep learning require an automatic and differentiable audio metric for the loss function. The DPAM approach of Manocha et al. learns a full-reference metric trained directly on human judgments, and thus correlates well with human perception. However, it requires a large number of human annotations and does not generalize well outside the range of perturbations on which it was trained. This paper introduces CDPAM, a metric that builds on and advances DPAM. The primary improvement is to combine contrastive learning and multi-dimensional representations to build robust models from limited data. In addition, we collect human judgments on triplet comparisons to improve generalization to a broader range of audio perturbations. CDPAM correlates well with human responses across nine varied datasets. We also show that adding this metric to existing speech synthesis and enhancement methods yields significant improvement, as measured by objective and subjective tests.