 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Real-Time Gesture-Based Control Framework
Apr 28, 2025



We introduce a real-time, human-in-the-loop gesture control framework that can dynamically adapt audio and music based on human movement by analyzing live video input. By creating a responsive connection between visual and auditory stimuli, this system enables dancers and performers to not only respond to music but also influence it through their movements. Designed for live performances, interactive installations, and personal use, it offers an immersive experience where users can shape the music in real time. The framework integrates computer vision and machine learning techniques to track and interpret motion, allowing users to manipulate audio elements such as tempo, pitch, effects, and playback sequence. With ongoing training, it achieves user-independent functionality, requiring as few as 50 to 80 samples to label simple gestures. This framework combines gesture training, cue mapping, and audio manipulation to create a dynamic, interactive experience. Gestures are interpreted as input signals, mapped to sound control commands, and used to naturally adjust music elements, showcasing the seamless interplay between human interaction and machine response.
Interactive Sonification for Health and Energy using ChucK and Unity
Apr 12, 2024



Sonification can provide valuable insights about data but most existing approaches are not designed to be controlled by the user in an interactive fashion. Interactions enable the designer of the sonification to more rapidly experiment with sound design and allow the sonification to be modified in real-time by interacting with various control parameters. In this paper, we describe two case studies of interactive sonification that utilize publicly available datasets that have been described recently in the International Conference on Auditory Display (ICAD). They are from the health and energy domains: electroencephalogram (EEG) alpha wave data and air pollutant data consisting of nitrogen dioxide, sulfur dioxide, carbon monoxide, and ozone. We show how these sonfications can be recreated to support interaction utilizing a general interactive sonification framework built using ChucK, Unity, and Chunity. In addition to supporting typical sonification methods that are common in existing sonification toolkits, our framework introduces novel methods such as supporting discrete events, interleaved playback of multiple data streams for comparison, and using frequency modulation (FM) synthesis in terms of one data attribute modulating another. We also describe how these new functionalities can be used to improve the sonification experience of the two datasets we have investigated.
* In the Proceedings of the Conference on Sonification of Health and Environmental Data (SoniHED 2022). http://dx.doi.org/10.5281/zenodo.7243950
HEAR 2021: Holistic Evaluation of Audio Representations
Mar 26, 2022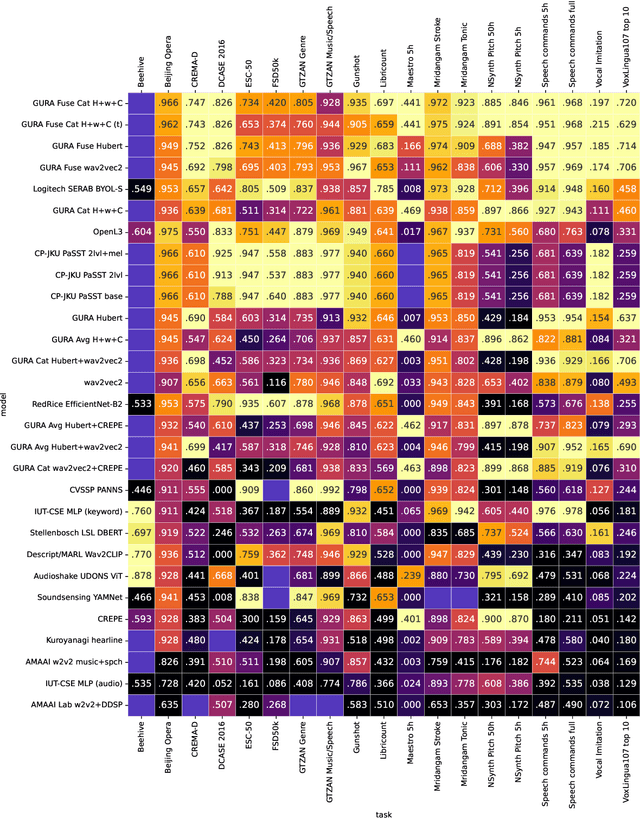
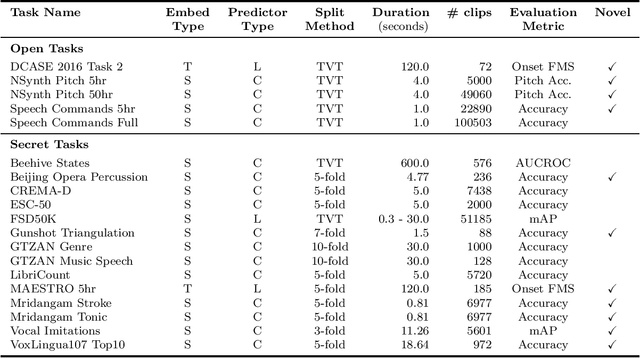

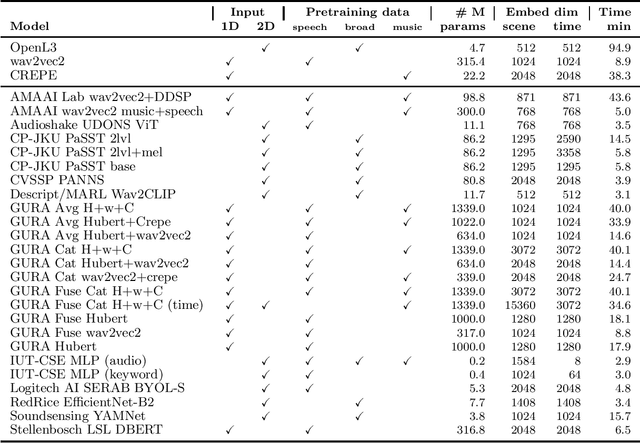
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
One Billion Audio Sounds from GPU-enabled Modular Synthesis
Apr 27, 2021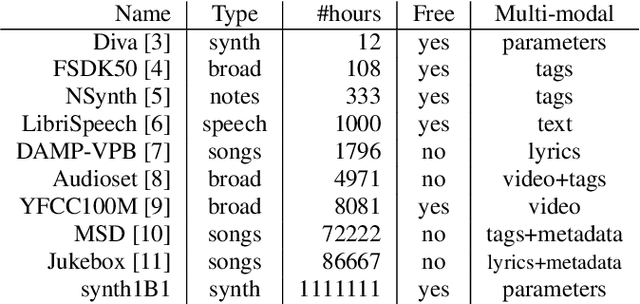
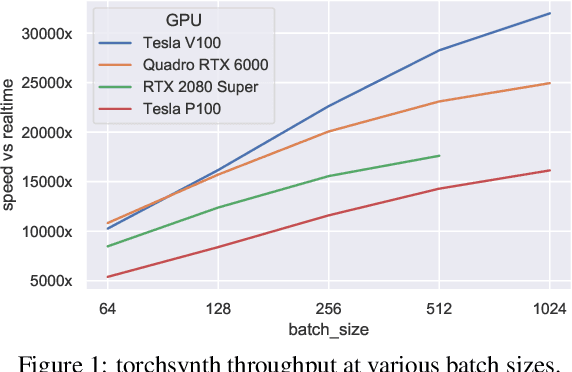
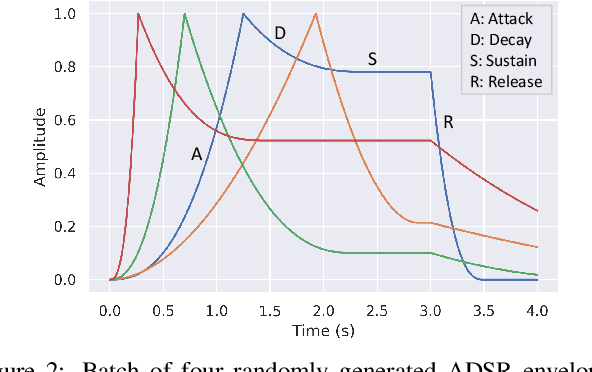
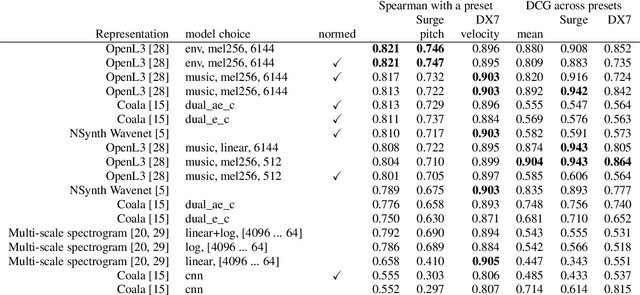
We release synth1B1, a multi-modal audio corpus consisting of 1 billion 4-second synthesized sounds, which is 100x larger than any audio dataset in the literature. Each sound is paired with the corresponding latent parameters used to generate it. synth1B1 samples are deterministically generated on-the-fly 16200x faster than real-time (714MHz) on a single GPU using torchsynth (https://github.com/torchsynth/torchsynth), an open-source modular synthesizer we release. Additionally, we release two new audio datasets: FM synth timbre (https://zenodo.org/record/4677102) and subtractive synth pitch (https://zenodo.org/record/4677097). Using these datasets, we demonstrate new rank-based synthesizer-motivated evaluation criteria for existing audio representations. Finally, we propose novel approaches to synthesizer hyperparameter optimization, and demonstrate how perceptually-correlated auditory distances could enable new applications in synthesizer design.
Deep Autotuner: a Pitch Correcting Network for Singing Performances
Feb 12, 2020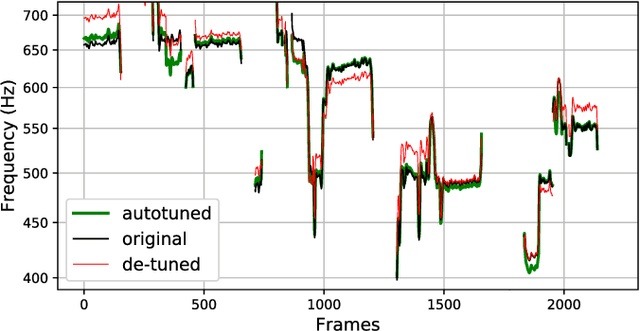
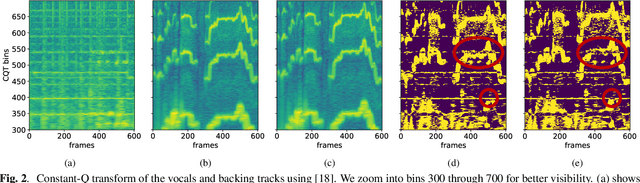
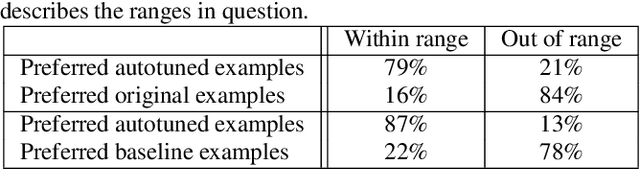
We introduce a data-driven approach to automatic pitch correction of solo singing performances. The proposed approach predicts note-wise pitch shifts from the relationship between the respective spectrograms of the singing and accompaniment. This approach differs from commercial systems, where vocal track notes are usually shifted to be centered around pitches in a user-defined score, or mapped to the closest pitch among the twelve equal-tempered scale degrees. The proposed system treats pitch as a continuous value rather than relying on a set of discretized notes found in musical scores, thus allowing for improvisation and harmonization in the singing performance. We train our neural network model using a dataset of 4,702 amateur karaoke performances selected for good intonation. Our model is trained on both incorrect intonation, for which it learns a correction, and intentional pitch variation, which it learns to preserve. The proposed deep neural network with gated recurrent units on top of convolutional layers shows promising performance on the real-world score-free singing pitch correction task of autotuning.
Deep Autotuner: A Data-Driven Approach to Natural-Sounding Pitch Correction for Singing Voice in Karaoke Performances
Feb 03, 2019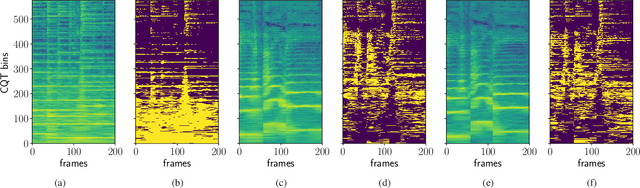
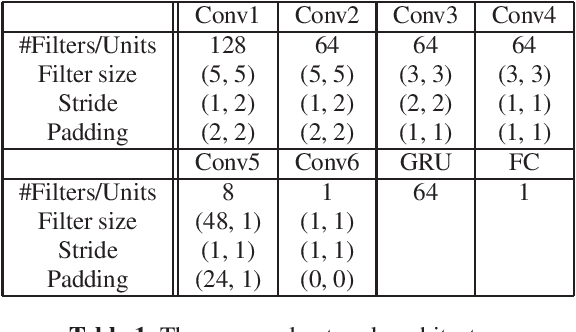
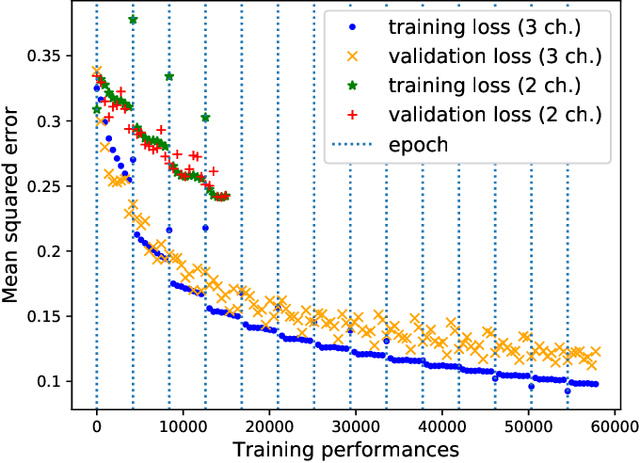
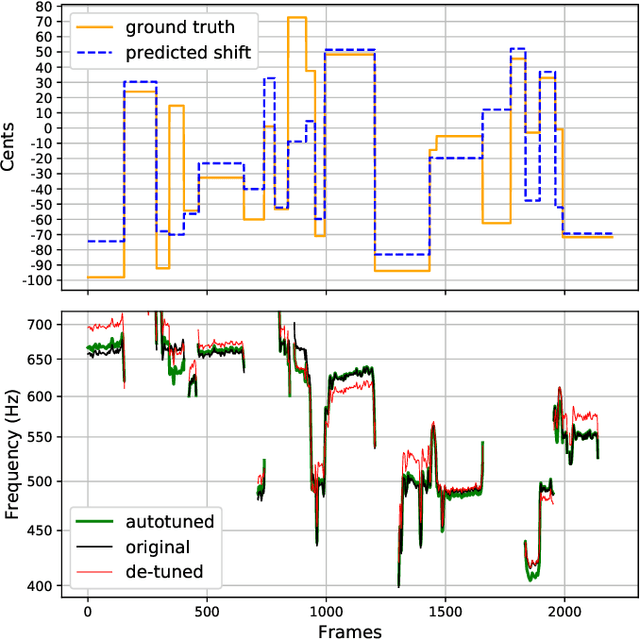
We describe a machine-learning approach to pitch correcting a solo singing performance in a karaoke setting, where the solo voice and accompaniment are on separate tracks. The proposed approach addresses the situation where no musical score of the vocals nor the accompaniment exists: It predicts the amount of correction from the relationship between the spectral contents of the vocal and accompaniment tracks. Hence, the pitch shift in cents suggested by the model can be used to make the voice sound in tune with the accompaniment. This approach differs from commercially used automatic pitch correction systems, where notes in the vocal tracks are shifted to be centered around notes in a user-defined score or mapped to the closest pitch among the twelve equal-tempered scale degrees. We train the model using a dataset of 4,702 amateur karaoke performances selected for good intonation. We present a Convolutional Gated Recurrent Unit (CGRU) model to accomplish this task. This method can be extended into unsupervised pitch correction of a vocal performance, popularly referred to as autotuning.
Espresso: Efficient Forward Propagation for BCNNs
Mar 07, 2018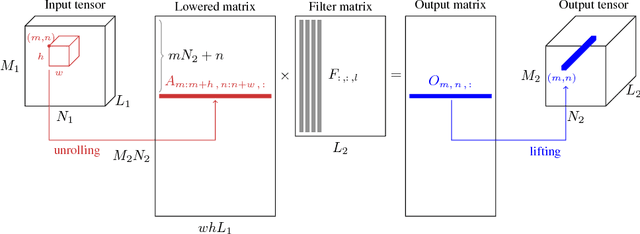



There are many applications scenarios for which the computational performance and memory footprint of the prediction phase of Deep Neural Networks (DNNs) needs to be optimized. Binary Neural Networks (BDNNs) have been shown to be an effective way of achieving this objective. In this paper, we show how Convolutional Neural Networks (CNNs) can be implemented using binary representations. Espresso is a compact, yet powerful library written in C/CUDA that features all the functionalities required for the forward propagation of CNNs, in a binary file less than 400KB, without any external dependencies. Although it is mainly designed to take advantage of massive GPU parallelism, Espresso also provides an equivalent CPU implementation for CNNs. Espresso provides special convolutional and dense layers for BCNNs, leveraging bit-packing and bit-wise computations for efficient execution. These techniques provide a speed-up of matrix-multiplication routines, and at the same time, reduce memory usage when storing parameters and activations. We experimentally show that Espresso is significantly faster than existing implementations of optimized binary neural networks ($\approx$ 2 orders of magnitude). Espresso is released under the Apache 2.0 license and is available at http://github.com/fpeder/espresso.
The Orchive : Data mining a massive bioacoustic archive
Jul 02, 2013
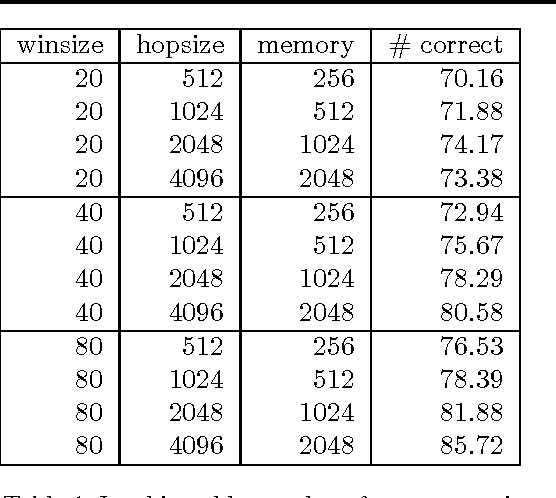
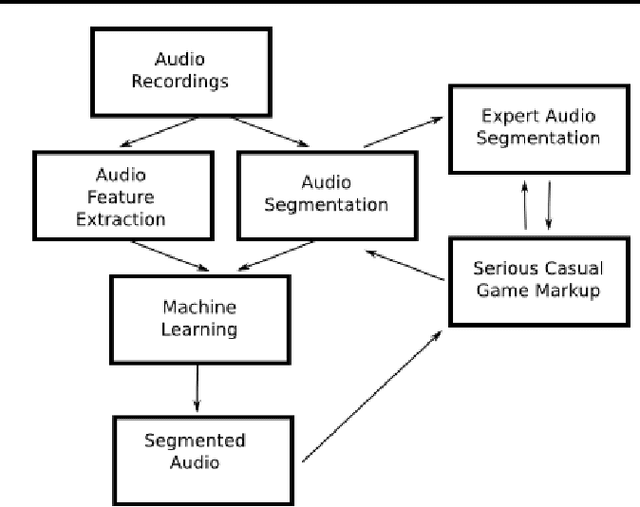
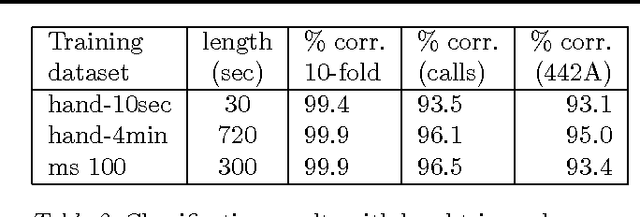
The Orchive is a large collection of over 20,000 hours of audio recordings from the OrcaLab research facility located off the northern tip of Vancouver Island. It contains recorded orca vocalizations from the 1980 to the present time and is one of the largest resources of bioacoustic data in the world. We have developed a web-based interface that allows researchers to listen to these recordings, view waveform and spectral representations of the audio, label clips with annotations, and view the results of machine learning classifiers based on automatic audio features extraction. In this paper we describe such classifiers that discriminate between background noise, orca calls, and the voice notes that are present in most of the tapes. Furthermore we show classification results for individual calls based on a previously existing orca call catalog. We have also experimentally investigated the scalability of classifiers over the entire Orchive.