 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Neural Synthesizers for Low Latency Interaction
Mar 14, 2025Neural Audio Synthesis (NAS) models offer interactive musical control over high-quality, expressive audio generators. While these models can operate in real-time, they often suffer from high latency, making them unsuitable for intimate musical interaction. The impact of architectural choices in deep learning models on audio latency remains largely unexplored in the NAS literature. In this work, we investigate the sources of latency and jitter typically found in interactive NAS models. We then apply this analysis to the task of timbre transfer using RAVE, a convolutional variational autoencoder for audio waveforms introduced by Caillon et al. in 2021. Finally, we present an iterative design approach for optimizing latency. This culminates with a model we call BRAVE (Bravely Realtime Audio Variational autoEncoder), which is low-latency and exhibits better pitch and loudness replication while showing timbre modification capabilities similar to RAVE. We implement it in a specialized inference framework for low-latency, real-time inference and present a proof-of-concept audio plugin compatible with audio signals from musical instruments. We expect the challenges and guidelines described in this document to support NAS researchers in designing models for low-latency inference from the ground up, enriching the landscape of possibilities for musicians.
Real-time Timbre Remapping with Differentiable DSP
Jul 05, 2024



Timbre is a primary mode of expression in diverse musical contexts. However, prevalent audio-driven synthesis methods predominantly rely on pitch and loudness envelopes, effectively flattening timbral expression from the input. Our approach draws on the concept of timbre analogies and investigates how timbral expression from an input signal can be mapped onto controls for a synthesizer. Leveraging differentiable digital signal processing, our method facilitates direct optimization of synthesizer parameters through a novel feature difference loss. This loss function, designed to learn relative timbral differences between musical events, prioritizes the subtleties of graded timbre modulations within phrases, allowing for meaningful translations in a timbre space. Using snare drum performances as a case study, where timbral expression is central, we demonstrate real-time timbre remapping from acoustic snare drums to a differentiable synthesizer modeled after the Roland TR-808.
Differentiable Modelling of Percussive Audio with Transient and Spectral Synthesis
Sep 13, 2023



Differentiable digital signal processing (DDSP) techniques, including methods for audio synthesis, have gained attention in recent years and lend themselves to interpretability in the parameter space. However, current differentiable synthesis methods have not explicitly sought to model the transient portion of signals, which is important for percussive sounds. In this work, we present a unified synthesis framework aiming to address transient generation and percussive synthesis within a DDSP framework. To this end, we propose a model for percussive synthesis that builds on sinusoidal modeling synthesis and incorporates a modulated temporal convolutional network for transient generation. We use a modified sinusoidal peak picking algorithm to generate time-varying non-harmonic sinusoids and pair it with differentiable noise and transient encoders that are jointly trained to reconstruct drumset sounds. We compute a set of reconstruction metrics using a large dataset of acoustic and electronic percussion samples that show that our method leads to improved onset signal reconstruction for membranophone percussion instruments.
A Review of Differentiable Digital Signal Processing for Music & Speech Synthesis
Aug 29, 2023The term "differentiable digital signal processing" describes a family of techniques in which loss function gradients are backpropagated through digital signal processors, facilitating their integration into neural networks. This article surveys the literature on differentiable audio signal processing, focusing on its use in music & speech synthesis. We catalogue applications to tasks including music performance rendering, sound matching, and voice transformation, discussing the motivations for and implications of the use of this methodology. This is accompanied by an overview of digital signal processing operations that have been implemented differentiably. Finally, we highlight open challenges, including optimisation pathologies, robustness to real-world conditions, and design trade-offs, and discuss directions for future research.
HEAR 2021: Holistic Evaluation of Audio Representations
Mar 26, 2022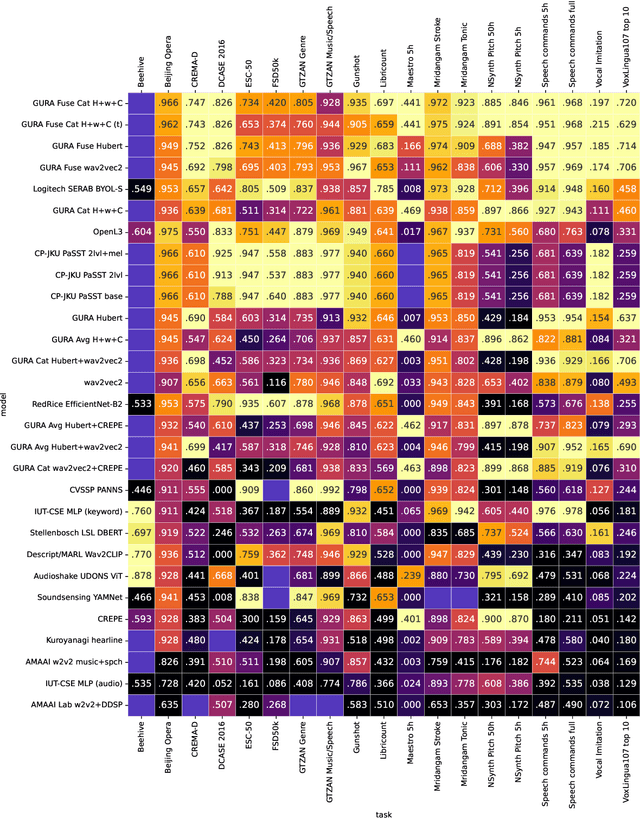
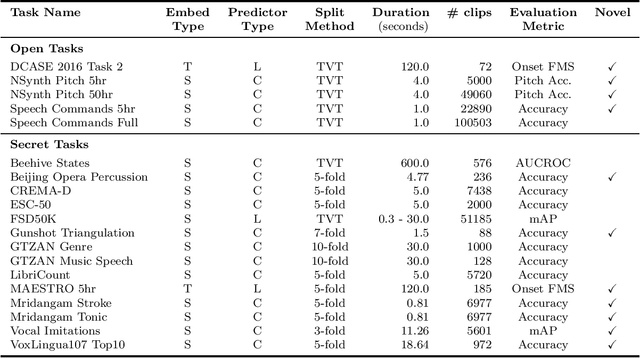

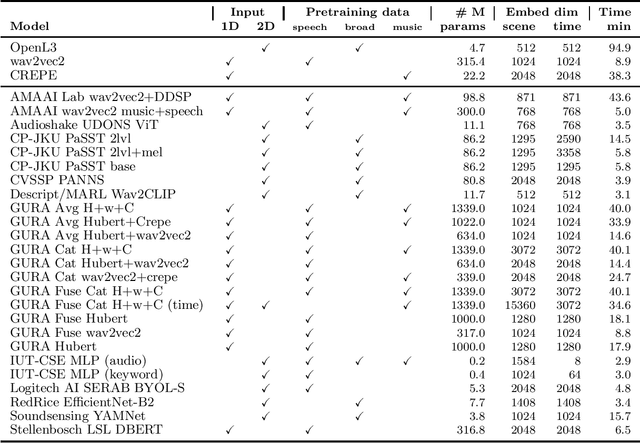
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
One Billion Audio Sounds from GPU-enabled Modular Synthesis
Apr 27, 2021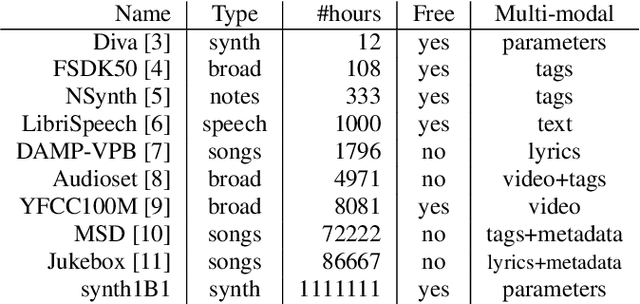
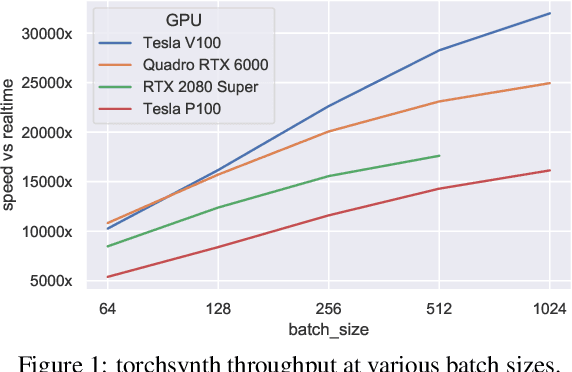
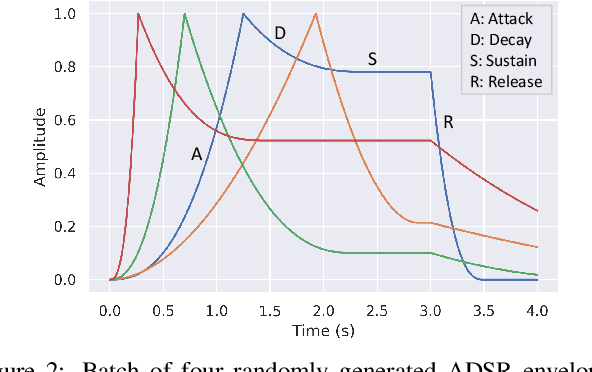
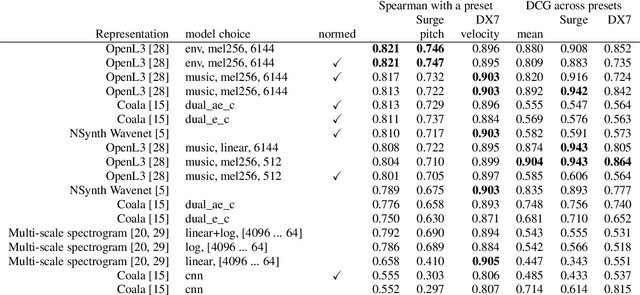
We release synth1B1, a multi-modal audio corpus consisting of 1 billion 4-second synthesized sounds, which is 100x larger than any audio dataset in the literature. Each sound is paired with the corresponding latent parameters used to generate it. synth1B1 samples are deterministically generated on-the-fly 16200x faster than real-time (714MHz) on a single GPU using torchsynth (https://github.com/torchsynth/torchsynth), an open-source modular synthesizer we release. Additionally, we release two new audio datasets: FM synth timbre (https://zenodo.org/record/4677102) and subtractive synth pitch (https://zenodo.org/record/4677097). Using these datasets, we demonstrate new rank-based synthesizer-motivated evaluation criteria for existing audio representations. Finally, we propose novel approaches to synthesizer hyperparameter optimization, and demonstrate how perceptually-correlated auditory distances could enable new applications in synthesizer design.