 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEAR 2021: Holistic Evaluation of Audio Representations
Mar 26, 2022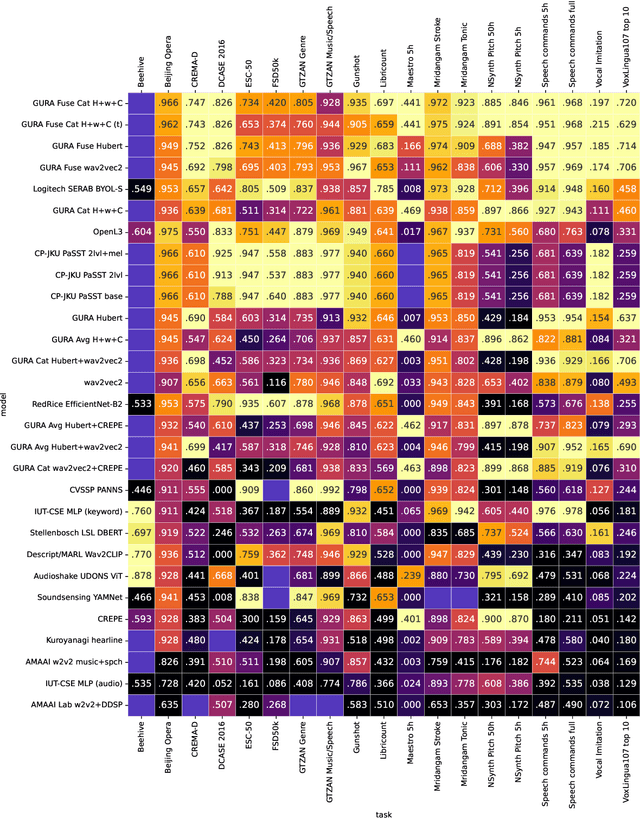
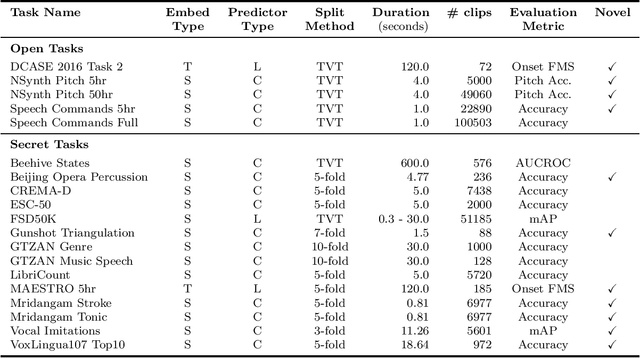

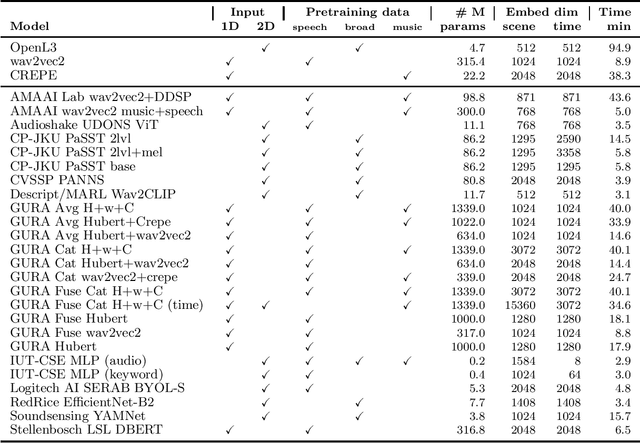
What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR 2021 NeurIPS challenge is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR 2021 evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.
One Billion Audio Sounds from GPU-enabled Modular Synthesis
Apr 27, 2021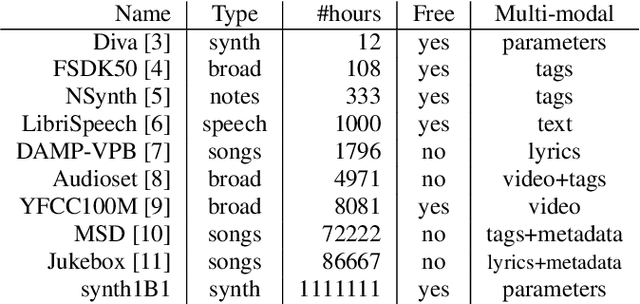
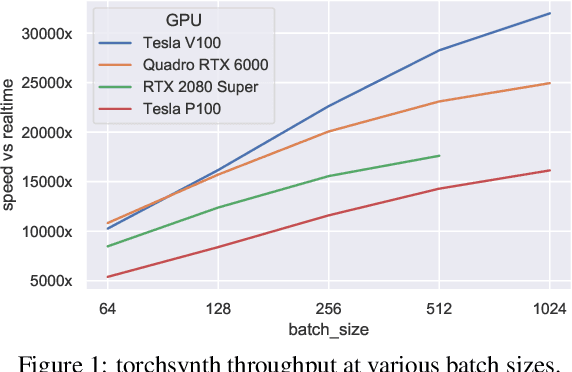
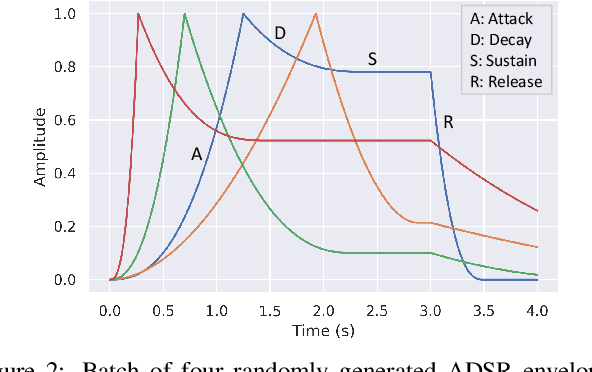
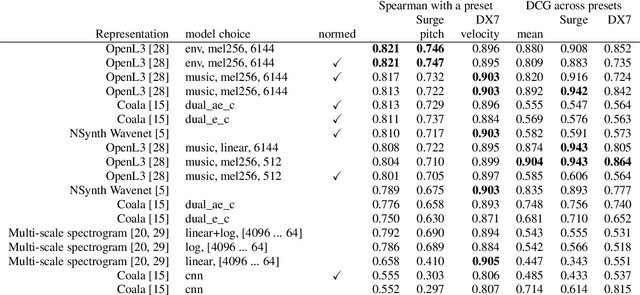
We release synth1B1, a multi-modal audio corpus consisting of 1 billion 4-second synthesized sounds, which is 100x larger than any audio dataset in the literature. Each sound is paired with the corresponding latent parameters used to generate it. synth1B1 samples are deterministically generated on-the-fly 16200x faster than real-time (714MHz) on a single GPU using torchsynth (https://github.com/torchsynth/torchsynth), an open-source modular synthesizer we release. Additionally, we release two new audio datasets: FM synth timbre (https://zenodo.org/record/4677102) and subtractive synth pitch (https://zenodo.org/record/4677097). Using these datasets, we demonstrate new rank-based synthesizer-motivated evaluation criteria for existing audio representations. Finally, we propose novel approaches to synthesizer hyperparameter optimization, and demonstrate how perceptually-correlated auditory distances could enable new applications in synthesizer design.