 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAggregating Gradients in Encoded Domain for Federated Learning
Jun 09, 2022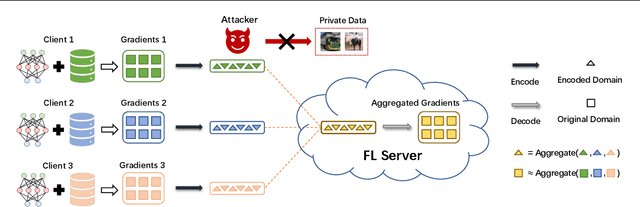
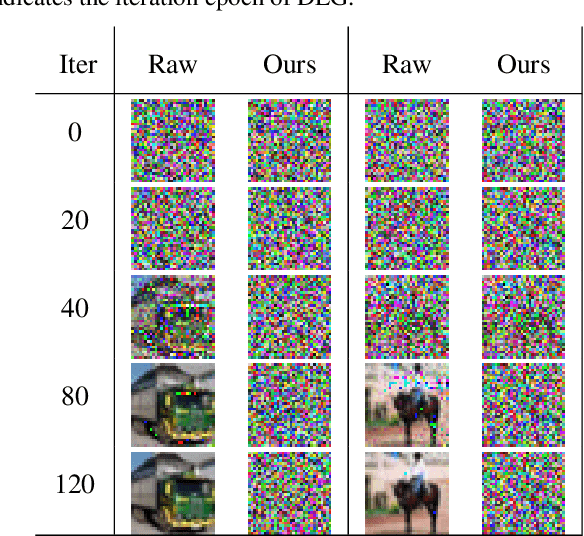

Malicious attackers and an honest-but-curious server can steal private client data from uploaded gradients in federated learning. Although current protection methods (e.g., additive homomorphic cryptosystem) can guarantee the security of the federated learning system, they bring additional computation and communication costs. To mitigate the cost, we propose the \texttt{FedAGE} framework, which enables the server to aggregate gradients in an encoded domain without accessing raw gradients of any single client. Thus, \texttt{FedAGE} can prevent the curious server from gradient stealing while maintaining the same prediction performance without additional communication costs. Furthermore, we theoretically prove that the proposed encoding-decoding framework is a Gaussian mechanism for differential privacy. Finally, we evaluate \texttt{FedAGE} under several federated settings, and the results have demonstrated the efficacy of the proposed framework.
A Unified Weight Initialization Paradigm for Tensorial Convolutional Neural Networks
May 28, 2022
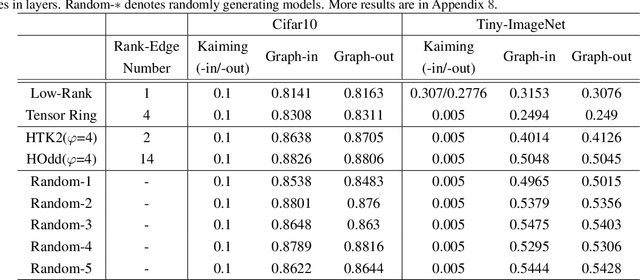
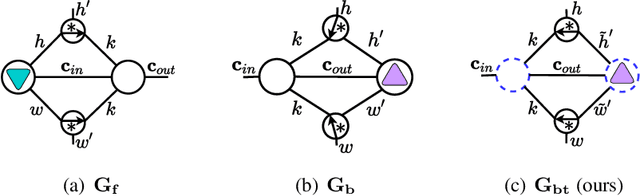

Tensorial Convolutional Neural Networks (TCNNs) have attracted much research attention for their power in reducing model parameters or enhancing the generalization ability. However, exploration of TCNNs is hindered even from weight initialization methods. To be specific, general initialization methods, such as Xavier or Kaiming initialization, usually fail to generate appropriate weights for TCNNs. Meanwhile, although there are ad-hoc approaches for specific architectures (e.g., Tensor Ring Nets), they are not applicable to TCNNs with other tensor decomposition methods (e.g., CP or Tucker decomposition). To address this problem, we propose a universal weight initialization paradigm, which generalizes Xavier and Kaiming methods and can be widely applicable to arbitrary TCNNs. Specifically, we first present the Reproducing Transformation to convert the backward process in TCNNs to an equivalent convolution process. Then, based on the convolution operators in the forward and backward processes, we build a unified paradigm to control the variance of features and gradients in TCNNs. Thus, we can derive fan-in and fan-out initialization for various TCNNs. We demonstrate that our paradigm can stabilize the training of TCNNs, leading to faster convergence and better results.
Contrastive Multi-view Hyperbolic Hierarchical Clustering
May 05, 2022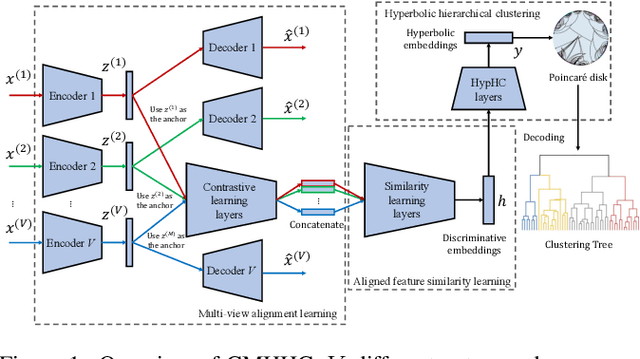

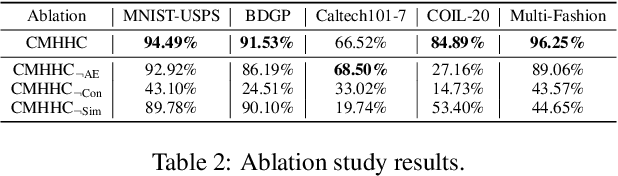
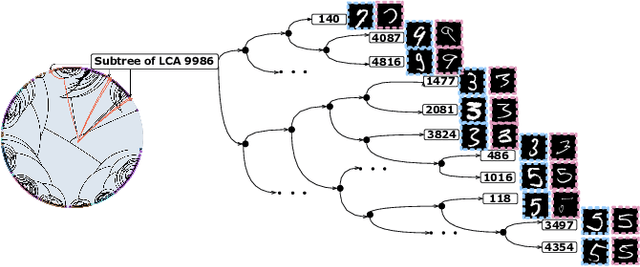
Hierarchical clustering recursively partitions data at an increasingly finer granularity. In real-world applications, multi-view data have become increasingly important. This raises a less investigated problem, i.e., multi-view hierarchical clustering, to better understand the hierarchical structure of multi-view data. To this end, we propose a novel neural network-based model, namely Contrastive Multi-view Hyperbolic Hierarchical Clustering (CMHHC). It consists of three components, i.e., multi-view alignment learning, aligned feature similarity learning, and continuous hyperbolic hierarchical clustering. First, we align sample-level representations across multiple views in a contrastive way to capture the view-invariance information. Next, we utilize both the manifold and Euclidean similarities to improve the metric property. Then, we embed the representations into a hyperbolic space and optimize the hyperbolic embeddings via a continuous relaxation of hierarchical clustering loss. Finally, a binary clustering tree is decoded from optimized hyperbolic embeddings. Experimental results on five real-world datasets demonstrate the effectiveness of the proposed method and its components.
MarkBERT: Marking Word Boundaries Improves Chinese BERT
Mar 12, 2022
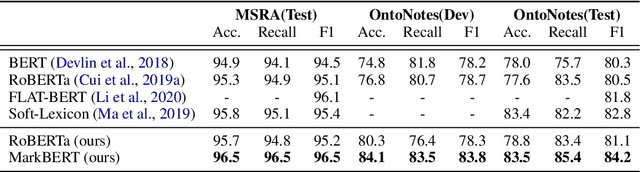
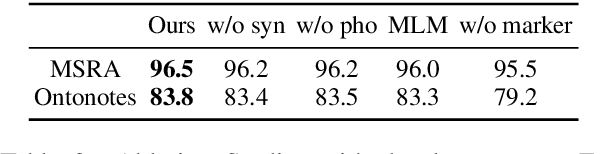
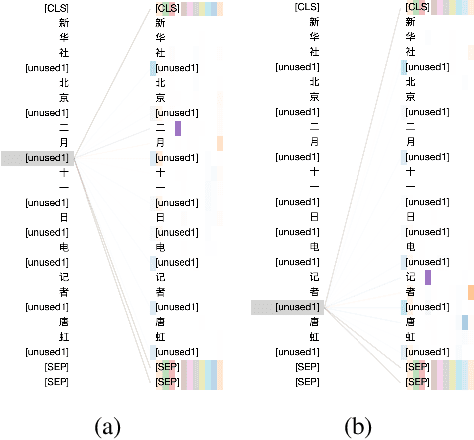
We present a Chinese BERT model dubbed MarkBERT that uses word information. Existing word-based BERT models regard words as basic units, however, due to the vocabulary limit of BERT, they only cover high-frequency words and fall back to character level when encountering out-of-vocabulary (OOV) words. Different from existing works, MarkBERT keeps the vocabulary being Chinese characters and inserts boundary markers between contiguous words. Such design enables the model to handle any words in the same way, no matter they are OOV words or not. Besides, our model has two additional benefits: first, it is convenient to add word-level learning objectives over markers, which is complementary to traditional character and sentence-level pre-training tasks; second, it can easily incorporate richer semantics such as POS tags of words by replacing generic markers with POS tag-specific markers. MarkBERT pushes the state-of-the-art of Chinese named entity recognition from 95.4\% to 96.5\% on the MSRA dataset and from 82.8\% to 84.2\% on the OntoNotes dataset, respectively. Compared to previous word-based BERT models, MarkBERT achieves better accuracy on text classification, keyword recognition, and semantic similarity tasks.
Semantically Proportional Patchmix for Few-Shot Learning
Feb 17, 2022
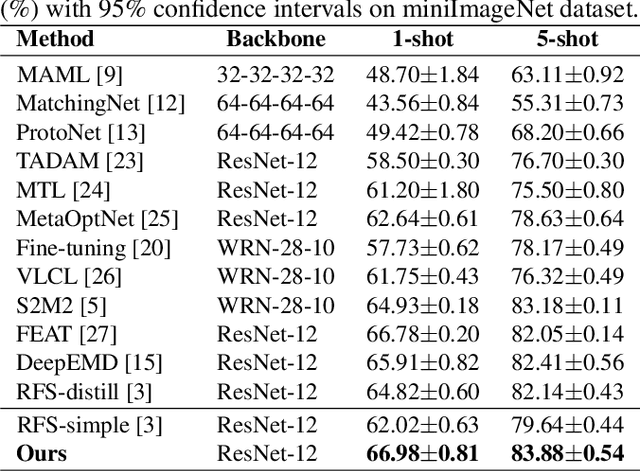

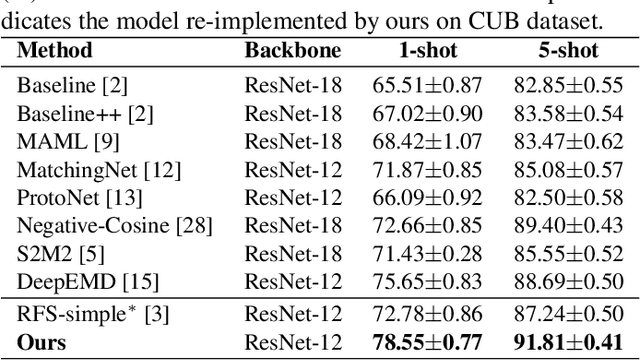
Few-shot learning aims to classify unseen classes with only a limited number of labeled data. Recent works have demonstrated that training models with a simple transfer learning strategy can achieve competitive results in few-shot classification. Although excelling at distinguishing training data, these models are not well generalized to unseen data, probably due to insufficient feature representations on evaluation. To tackle this issue, we propose Semantically Proportional Patchmix (SePPMix), in which patches are cut and pasted among training images and the ground truth labels are mixed proportionally to the semantic information of the patches. In this way, we can improve the generalization ability of the model by regional dropout effect without introducing severe label noise. To learn more robust representations of data, we further take rotate transformation on the mixed images and predict rotations as a rule-based regularizer. Extensive experiments on prevalent few-shot benchmarks have shown the effectiveness of our proposed method.
Source Code Summarization with Structural Relative Position Guided Transformer
Feb 14, 2022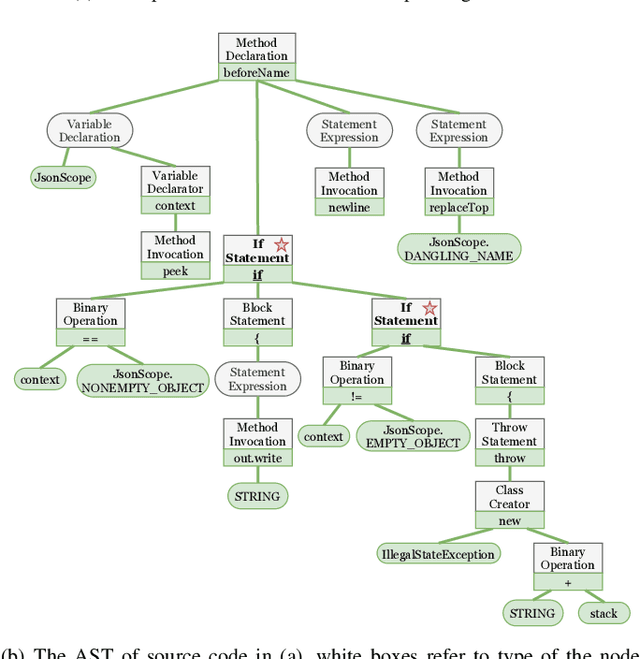
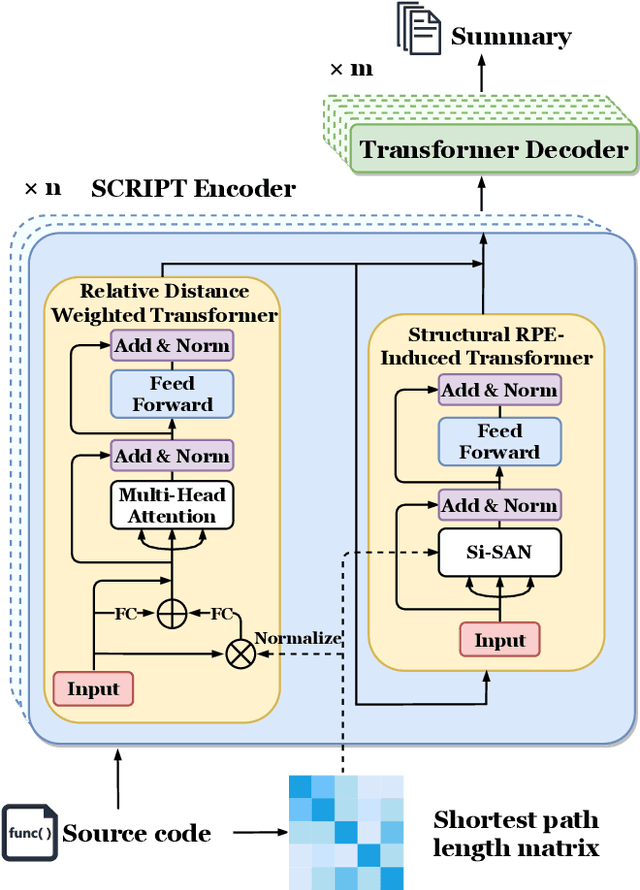
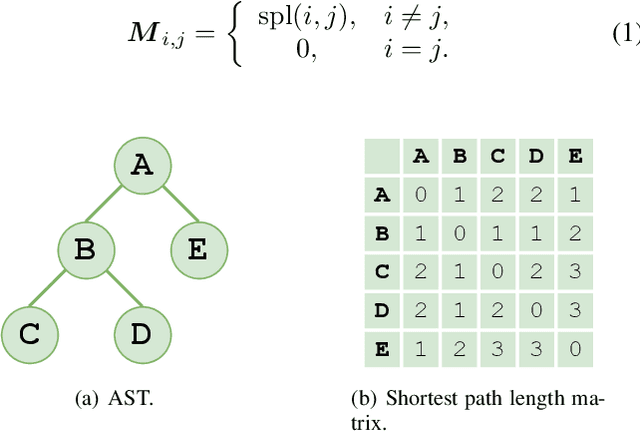
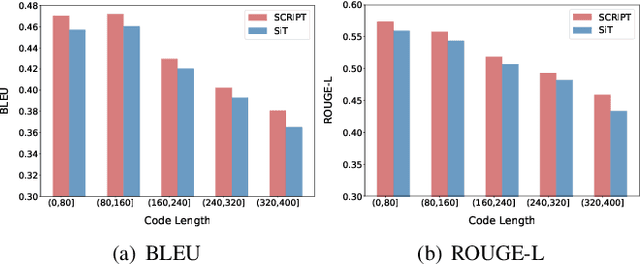
Source code summarization aims at generating concise and clear natural language descriptions for programming languages. Well-written code summaries are beneficial for programmers to participate in the software development and maintenance process. To learn the semantic representations of source code, recent efforts focus on incorporating the syntax structure of code into neural networks such as Transformer. Such Transformer-based approaches can better capture the long-range dependencies than other neural networks including Recurrent Neural Networks (RNNs), however, most of them do not consider the structural relative correlations between tokens, e.g., relative positions in Abstract Syntax Trees (ASTs), which is beneficial for code semantics learning. To model the structural dependency, we propose a Structural Relative Position guided Transformer, named SCRIPT. SCRIPT first obtains the structural relative positions between tokens via parsing the ASTs of source code, and then passes them into two types of Transformer encoders. One Transformer directly adjusts the input according to the structural relative distance; and the other Transformer encodes the structural relative positions during computing the self-attention scores. Finally, we stack these two types of Transformer encoders to learn representations of source code. Experimental results show that the proposed SCRIPT outperforms the state-of-the-art methods by at least 1.6%, 1.4% and 2.8% with respect to BLEU, ROUGE-L and METEOR on benchmark datasets, respectively. We further show that how the proposed SCRIPT captures the structural relative dependencies.
Data Heterogeneity-Robust Federated Learning via Group Client Selection in Industrial IoT
Feb 03, 2022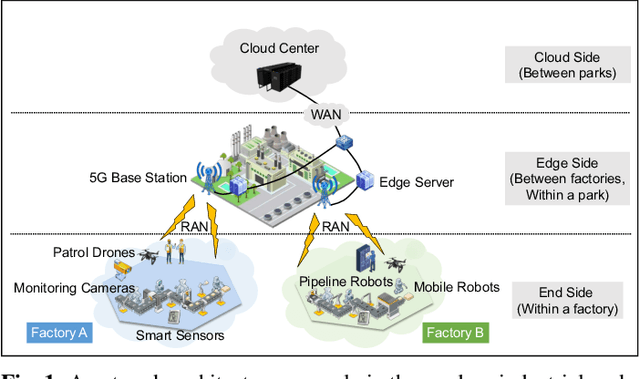
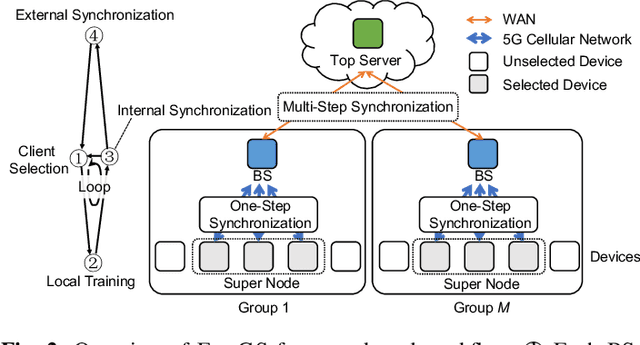


Nowadays, the industrial Internet of Things (IIoT) has played an integral role in Industry 4.0 and produced massive amounts of data for industrial intelligence. These data locate on decentralized devices in modern factories. To protect the confidentiality of industrial data, federated learning (FL) was introduced to collaboratively train shared machine learning models. However, the local data collected by different devices skew in class distribution and degrade industrial FL performance. This challenge has been widely studied at the mobile edge, but they ignored the rapidly changing streaming data and clustering nature of factory devices, and more seriously, they may threaten data security. In this paper, we propose FedGS, which is a hierarchical cloud-edge-end FL framework for 5G empowered industries, to improve industrial FL performance on non-i.i.d. data. Taking advantage of naturally clustered factory devices, FedGS uses a gradient-based binary permutation algorithm (GBP-CS) to select a subset of devices within each factory and build homogeneous super nodes participating in FL training. Then, we propose a compound-step synchronization protocol to coordinate the training process within and among these super nodes, which shows great robustness against data heterogeneity. The proposed methods are time-efficient and can adapt to dynamic environments, without exposing confidential industrial data in risky manipulation. We prove that FedGS has better convergence performance than FedAvg and give a relaxed condition under which FedGS is more communication-efficient. Extensive experiments show that FedGS improves accuracy by 3.5% and reduces training rounds by 59% on average, confirming its superior effectiveness and efficiency on non-i.i.d. data.
Heterogeneous Federated Learning via Grouped Sequential-to-Parallel Training
Jan 31, 2022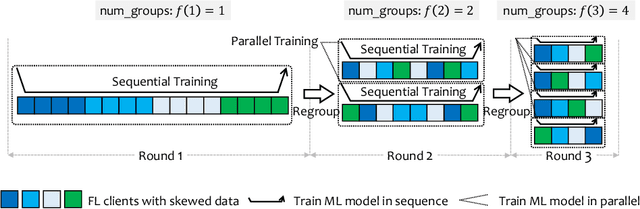
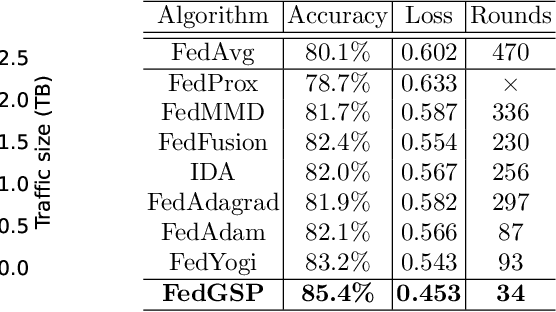
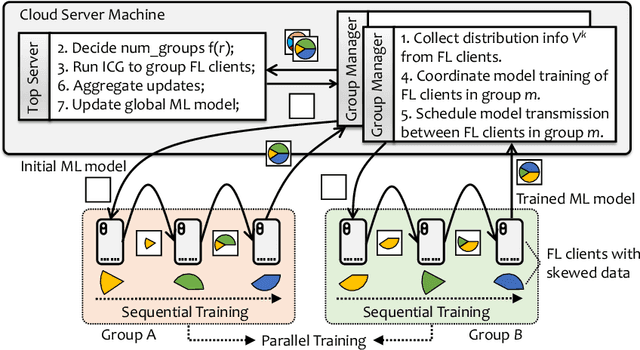
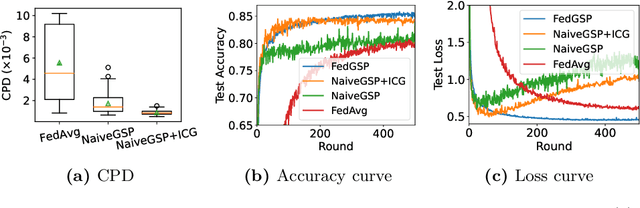
Federated learning (FL) is a rapidly growing privacy-preserving collaborative machine learning paradigm. In practical FL applications, local data from each data silo reflect local usage patterns. Therefore, there exists heterogeneity of data distributions among data owners (a.k.a. FL clients). If not handled properly, this can lead to model performance degradation. This challenge has inspired the research field of heterogeneous federated learning, which currently remains open. In this paper, we propose a data heterogeneity-robust FL approach, FedGSP, to address this challenge by leveraging on a novel concept of dynamic Sequential-to-Parallel (STP) collaborative training. FedGSP assigns FL clients to homogeneous groups to minimize the overall distribution divergence among groups, and increases the degree of parallelism by reassigning more groups in each round. It is also incorporated with a novel Inter-Cluster Grouping (ICG) algorithm to assist in group assignment, which uses the centroid equivalence theorem to simplify the NP-hard grouping problem to make it solvable. Extensive experiments have been conducted on the non-i.i.d. FEMNIST dataset. The results show that FedGSP improves the accuracy by 3.7% on average compared with seven state-of-the-art approaches, and reduces the training time and communication overhead by more than 90%.
Self-Paced Deep Regression Forests with Consideration on Ranking Fairness
Dec 28, 2021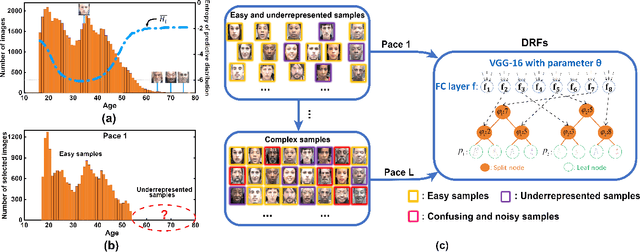
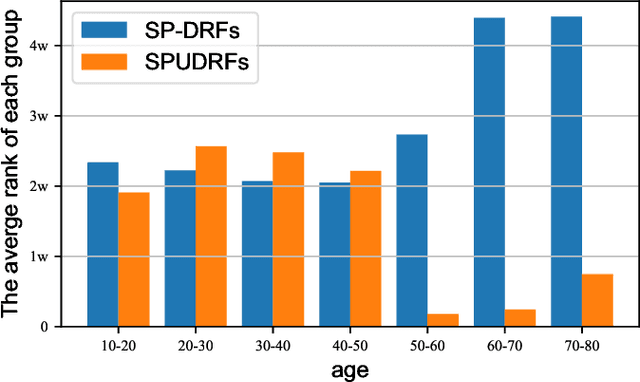
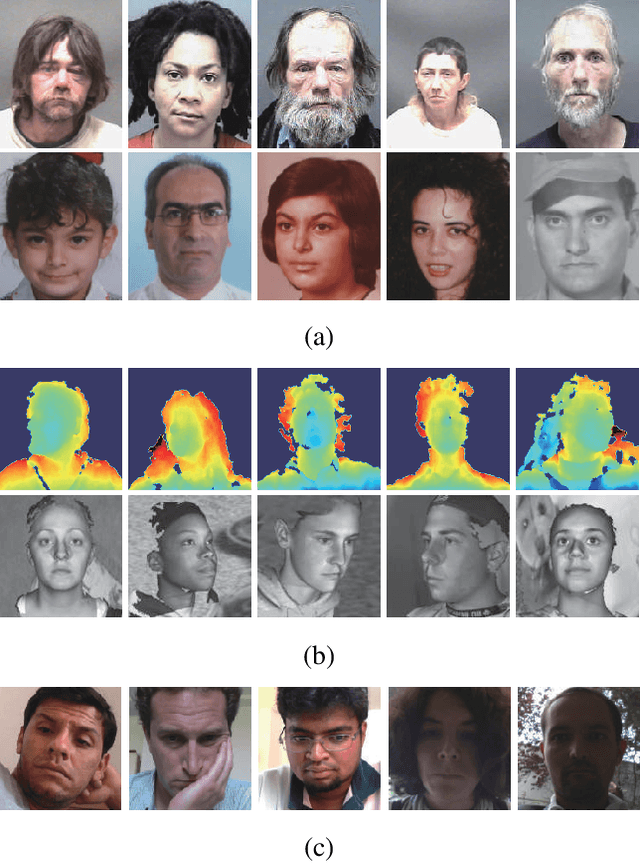
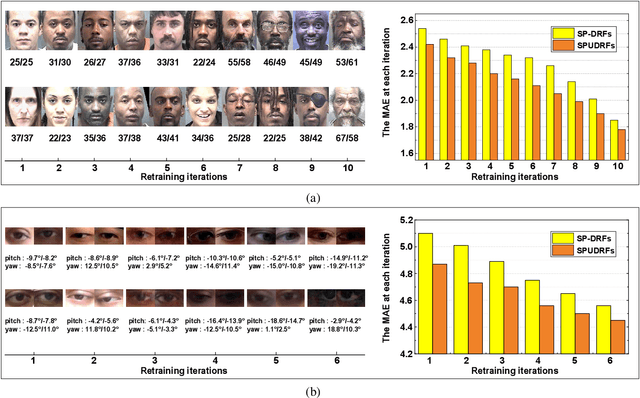
Deep discriminative models (DDMs), such as deep regression forests, deep neural decision forests, have been extensively studied recently to solve problems like facial age estimation, head pose estimation, gaze estimation and so forth. Such problems are challenging in part because a large amount of effective training data without noise and bias is often not available. While some progress has been achieved through learning more discriminative features, or reweighting samples, we argue what is more desirable is to learn gradually to discriminate like human beings. Then, we resort to self-paced learning (SPL). But a natural question arises: can self-paced regime lead DDMs to achieve more robust and less biased solutions? A serious problem with SPL, which is firstly discussed by this work, is it tends to aggravate the bias of solutions, especially for obvious imbalanced data. To this end, this paper proposes a new self-paced paradigm for deep discriminative model, which distinguishes noisy and underrepresented examples according to the output likelihood and entropy associated with each example, and tackle the fundamental ranking problem in SPL from a new perspective: fairness. This paradigm is fundamental, and could be easily combined with a variety of DDMs. Extensive experiments on three computer vision tasks, such as facial age estimation, head pose estimation and gaze estimation, demonstrate the efficacy of our paradigm. To the best of our knowledge, our work is the first paper in the literature of SPL that considers ranking fairness for self-paced regime construction.
Exploring Category-correlated Feature for Few-shot Image Classification
Dec 14, 2021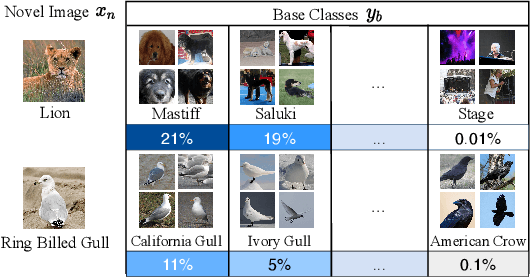
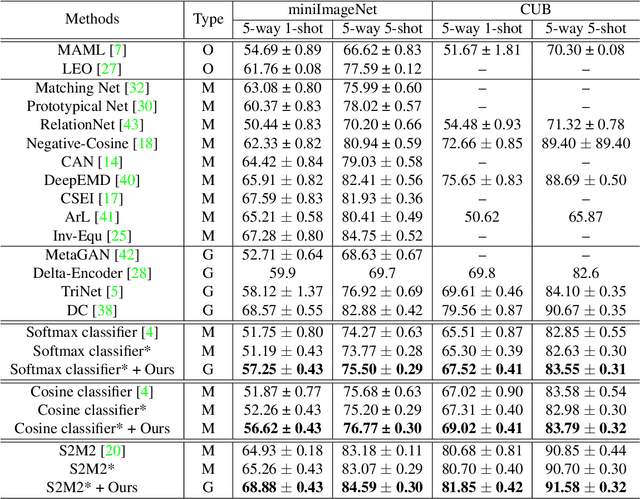

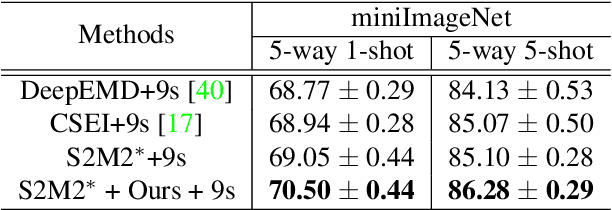
Few-shot classification aims to adapt classifiers to novel classes with a few training samples. However, the insufficiency of training data may cause a biased estimation of feature distribution in a certain class. To alleviate this problem, we present a simple yet effective feature rectification method by exploring the category correlation between novel and base classes as the prior knowledge. We explicitly capture such correlation by mapping features into a latent vector with dimension matching the number of base classes, treating it as the logarithm probability of the feature over base classes. Based on this latent vector, the rectified feature is directly constructed by a decoder, which we expect maintaining category-related information while removing other stochastic factors, and consequently being closer to its class centroid. Furthermore, by changing the temperature value in softmax, we can re-balance the feature rectification and reconstruction for better performance. Our method is generic, flexible and agnostic to any feature extractor and classifier, readily to be embedded into existing FSL approaches. Experiments verify that our method is capable of rectifying biased features, especially when the feature is far from the class centroid. The proposed approach consistently obtains considerable performance gains on three widely used benchmarks, evaluated with different backbones and classifiers. The code will be made public.