 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring Monitorability
Dec 20, 2025



Observability into the decision making of modern AI systems may be required to safely deploy increasingly capable agents. Monitoring the chain-of-thought (CoT) of today's reasoning models has proven effective for detecting misbehavior. However, this "monitorability" may be fragile under different training procedures, data sources, or even continued system scaling. To measure and track monitorability, we propose three evaluation archetypes (intervention, process, and outcome-property) and a new monitorability metric, and introduce a broad evaluation suite. We demonstrate that these evaluations can catch simple model organisms trained to have obfuscated CoTs, and that CoT monitoring is more effective than action-only monitoring in practical settings. We compare the monitorability of various frontier models and find that most models are fairly, but not perfectly, monitorable. We also evaluate how monitorability scales with inference-time compute, reinforcement learning optimization, and pre-training model size. We find that longer CoTs are generally more monitorable and that RL optimization does not materially decrease monitorability even at the current frontier scale. Notably, we find that for a model at a low reasoning effort, we could instead deploy a smaller model at a higher reasoning effort (thereby matching capabilities) and obtain a higher monitorability, albeit at a higher overall inference compute cost. We further investigate agent-monitor scaling trends and find that scaling a weak monitor's test-time compute when monitoring a strong agent increases monitorability. Giving the weak monitor access to CoT not only improves monitorability, but it steepens the monitor's test-time compute to monitorability scaling trend. Finally, we show we can improve monitorability by asking models follow-up questions and giving their follow-up CoT to the monitor.
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation
Mar 14, 2025Mitigating reward hacking--where AI systems misbehave due to flaws or misspecifications in their learning objectives--remains a key challenge in constructing capable and aligned models. We show that we can monitor a frontier reasoning model, such as OpenAI o3-mini, for reward hacking in agentic coding environments by using another LLM that observes the model's chain-of-thought (CoT) reasoning. CoT monitoring can be far more effective than monitoring agent actions and outputs alone, and we further found that a LLM weaker than o3-mini, namely GPT-4o, can effectively monitor a stronger model. Because CoT monitors can be effective at detecting exploits, it is natural to ask whether those exploits can be suppressed by incorporating a CoT monitor directly into the agent's training objective. While we show that integrating CoT monitors into the reinforcement learning reward can indeed produce more capable and more aligned agents in the low optimization regime, we find that with too much optimization, agents learn obfuscated reward hacking, hiding their intent within the CoT while still exhibiting a significant rate of reward hacking. Because it is difficult to tell when CoTs have become obfuscated, it may be necessary to pay a monitorability tax by not applying strong optimization pressures directly to the chain-of-thought, ensuring that CoTs remain monitorable and useful for detecting misaligned behavior.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
Video PreTraining : Learning to Act by Watching Unlabeled Online Videos
Jun 23, 2022

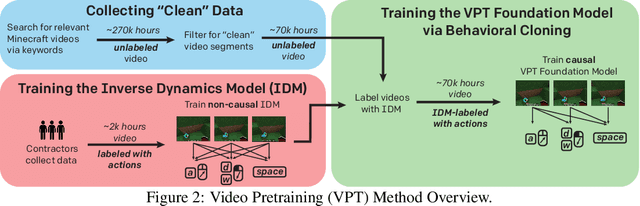
Pretraining on noisy, internet-scale datasets has been heavily studied as a technique for training models with broad, general capabilities for text, images, and other modalities. However, for many sequential decision domains such as robotics, video games, and computer use, publicly available data does not contain the labels required to train behavioral priors in the same way. We extend the internet-scale pretraining paradigm to sequential decision domains through semi-supervised imitation learning wherein agents learn to act by watching online unlabeled videos. Specifically, we show that with a small amount of labeled data we can train an inverse dynamics model accurate enough to label a huge unlabeled source of online data -- here, online videos of people playing Minecraft -- from which we can then train a general behavioral prior. Despite using the native human interface (mouse and keyboard at 20Hz), we show that this behavioral prior has nontrivial zero-shot capabilities and that it can be fine-tuned, with both imitation learning and reinforcement learning, to hard-exploration tasks that are impossible to learn from scratch via reinforcement learning. For many tasks our models exhibit human-level performance, and we are the first to report computer agents that can craft diamond tools, which can take proficient humans upwards of 20 minutes (24,000 environment actions) of gameplay to accomplish.
Multi-task curriculum learning in a complex, visual, hard-exploration domain: Minecraft
Jun 28, 2021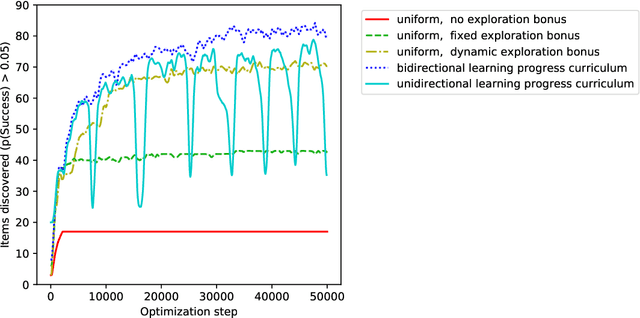
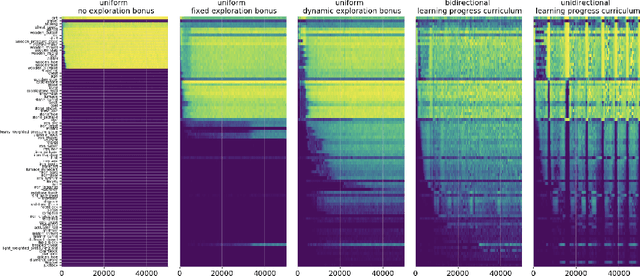
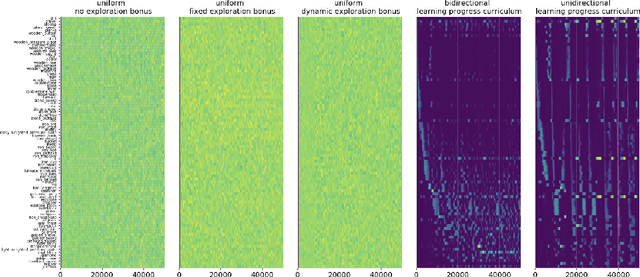
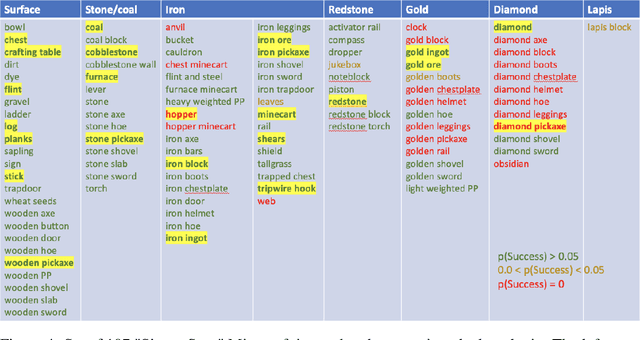
An important challenge in reinforcement learning is training agents that can solve a wide variety of tasks. If tasks depend on each other (e.g. needing to learn to walk before learning to run), curriculum learning can speed up learning by focusing on the next best task to learn. We explore curriculum learning in a complex, visual domain with many hard exploration challenges: Minecraft. We find that learning progress (defined as a change in success probability of a task) is a reliable measure of learnability for automatically constructing an effective curriculum. We introduce a learning-progress based curriculum and test it on a complex reinforcement learning problem (called "Simon Says") where an agent is instructed to obtain a desired goal item. Many of the required skills depend on each other. Experiments demonstrate that: (1) a within-episode exploration bonus for obtaining new items improves performance, (2) dynamically adjusting this bonus across training such that it only applies to items the agent cannot reliably obtain yet further increases performance, (3) the learning-progress based curriculum elegantly follows the learning curve of the agent, and (4) when the learning-progress based curriculum is combined with the dynamic exploration bonus it learns much more efficiently and obtains far higher performance than uniform baselines. These results suggest that combining intra-episode and across-training exploration bonuses with learning progress creates a promising method for automated curriculum generation, which may substantially increase our ability to train more capable, generally intelligent agents.
First return then explore
May 14, 2020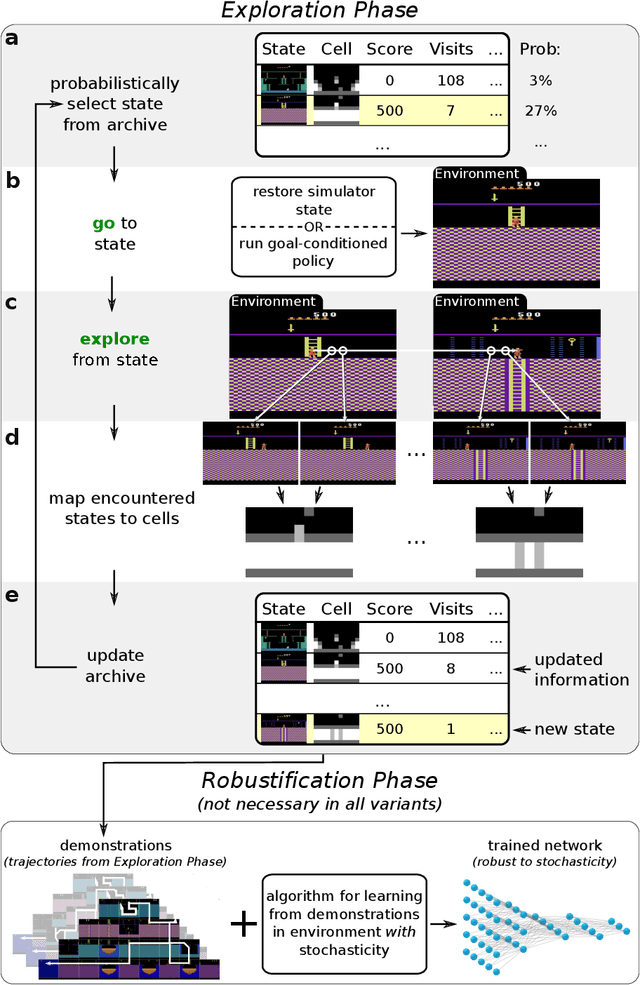
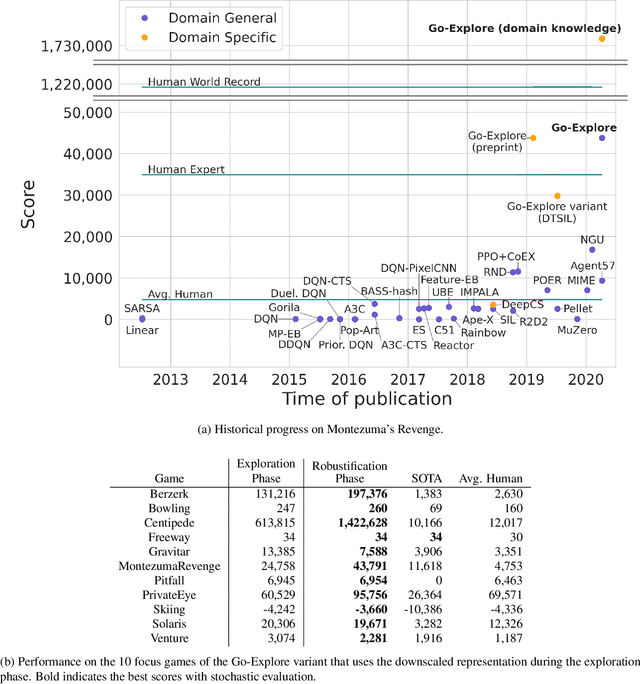
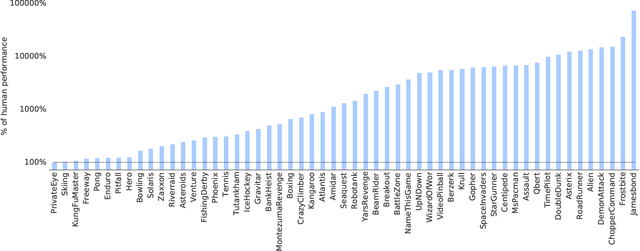
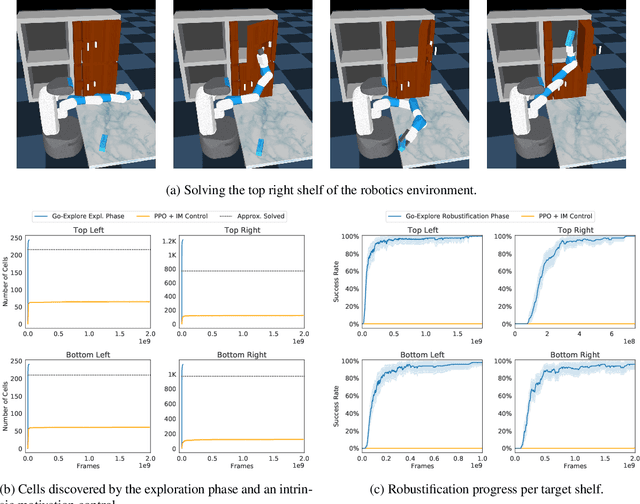
The promise of reinforcement learning is to solve complex sequential decision problems by specifying a high-level reward function only. However, RL algorithms struggle when, as is often the case, simple and intuitive rewards provide sparse and deceptive feedback. Avoiding these pitfalls requires thoroughly exploring the environment, but despite substantial investments by the community, creating algorithms that can do so remains one of the central challenges of the field. We hypothesize that the main impediment to effective exploration originates from algorithms forgetting how to reach previously visited states ("detachment") and from failing to first return to a state before exploring from it ("derailment"). We introduce Go-Explore, a family of algorithms that addresses these two challenges directly through the simple principles of explicitly remembering promising states and first returning to such states before exploring. Go-Explore solves all heretofore unsolved Atari games (those for which algorithms could not previously outperform humans when evaluated following current community standards) and surpasses the state of the art on all hard-exploration games, with orders of magnitude improvements on the grand challenges Montezuma's Revenge and Pitfall. We also demonstrate the practical potential of Go-Explore on a challenging and extremely sparse-reward robotics task. Additionally, we show that adding a goal-conditioned policy can further improve Go-Explore's exploration efficiency and enable it to handle stochasticity throughout training. The striking contrast between the substantial performance gains from Go-Explore and the simplicity of its mechanisms suggests that remembering promising states, returning to them, and exploring from them is a powerful and general approach to exploration, an insight that may prove critical to the creation of truly intelligent learning agents.
Scaling MAP-Elites to Deep Neuroevolution
Mar 03, 2020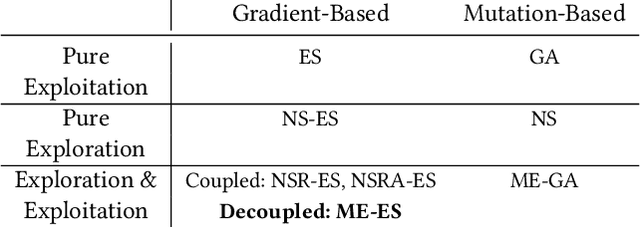
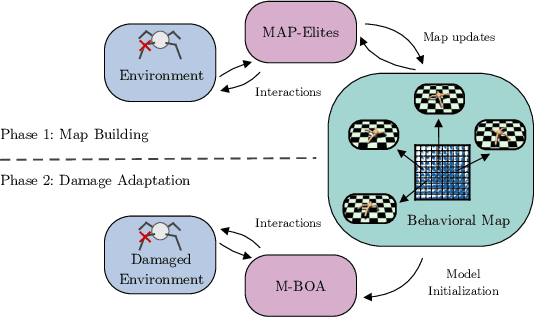
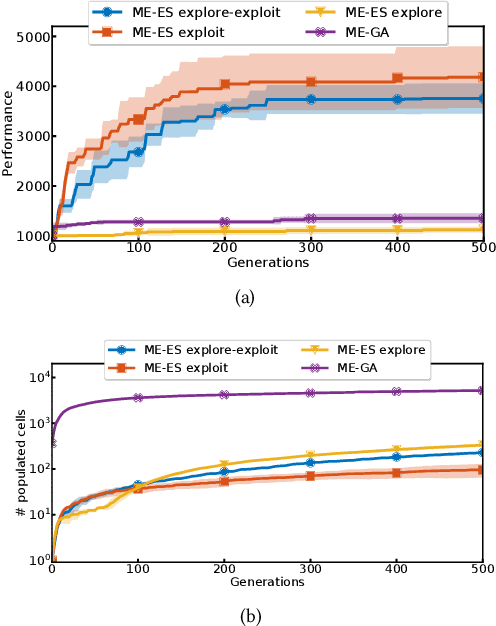

Quality-Diversity (QD) algorithms, and MAP-Elites (ME) in particular, have proven very useful for a broad range of applications including enabling real robots to recover quickly from joint damage, solving strongly deceptive maze tasks or evolving robot morphologies to discover new gaits. However, present implementations of MAP-Elites and other QD algorithms seem to be limited to low-dimensional controllers with far fewer parameters than modern deep neural network models. In this paper, we propose to leverage the efficiency of Evolution Strategies (ES) to scale MAP-Elites to high-dimensional controllers parameterized by large neural networks. We design and evaluate a new hybrid algorithm called MAP-Elites with Evolution Strategies (ME-ES) for post-damage recovery in a difficult high-dimensional control task where traditional ME fails. Additionally,we show that ME-ES performs efficient exploration, on par with state-of-the-art exploration algorithms in high-dimensional control tasks with strongly deceptive rewards.
Exploration Based Language Learning for Text-Based Games
Jan 24, 2020

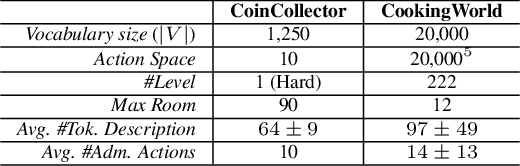
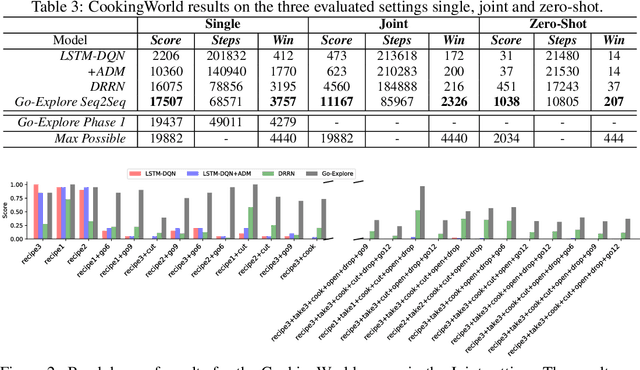
This work presents an exploration and imitation-learning-based agent capable of state-of-the-art performance in playing text-based computer games. Text-based computer games describe their world to the player through natural language and expect the player to interact with the game using text. These games are of interest as they can be seen as a testbed for language understanding, problem-solving, and language generation by artificial agents. Moreover, they provide a learning environment in which these skills can be acquired through interactions with an environment rather than using fixed corpora. One aspect that makes these games particularly challenging for learning agents is the combinatorially large action space. Existing methods for solving text-based games are limited to games that are either very simple or have an action space restricted to a predetermined set of admissible actions. In this work, we propose to use the exploration approach of Go-Explore for solving text-based games. More specifically, in an initial exploration phase, we first extract trajectories with high rewards, after which we train a policy to solve the game by imitating these trajectories. Our experiments show that this approach outperforms existing solutions in solving text-based games, and it is more sample efficient in terms of the number of interactions with the environment. Moreover, we show that the learned policy can generalize better than existing solutions to unseen games without using any restriction on the action space.
Guiding Neuroevolution with Structural Objectives
Feb 13, 2019The structure and performance of neural networks are intimately connected, and by use of evolutionary algorithms, neural network structures optimally adapted to a given task can be explored. Guiding such neuroevolution with additional objectives related to network structure has been shown to improve performance in some cases, especially when modular neural networks are beneficial. However, apart from objectives aiming to make networks more modular, such structural objectives have not been widely explored. We propose two new structural objectives and test their ability to guide evolving neural networks on two problems which can benefit from decomposition into subtasks. The first structural objective guides evolution to align neural networks with a user-recommended decomposition pattern. Intuitively, this should be a powerful guiding target for problems where human users can easily identify a structure. The second structural objective guides evolution towards a population with a high diversity in decomposition patterns. This results in exploration of many different ways to decompose a problem, allowing evolution to find good decompositions faster. Tests on our target problems reveal that both methods perform well on a problem with a very clear and decomposable structure. However, on a problem where the optimal decomposition is less obvious, the structural diversity objective is found to outcompete other structural objectives -- and this technique can even increase performance on problems without any decomposable structure at all.